结构化专题

仕考网:结构化面试流程介绍
(一)结构化面试 结构化面试,也叫做标准化面试,考官按照预先设定好的一套试题以问答方式与应试者当面交谈,根据应试者的言语、行为表现,对其相关能力和个性特征作出相应评价。 (二)考试流程 抵达考场——审核抽签——面试候考——进入考场——面试答题——考生退场——计分审核 (三)答题技巧 1.声音洪亮,音量可以比平时说话声音大一点。 2.语速不要过快,语速快容易卡顿,而且不便于考官听清答

结构化开发方法的三种基本控制结构
结构化开发方法概述 什么是结构化开发方法? 结构化开发方法是一种程序设计和系统开发的理念,旨在通过使用清晰、可预测的控制结构来提高程序的可读性、可维护性和可靠性。该方法强调使用标准化的编程结构,以减少程序中的错误并提高代码的逻辑清晰度。 结构化编程的历史背景 结构化编程(Structured Programming)这一概念最早由计算机科学家艾兹赫尔·戴克斯特拉(Edsger W. Dij


论文速读|ROS-LLM:具有任务反馈和结构化推理的具身智能ROS 框架
论文地址:https://arxiv.org/pdf/2406.19741 ROS-LLM 框架旨在通过集成大型语言模型(LLM)和机器人操作系统(ROS),实现对机器人的直观编程。该框架支持通过聊天界面接收自然语言提示,并能够根据 ROS 环境中的传感器读数自动提取和执行行为。框架支持三种行为模式:序列、行为树和状态机。此外,通过模仿学习,用户可以向系统添加新的机器人动作。该研究通过实验

搜索引擎:OpenSearch【结构化数据搜索托管服务】【特点:单应用亿级别文档搜索 ,毫秒级别查询延迟 ,万级别QPS】
阿里云开放搜索(OpenSearch)是一款结构化数据搜索托管服务,其能够提供简单、高效、稳定、低成本和可扩展的搜索解决方案。OpenSearch以平台服务化的形式,将专业搜索技术简单化、低门槛化和低成本化,让搜索引擎技术不再成为客户的业务瓶颈,以低成本实现产品搜索功能并快速迭代。本文将为大家介绍OpenSearch的最新推出的电商查询语义理解和搜索算法平台两个新功能。 参考资料:

视频结构化从入门到精通———检索比对类应用
检索比对类应用 1 认识“检索比对” 1.检索和比对的区别 检索和比对是信息处理和数据分析中常见的两种操作,虽然二者在一定程度上都有涉及到信息的提取和分析,但其侧重点和应用场景有所不同。检索主要关注从大规模数据集中定位相关信息,而比对则关注对特定数据对象进行详细比较和相似度分析。二者在信息处理中的角色各有侧重,检索适合于快速找到可能的候选项,而比对则用于精确地判断候选项之间的匹配度。

视频结构化从入门到精通——GPU主要硬件平台介绍
视频结构化主要硬件平台 1. 深度学习中“硬”和“软”的概念 在深度学习中,“硬”和“软”通常用于描述不同的处理方法或策略,尤其是在解码、编码、推理等任务中。它们反映了算法在处理信息时的确定性和灵活性。 软(Soft) 处理主要由CPU和主机(host)来完成,具有灵活性和通用性,适合开发、调试和需要复杂逻辑判断的任务。 硬(Hard) 处理依赖于专用硬件(如GPU、TPU、FPGA),

书生大模型实战营基础(3)——LangGPT结构化提示词编写实践
目录 0、基础知识 1、准备 1.1环境配置 1.2创建项目路径 2、模型部署 2.1获取模型 2.2部署模型为OpenAI server 3.提示工程(Prompt Engineering) 3.1 什么是Prompt 3.2 什么是提示工程 3.3 提示设计框架 4、任务 4.1利用LangGPT优化提示词 0、基础知识 Prompt:为模型提供的输

视频结构化从入门到精通——认识视频结构化
认识视频结构化 1. 视频结构化与非结构化 1. 非结构化数据 非结构化数据指的是未经处理、以原始形式存在的数据。这类数据是直接采集、记录的,包含了音频、视频等多维信息,且没有任何标签、注释或分类来表示其中的内容。非结构化数据需要进一步处理和解析,才能提取出有用的信息。 定义:计算机(程序)无法直接理解,无法对其进行查询、比对、分类、计算等操作。 特点: 数据复杂,包含多种不同的模态

大模型落地难点之结构化输出
应用至上 2023年的世界人工智能大会(WAIC)是“百模大战”,今年WAIC的关键词是“应用至上”。纵观今年论坛热点话题,无论是具身智能还是AI Agent(智能体),都指向以大模型为代表的AI技术在不同场景下的垂直应用。 从模型输出看大模型应用的两种范式: 输出非结构化数据:问答机器人,智能客服,或者另一个大模型的上游输入,都属于这种范式。技术架构是(领域)大模型+RAG,对输出格式
![[论文笔记] LLM-ICL论文:AI模型对prompt格式分隔符的敏感性——结构化Prompt格式](https://i-blog.csdnimg.cn/direct/c9303ad01790475bbedae26b4c2a3a5f.png)
[论文笔记] LLM-ICL论文:AI模型对prompt格式分隔符的敏感性——结构化Prompt格式
又见惊雷,结构化Prompt格式小小变化竟能让LLM性能波动高达76%,ICLR2024

猫头虎 分享:如何用STAR(情境、任务、行动、结果)方法来结构化回答问题?
猫头虎 分享:如何用STAR(情境、任务、行动、结果)方法来结构化回答问题? 🧠💡 今天猫头虎带您了解STAR法则的结构化魔力! 大家好!我是你们的老朋友 猫头虎 🐯。最近有不少粉丝在问我,如何在面试、职场沟通或者项目汇报中,结构化地表达观点,特别是在描述自己解决问题的能力时,如何既简洁又全面地展现出自己的专业水平。 这时候,我要强烈推荐一个超级好用的工具——STAR方法。它不仅可以帮

在结构化场景中基于单目的物体与平面SLAM方案
点云PCL免费知识星球,点云论文速读。 文章:Monocular Object and Plane SLAM in Structured Environments 作者:Shichao Yang, Sebastian Scherer 翻译:particle 本文仅做学术分享,如有侵权,请联系删除。欢迎各位加入免费知识星球,获取PDF论文,欢迎转发朋友圈分享快乐。 论文阅读模块将分享点云处理,SL
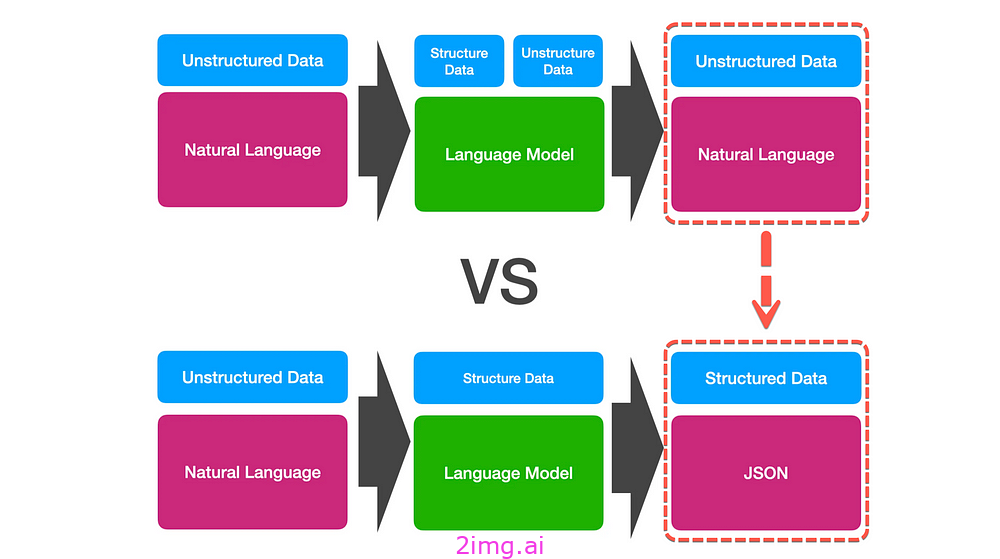
OpenAI 通过强大的结构化输出功能增强了其 API
介绍 可以通过打开/关闭 JSON 模式或使用函数调用来创建先前结构化的输出。 大型语言模型 (LLM) 与一般的对话式 UI 非常相似,擅长处理以自然语言呈现的非结构化数据。首先对这些非结构化输入进行组织和处理,然后将其重新转换为自然语言作为结构化响应。 之前有两个选项可用:JSON 模式和函数调用... OpenAI JSON 模式 启用 Open
![[创业之路-142] :生产 - 产品名称、型号、物料编码、批次、产品结构、BOM单、SN序列号、SOP、版本、回溯等常见概念之间的相互的结构化关系。](https://i-blog.csdnimg.cn/direct/1ad68cfb0acb41c79080f4dfdb065fa5.png)
[创业之路-142] :生产 - 产品名称、型号、物料编码、批次、产品结构、BOM单、SN序列号、SOP、版本、回溯等常见概念之间的相互的结构化关系。
目录 一、概念定义 1. 产品型号 2. 批次 3. 产品结构 4. 编码 5. 序列号 6. 版本 7. 物料编码 8. BOM单(物料清单) 9. 回溯 二、命名规则 2.1 产品型号命名规则 1、基本原则 2、命名要素 3、命名规则示例 4、注意事项 2.2 产品批次命名 1、产品批次命名规则 2、常见的产品批次命名元素 3、示例 4、注意事项 2

LangGPT结构化提示词编写实践 #书生大模型实战营#
1.闯关任务: 背景问题:近期相关研究发现,LLM在对比浮点数字时表现不佳,经验证,internlm2-chat-1.8b (internlm2-chat-7b)也存在这一问题,例如认为13.8<13.11。 任务要求:利用LangGPT优化提示词,使LLM输出正确结果。完成一次并提交截图即可。 任务解答: 最终完成的截图如下所示: 2.实践流程: 实践流程步骤可以参考文档:T

使用pyevtk导出结构化VTK网格以供后处理
pyevtk简介 在计算流体力学CFD中,通常需要处理三维网格数据,为了可视化,需要将其输出。本文介绍使用python的pyevtk库输出结构化网格,以供paraview进一步后处理。 代码 # **************************************************************# * Example of how to use the high l

技术人如何进行结构化思考?
目录 什么是结构化思维? 如何进行结构化思考? 结构化思维应用 阿里妹导读:在日常工作中,我们时常会碰到这样的情况,有的人讲事情逻辑非常混乱,罗列了很多事项,却把握不到重点,无法把一件事情说清楚。这种思维混乱是典型的缺少结构化思维的表现。结构化思维非常重要,不仅仅体现在表达上,也体现在在我们分析问题的过程中。具备结构化思维,才能将问题分析地更全面、更深刻。 什么是结构

Python 学习 第四册 第8章 结构化的文本文件
----用教授的方式学习。 目录 8.1结构化的文本文件 8.1.1 CSV 8.1.2 XML 8.1.3 JSON 8.1.4 YAML 8.1结构化的文本文件 结构化的文本有很多格式,区别它们的方法如下所示。 • 分隔符,比如 tab('\t')、逗号(',')或者竖线('|')。逗号分隔值(CSV)就是这样的例子。 • '<' 和 '>' 标签,例如 XML 和
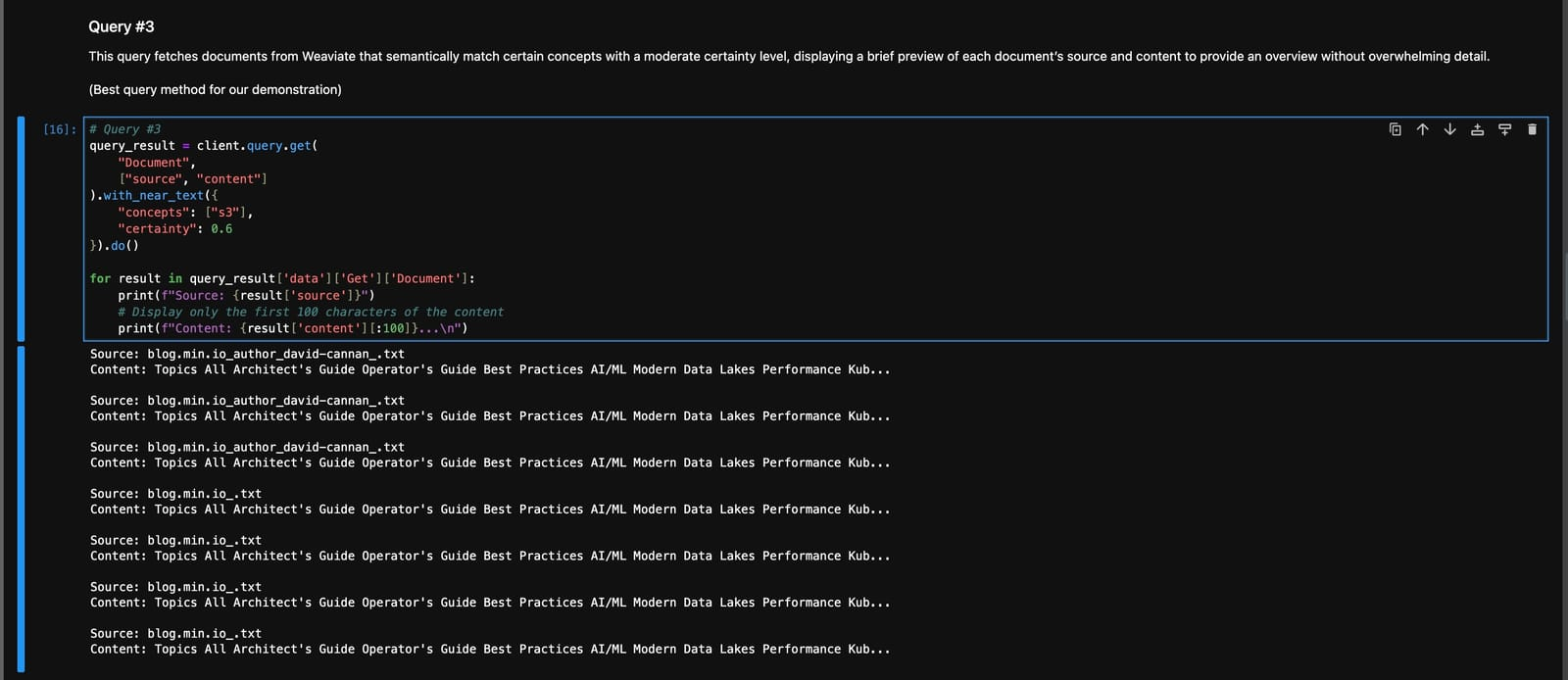
动态 ETL 管道:使用非结构化 IO 将 AI 与 MinIO 和 Weaviate 的 Web
在现代数据驱动的环境中,网络是一个无穷无尽的信息来源,为洞察力和创新提供了巨大的潜力。然而,挑战在于提取、构建和分析这片浩瀚的数据海洋,使其具有可操作性。这就是Unstructured-IO 的创新,结合MinIO的对象存储和Weaviate的AI和元数据功能的强大功能。它们共同创建了一个动态 ETL 管道,能够将非结构化 Web 数据转换为结构化的、可分析的格式。 本文探讨了这些强大技术的

结构化表达,了解python的pep
什么是PeP PEP是Python Enhancement Proposal(Python增强提案)的缩写。它是Python社区用来提出新特性、改进Python语言的标准化文档。PEP提案可以涉及从语言语法到标准库、工具和开发流程的各个方面。PEP经过讨论、审查和最终投票,最终被接受或者被拒绝。PEP的目的是帮助Python社区共同协作,提出和实现Python语言的发展方向。 为什么需要PeP

【文档智能 RAG】RAG增强之路:增强PDF解析并结构化技术路线方案及思路
前言 现阶段,尽管大模型在生成式问答上取得了很大的成功,但由于大部分的数据都是私有数据,大模型的训练及微调成本非常高,RAG的方式逐渐成为落地应用的一种重要的选择方式。然而,如何准确的对文档进行划分chunks,成为一种挑战,在现实中,大部分的专业文档都是以 PDF 格式存储,低精度的 PDF 解析会显著影响专业知识问答的效果。因此,本文将介绍针对pdf,介绍一些pdf结构化技术链路供参考。
思维导图,助你化繁为简,结构化知识与想法;用过了就回不去了。MindMaster/XMind...
思维导图 思维导图又叫做脑图,人的大脑很难去记住一些紊乱的数据,脑图就是利用图形化的方式进行发散性思维的一种工具,它把复杂性的知识体系转化为形象化的图形表示,更加形象具体。 帮助理清思路、捕捉灵感、归纳推演、学习和记忆,将纷繁复杂的知识和想法以有序化结构化的方式组织、管理和呈现。 它大概率长下图这样,你可以很直观的通过一张图就掌握整个HTML相关的知识点: 一、使用情景 维导图作为一个

结构化思维--让思考更清晰,让表达更准确。
今天的分享主要包括3个方面: 什么是结构化思维?用结构化思维接受信息用结构化思维表达信息 1.什么是结构化思维? 回答这个问题前,先聊聊结构。结构是指事物内部各组成部分之间的组织形式、结合方式或排列顺序。任何事物都具有特定的结构。 结构化思维通俗易懂一点就是面对问题的时候可以通过某种结构,将它拆解成一个个能解决的部分。 今天我们主要讲的结构是金字塔结构。 例如:如果我们在思考过程中