本文主要是介绍(表征学习论文阅读)A Simple Framework for Contrastive Learning of Visual Representations,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607.
1. 前言
本文作者为了了解对比学习是如何学习到有效的表征,对本文所提出的三大组件进行了全面的研究:
- 各种数据增强手段的组合在表征学习中起到了重要作用;
- 在表征和对比损失之间引入非线性变换能够有效提高表征质量;
- 对比学习相较于监督学习需要更大的batch size和更多的训练步数。
在没有人类标注或者监督的情况下学习数据的有效表征是一个长期存在的难题,目前的主要工作可以分为两类:
- 基于生成模型的方法
例如VQ-VAE,MAE,BERT - 基于判别模型的方法
例如MoCo,CLIP
2. 方法
本文提出了一个框架SimCLR,通过最大化同一数据的不同数据增强处理后的两个视角之间的相似度来学习有效表征。
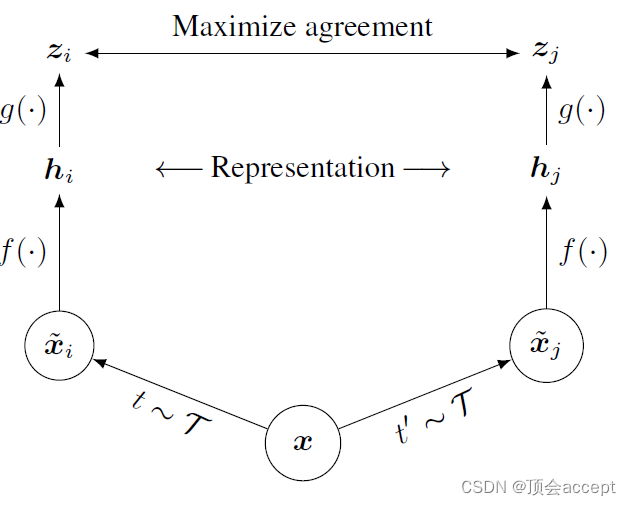
- 如图所示,本文首先将数据 x x x进行两个不同的增强,这里作者使用了三种简单的数据增强方法:随机裁剪后再调整到原始大小、随机颜色失真、高斯模糊。
- f ( ∙ ) f(\bullet) f(∙)代表编码器,这里作者使用的是同一个编码器来对两个视角数据进行编码
- 最后编码器输出的结果通过非线性变换 g ( ∙ ) g(\bullet) g(∙)得到 z i z_i zi和 z j z_j zj,两个向量构成了一组正例,进行相似度计算,也就是简单的单位向量内积计算出余弦相似度。目标就是最大化两者的余弦相似度。同时,一个batch中其他的数据构成了负例,最小化与负例的相似度。注意最终训练完成的编码器我们是需要舍弃掉非线性变换的。
本文使用的损失函数就是最基本的InfoNCE损失,具体可以参考我的另一篇讲解InfoNCE的博文。
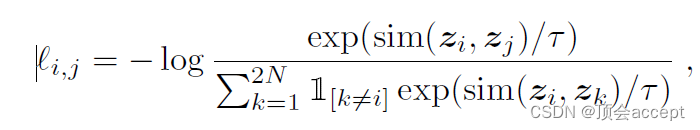

3. 代码
这里仅提供文章提到的两个点的代码:
- 数据增强
高斯模糊
import numpy as np
import torch
from torch import nn
from torchvision.transforms import transformsnp.random.seed(0)class GaussianBlur(object):"""blur a single image on CPU"""def __init__(self, kernel_size):radias = kernel_size // 2kernel_size = radias * 2 + 1self.blur_h = nn.Conv2d(3, 3, kernel_size=(kernel_size, 1),stride=1, padding=0, bias=False, groups=3)self.blur_v = nn.Conv2d(3, 3, kernel_size=(1, kernel_size),stride=1, padding=0, bias=False, groups=3)self.k = kernel_sizeself.r = radiasself.blur = nn.Sequential(nn.ReflectionPad2d(radias),self.blur_h,self.blur_v)self.pil_to_tensor = transforms.ToTensor()self.tensor_to_pil = transforms.ToPILImage()def __call__(self, img):img = self.pil_to_tensor(img).unsqueeze(0)sigma = np.random.uniform(0.1, 2.0)x = np.arange(-self.r, self.r + 1)x = np.exp(-np.power(x, 2) / (2 * sigma * sigma))x = x / x.sum()x = torch.from_numpy(x).view(1, -1).repeat(3, 1)self.blur_h.weight.data.copy_(x.view(3, 1, self.k, 1))self.blur_v.weight.data.copy_(x.view(3, 1, 1, self.k))with torch.no_grad():img = self.blur(img)img = img.squeeze()img = self.tensor_to_pil(img)return img
组合各类增强手段
class ContrastiveLearningDataset:def __init__(self, root_folder=r"D:\pyproject\representation_learning\data"):self.root_folder = root_folder@staticmethoddef get_simclr_pipeline_transform(size, s=1):"""Return a set of data augmentation transformations as described in the SimCLR paper."""color_jitter = transforms.ColorJitter(0.8 * s, 0.8 * s, 0.8 * s, 0.2 * s)data_transforms = transforms.Compose([transforms.RandomResizedCrop(size=size),transforms.RandomHorizontalFlip(),transforms.RandomApply([color_jitter], p=0.8),transforms.RandomGrayscale(p=0.2),GaussianBlur(kernel_size=int(0.1 * size)),transforms.ToTensor()])return data_transformsdef get_dataset(self, name, n_views):valid_datasets = {'cifar10': lambda: datasets.CIFAR10(self.root_folder, train=True,transform=ContrastiveLearningViewGenerator(self.get_simclr_pipeline_transform(32),n_views),download=True),'stl10': lambda: datasets.STL10(self.root_folder, split='unlabeled',transform=ContrastiveLearningViewGenerator(self.get_simclr_pipeline_transform(96),n_views),download=True)}try:dataset_fn = valid_datasets[name]except KeyError:raise InvalidDatasetSelection()else:return dataset_fn()
- 非线性变换
class ResNetSimCLR(nn.Module):def __init__(self, base_model, out_dim):super(ResNetSimCLR, self).__init__()self.resnet_dict = {"resnet18": models.resnet18(pretrained=False, num_classes=out_dim),"resnet50": models.resnet50(pretrained=False, num_classes=out_dim)}self.backbone = self._get_basemodel(base_model)dim_mlp = self.backbone.fc.in_features# add mlp projection head# 修改resnet最后一层的全连接层即可self.backbone.fc = nn.Sequential(nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.backbone.fc)def _get_basemodel(self, model_name):try:model = self.resnet_dict[model_name]except KeyError:raise InvalidBackboneError("Invalid backbone architecture. Check the config file and pass one of: resnet18 or resnet50")else:return modeldef forward(self, x):return self.backbone(x)
这篇关于(表征学习论文阅读)A Simple Framework for Contrastive Learning of Visual Representations的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









