本文主要是介绍ERNIE-M论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

公众号 系统之神与我同在
https://arxiv.org/abs/2012.15674
概述:
通过两个阶段的自定义的预训练任务来增强多语言语义的表征
第一阶段:
基于cross-attention机制的mlm任务(CAMLM),
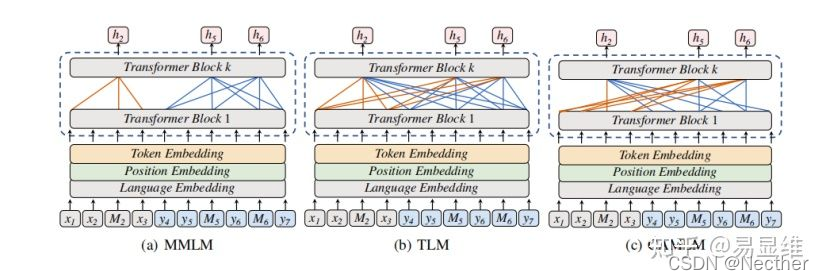
这里,x指的是一种语言,y指的是另一种语言,M指的是要预测的token,这样的句子对构成了并行语料库(parallel corpus)。(注:MMLM和TLM是目前已有的处理多语言的baseline模型)
其中MMLM模型的特点是:M token的预测只依赖(或者是只attention)于本语言的其他token,并不考虑另一种语言的token。
TLM的特点是:M token的预测既依赖于本语言的其他token,同时也依赖另一种语言的token。
CAMLM的特点:M token的预测依赖与另一种语言的token,却不依赖与本语言的其他token。
第二阶段:
反译遮挡语言模型(Back-translation Masked Langoage Modeling)
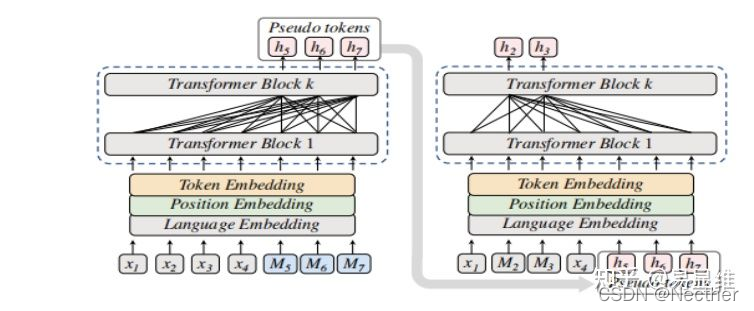
具体做法:在一种语言句子(如:x1 x2 x3 …)的后面,加上几个Mask token,然后用模型将M翻译成另一种语言下对应的token(换句话说,M经过模型之后期望得到前面x1 x2 x3在另一种语言下的翻译),从而得到伪翻译的字符(pseudo token);之后再将得到的伪字符拼接到原句子后面,与此同时mask掉前面的某些token,再输入模型中进行有监督的mlm任务(这里也就又回到了类似与第一个任务中)
这篇关于ERNIE-M论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








