本文主要是介绍文心ERNIE 3.0 Tiny新升级!端侧压缩部署“小” “快” “灵”!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,今天带来的是有关文心ERNIE 3.0 Tiny新升级内容的文章。
近年来,随着深度学习技术的迅速发展,大规模预训练范式通过一次又一次刷新各种评测基线证明了其卓越的学习与迁移能力。在这个过程中,研究者们发现通过不断地扩大模型参数便能持续提升深度学习模型的威力。然而,参数的指数级增长意味着模型体积增大、所需计算资源增多、计算耗时更长,而这无论出于业务线上响应效率的要求还是机器资源预算问题,都给大模型落地带来了极大的挑战。让我们一起看看文心ERNIE 3.0 Tiny如何来解决这些问题的吧!
 图:模型上线时精度、时延、内显存占用等多重需求示意
图:模型上线时精度、时延、内显存占用等多重需求示意
如何在保证效果的前提下压缩模型?如何适配 CPU、GPU 等多硬件的加速?如何在端侧场景下落地大模型?如何让加速工具触手可及?这是行业内亟待解决的课题。2022年6月,文心大模型中的轻量化技术加持的多个文心ERNIE 3.0 Tiny轻量级模型(下文简称文心ERNIE 3.0 Tiny v1)开源至飞桨自然语言处理模型库PaddleNLP中,该模型刷新了中文小模型的SOTA成绩,配套模型动态裁剪和量化推理方案,被学术与工业界广泛使用。
近期,文心ERNIE 3.0 Tiny升级版–––文心ERNIE 3.0 Tiny v2也开源了!相较于v1,文心ERNIE 3.0 Tiny v2在Out-domain(域外数据)、Low-resource(小样本数据)的下游任务上精度显著提升,并且v2还开源了3L128H结构,5.99M参数量的小模型,更适用于端侧等低资源场景。
同时,PaddleNLP依托PaddleSlim、Paddle Lite、FastDeploy开源了一整套端上语义理解压缩和部署方案。通过模型裁剪、量化感知训练、Embedding量化等压缩方案,在保持模型精度不降的情况下,推理加速2.1倍,内存占用降低62.18%(降低2.6倍),体积缩小92.2%(缩小12.8倍)仅5.4M。再结合高性能NLP处理库FastTokenizer对分词阶段进行加速,使端到端推理性能显著提升,从而将文心ERNIE 3.0 Tiny v2模型成功部署至端侧。由于端侧部署对内存占用的要求比服务端更高,因此该方案也同样适用于服务端部署。
 图:端侧设备示意
图:端侧设备示意

文心 ERNIE 3.0 Tiny v2开源
百度文心大模型团队在2021年底发布了百亿级别大模型文心ERNIE 3.0和千亿级别的大模型文心ERNIE 3.0 Titan。为了让大模型的能力能够真正在一线业务发挥威力,文心大模型团队推出多个轻量级模型,即文心ERNIE 3.0 Tiny系列,刷新了中文小模型的成绩。除了在GPU上,这些模型也能在CPU上轻松调用,极大拓展了大模型的使用场景。本次开源的文心ERNIE 3.0 Tiny v2,使教师模型预先注入下游知识并参与多任务训练,大大提高了小模型在下游任务上的效果。

多任务学习提升泛化性
文心ERNIE 3.0 Tiny v1直接通过在线蒸馏技术将预训练大模型压缩成预训练小模型。在此基础上,文心ERNIE 3.0 Tiny v2 首先在多个下游任务中微调教师模型,让教师模型学习到下游任务相关知识,并将这些知识通过蒸馏的方式传导给学生模型。尽管学生模型完全没有见过下游数据,也能够蒸馏获取到下游任务的相关知识,进而使下游任务的效果得到提升。由于教师模型是在多任务上进行微调的,多任务学习带来的强泛化性也能传递给学生模型,从而提升小模型的泛化性,最终获得的学生模型相比文心ERNIE 3.0 Tiny v1在Out-domain和Low-resource数据集上获得大幅提升。
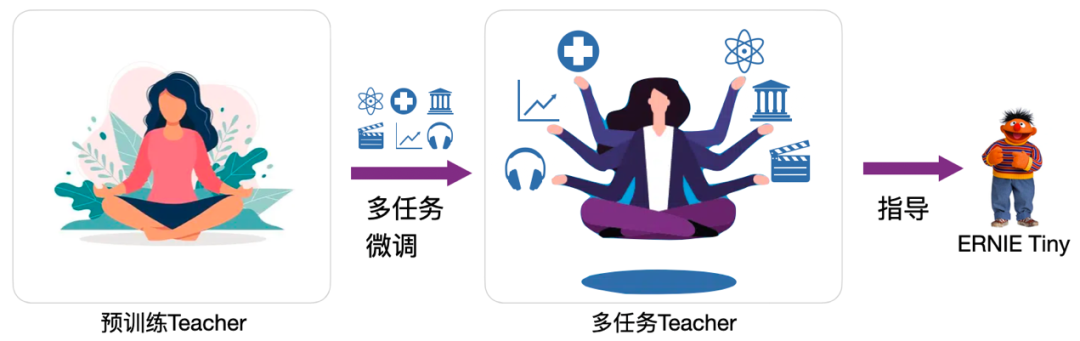 图:文心ERNIE 3.0 Tiny v2示意
图:文心ERNIE 3.0 Tiny v2示意
文心ERNIE 3.0 Tiny v2 包含一系列不同尺寸的中文预训练模型,方便不同性能需求的应用场景使用:
-
文心ERNIE 3.0 Tiny-Base-v2 (12-layer, 768-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Medium-v2 (6-layer, 768-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Mini-v2 (6-layer, 384-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Micro-v2 (4-layer, 384-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Nano-v2 (4-layer, 312-hidden, 12-heads)
-
文心ERNIE 3.0 Tiny-Pico-v2 (3-layer, 128-hidden, 2-heads)
除以上中文模型外,本次还发布了英文版文心ERNIE 3.0 Tiny-Mini-v2,适用于各类英文任务。
多任务学习的能力加持下,在文本分类、文本推理、实体抽取、问答等各种 NLU 任务上,文心ERNIE 3.0 Tiny v2相比文心ERNIE 3.0 Tiny v1在Out-domain、Low-resource数据上均获得显著的效果提升,在In-domain上也有一定提升。
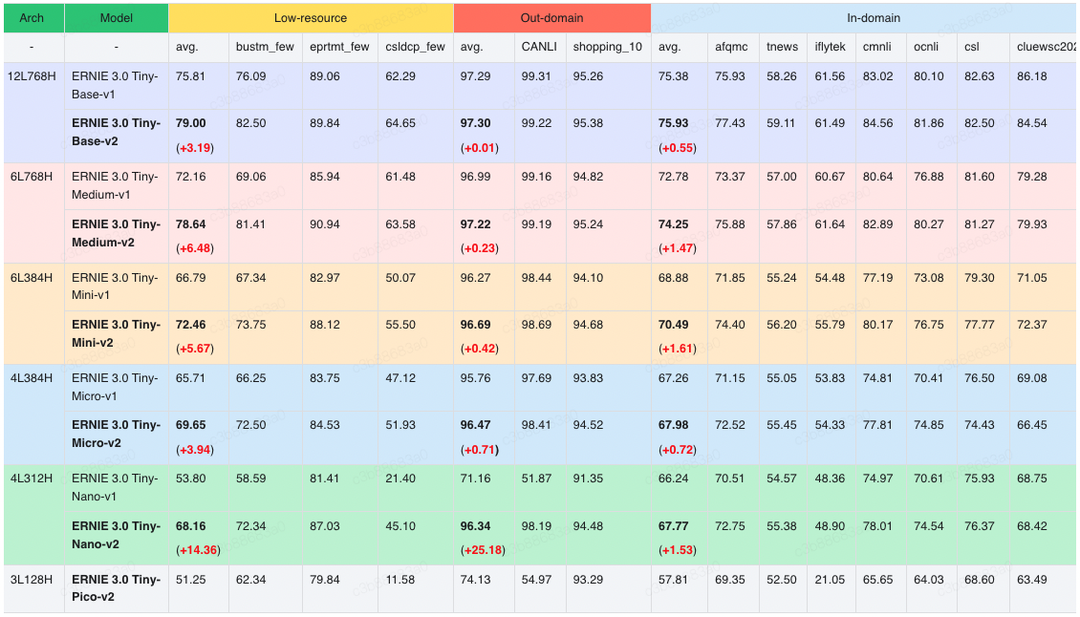
文心ERNIE 3.0 Tiny v2 多任务学习、在线蒸馏方案效果显著,刷新了中文小模型的SOTA成绩。具体对比数据见如下模型精度-时延图,横坐标表示在 ARM CPU(高通865芯片)上,基于ARMv8 arch测试(batch_size=1, seq_len=32)的推理时延(Latency,单位毫秒),纵坐标是 CLUE 10 个任务上的平均精度(包含文本分类、文本匹配、自然语言推理、代词消歧、阅读理解等任务),其中CMRC2018阅读理解任务的评价指标是Exact Match(EM),其它任务的评价指标均是Accuracy。模型名下方标注了模型的参数量。
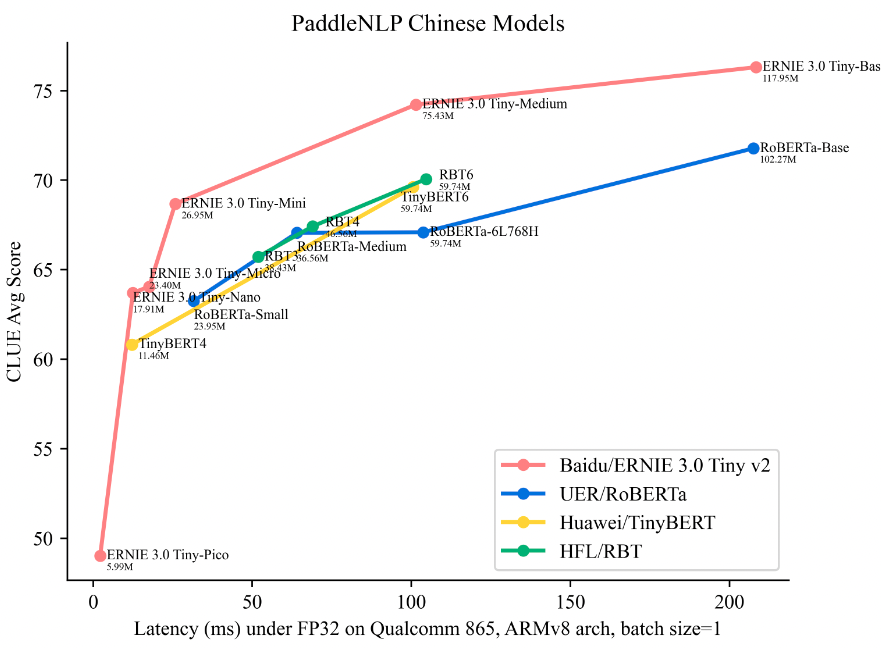
图中越靠左上方的模型,精度和性能水平越高。可以看到文心ERNIE 3.0 Tiny v2在同等规模的开源模型中,综合实力领先其他同类型轻量级模型,这波开源厉害了!与UER/RoBERTa-Base相比,12L768H的文心ERNIE 3.0 Base平均精度提升了4.5个点;6L768H的文心ERNIE 3.0 Medium相比12L768H的UER/Chinese-RoBERTa高2.4,并且节省一倍运算时间;另外值得一提的是,这些小模型能够直接部署在CPU上,简直是CPU开发者的希望之光!
在PaddleNLP中,可一键加载以上模型。
from paddlenlp.transformers import *
tokenizer = AutoTokenizer.from_pretrained("ernie-3.0-tiny-medium-v2-zh")
# 用于分类任务(本项目中的意图识别任务)
seq_cls_model = AutoModelForSequenceClassification.from_pretrained("ernie-3.0-tiny-medium-v2-zh")
# 用于序列标注任务(本项目中的槽位填充任务)
token_cls_model = AutoModelForTokenClassification.from_pretrained("ernie-3.0-tiny-medium-v2-zh")
# 用于阅读理解任务
qa_model = AutoModelForQuestionAnswering.from_pretrained("ernie-3.0-tiny-medium-v2-zh")此外,PaddleNLP还提供了CLUE Benchmark的一键评测脚本,并提供了大量中文预训练模型在CLUE上的效果。PaddleNLP接入了Grid Search策略,支持在超参列表范围内自动搜索超参,保留最佳结果和对应的超参数,方便一键复现模型效果,且打通了CLUE各个任务数据处理、训练、预测、结果提交的流程,方便用户快速提交CLUE榜单。
以上模型均已开源,如有帮助,欢迎star支持。
-
模型地址
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-tiny

端上语义理解压缩、部署方案
由文心大模型蒸馏得到的文心ERNIE 3.0 Tiny v2可以直接在下游任务上微调应用,如果想要将模型部署在移动端、边缘端,或者想要进一步压缩模型体积,降低推理时延,可使用PaddleNLP开源的端上语义理解压缩方案。以边缘端业务上线场景为例,模型经过压缩后,精度基本无损,端到端推理速度达到原来的2.13倍,内存占用减小了62.18%,体积减小了92.2%!
结合飞桨模型压缩工具PaddleSlim,PaddleNLP发布了端上语义理解压缩方案,包含裁剪、量化级联压缩,如下图所示:

基于PaddleNLP提供的的模型压缩API,可大幅降低开发成本。压缩API支持对ERNIE、BERT等ransformer类下游任务微调模型进行裁剪和量化。只需要简单地调用compress()即可一键启动裁剪量化流程,并自动保存压缩后的模型。
from paddlenlp.trainer import PdArgumentParser, CompressionArguments# Step1: 使用 PdArgumentParser 解析从命令行传入的超参数,以获取压缩参数 compression_args;
parser = PdArgumentParser(CompressionArguments)
compression_args = parser.parse_args_into_dataclasses()# Step2: 实例化 Trainer 并调用 compress()
trainer = Trainer(model=model,args=compression_args,data_collator=data_collator,train_dataset=train_dataset,eval_dataset=eval_dataset,criterion=criterion)trainer.compress()PaddleNLP模型裁剪、量化使用示例
下面会对压缩方案中的词表裁剪、模型宽度裁剪、量化感知训练、词表量化进行介绍。

词表裁剪
端侧部署对内存占用的要求较高,而文心ERNIE 3.0 Tiny预训练模型的词表参数量在总参数量中占比很大,因此在下游任务微调之前,可以按照词频对词表进行裁剪,去除出现频次较低的词,这样能够减少分词后[UNK]的出现,使精度得到最大限度保持。例如,某数据集4w大小的词表,高频出现的词不到1w个,此时通过词表裁剪可以节省不少内存。
 模型宽度裁剪
模型宽度裁剪
基于DynaBERT宽度自适应裁剪策略,通过知识蒸馏的方法,在下游任务中将文心ERNIE 3.0 Tiny的知识迁移到宽度更窄的学生网络中,最后得到效果与教师模型接近的学生模型。一般来说,对于4到6层的NLU模型,宽度裁剪1/4可基本保证精度无损。DynaBERT宽度自适应裁剪策略主要分为以下3个步骤:
Step1
根据Attention Head和FFN中神经元的重要性对神经元进行重新排序,将新模型作为待压缩的模型,这样可以保证之后对神经元的裁剪可以更大程度地保留更重要的神经元。
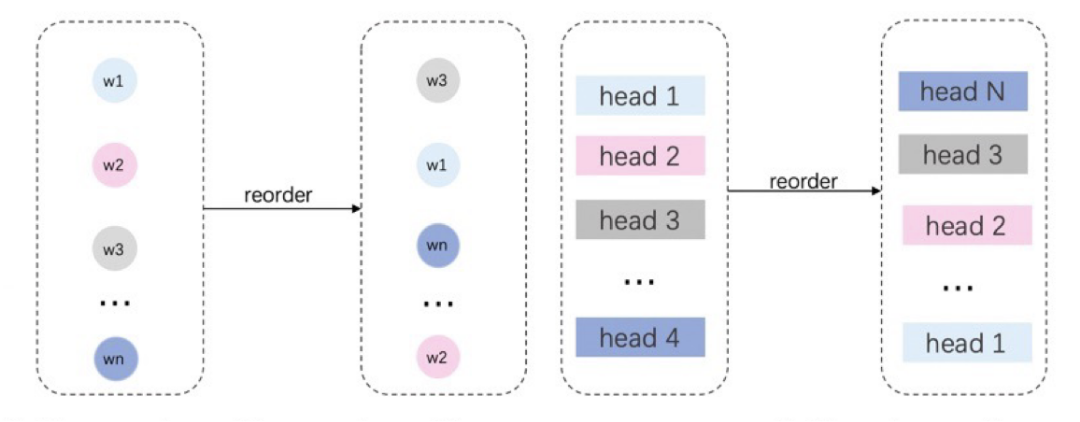
Step2
用教师模型同时蒸馏按不同比例压缩宽度的多个模型。
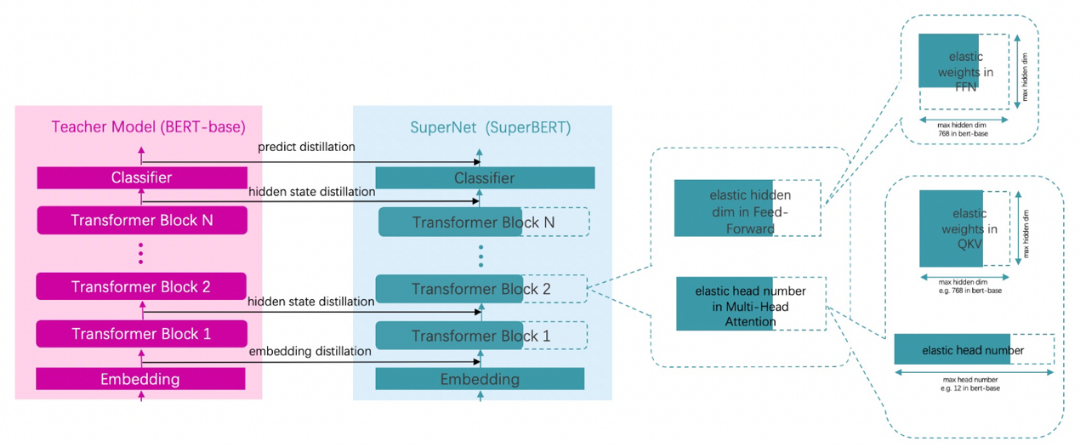
Step3
在蒸馏后得到的不同宽度的学生模型中,选择大小和精度符合要求的模型并导出。

量化感知训练
模型量化是一种通过将训练好的模型参数、激活值从FP32浮点数转换成INT8整数来减小存储、加快计算速度、降低功耗的模型压缩方法。目前主要有两种量化方法:
-
静态离线量化:使用少量校准数据计算量化信息,可快速得到量化模型;
-
量化感知训练:在模型中插入量化、反量化算子并进行训练,使模型在训练中学习到量化信息 。
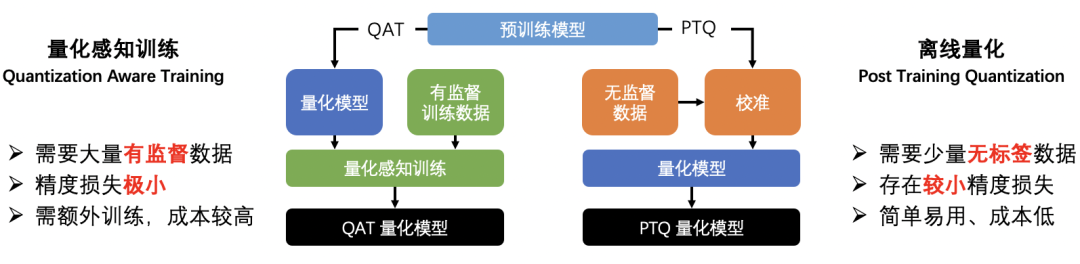 图:量化感知训练 vs 离线量化
图:量化感知训练 vs 离线量化
在对文心ERNIE 3.0 Tiny的压缩中,更推荐使用量化感知训练的方式。通常情况下,使用量化感知训练的方法能够比使用静态离线量化取得更高的精度。这是因为在量化感知训练之前,压缩API在模型的矩阵乘算子前插入量化、反量化算子,使量化带来的误差可以在训练过程中被建模和优化,能够使模型被量化后精度基本无损。

Embedding 量化
端侧部署对显存的要求比较高,为了能进一步节省内存占用,可对模型的 Embedding 权重进行INT8量化,并将精度的损失保持在0.5%之内。Embedding 量化主要分两步:
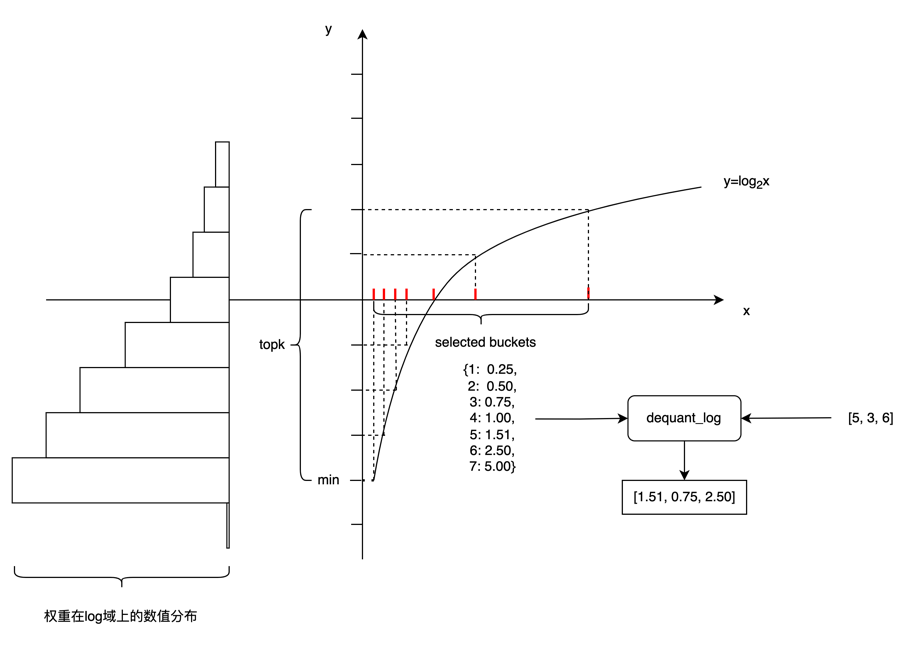
Step1
离线统计权重在log域上的分布并进行分桶,根据分桶结果将FP32权重量化成INT8权重。如图所示,量化算子会统计权重在log域上量化后的数值分布,取出现次数top k的FP32数值,记录在对应的x轴上,作为buckets的value,其中key为 [-128,127] 范围内的整数。
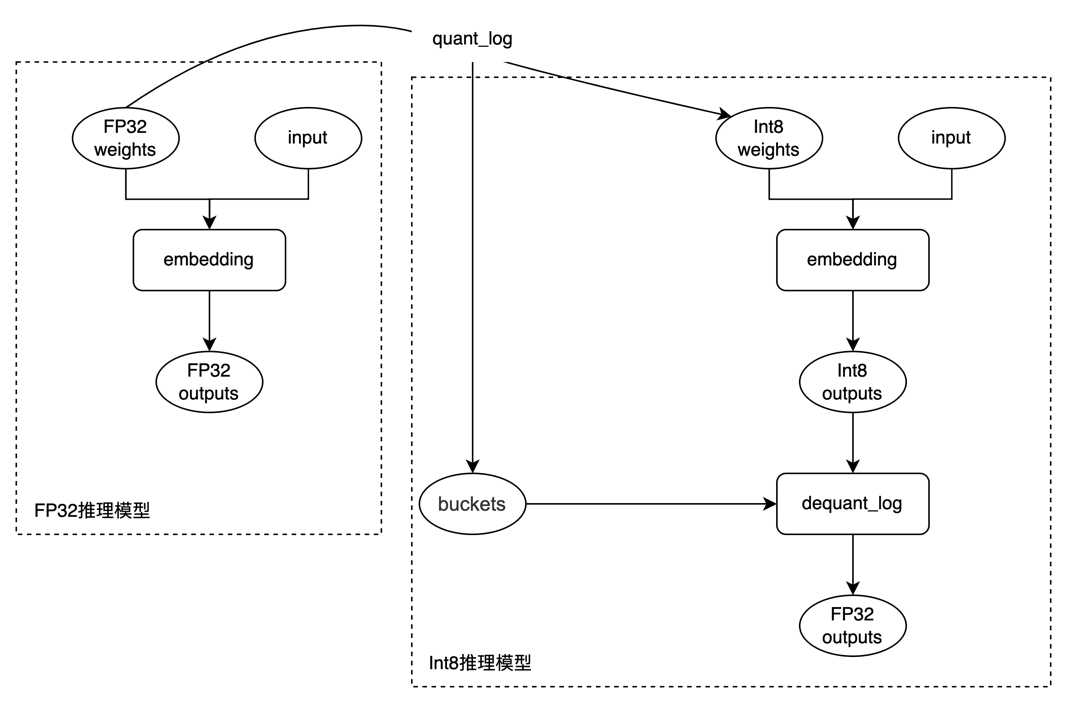
Step2
构造INT8推理模型:将权重设置为量化后的INT8权重,并在Embedding对应的算子后,插入反量化算子,反量化算子根据buckets将INT8数值类型的输入 [5, 3, 6] 反量化为 [1.51, 0.75, 2.50],实现方式为查表。

部署
模型压缩后,精度基本无损,体积减小了92.2%,仅有5.4MB。到此,算法侧的工作基本完成。为了进一步降低部署难度,可以使用飞桨FastDeploy对模型进行部署。
FastDeploy是一款全场景、易用灵活、极致高效的AI推理部署工具,提供开箱即用的部署体验。FastDeploy为NLP任务提供了一整套完整的部署Pipeline,提供文心ERNIE 3.0 Tiny模型从文本预处理、推理引擎Runtime以及后处理三个阶段所需要的接口模块,开发者可以基于这些接口模块在云、边、端上部署各类常见的NLP任务,如文本分类、序列标注、信息抽取等。
FastDeploy中的Paddle Lite后端基于算子融合和常量折叠对深度模型进行优化,无缝衔接了Paddle Lite的FP16和INT8的推理能力,可使模型推理速度大幅提升。其集成的高性能NLP处理库FastTokenizer(视觉领域集成了高性能AI处理库FlyCV),能够对分词阶段进行加速,适配GPU、CPU等多硬件。例如在麒麟985芯片上测试,单条文本的分词时延低于0.1毫秒。
在端到端部署方面,FastDeploy在Android端目前支持CV和NLP中的7+场景,35+模型的开箱即用,以及简单一致的API,让Android开发者快速完成AI落地,并且获得考虑前后处理在内端到端高性能的部署体验。
综上,基于FastDeploy部署工具,可完成文心ERNIE 3.0 Tiny端侧和服务端的高效部署。以下动图展示了基于文心ERNIE 3.0 Tiny v2的意图识别、槽位填充联合模型,使用FastDeploy部署在Android APP上进行推理的效果展示:

-
GitHub地址
https://github.com/PaddlePaddle/FastDeploy
总结来说,以上各类压缩策略以及对应的推理功能如果从零实现非常复杂,飞桨模型压缩工具库PaddleSlim和飞桨高性能深度学习端侧推理引擎Paddle Lite提供了一系列压缩、推理工具链。飞桨AI推理部署工具FastDeploy对其进一步封装,使开发者可以通过更简单的API去实现模型压缩、推理部署流程,适配多领域模型,并兼容多硬件。PaddleNLP依托以上工具,提供NLP模型数据处理、训练、压缩、部署全流程的最佳实践。

文心大模型
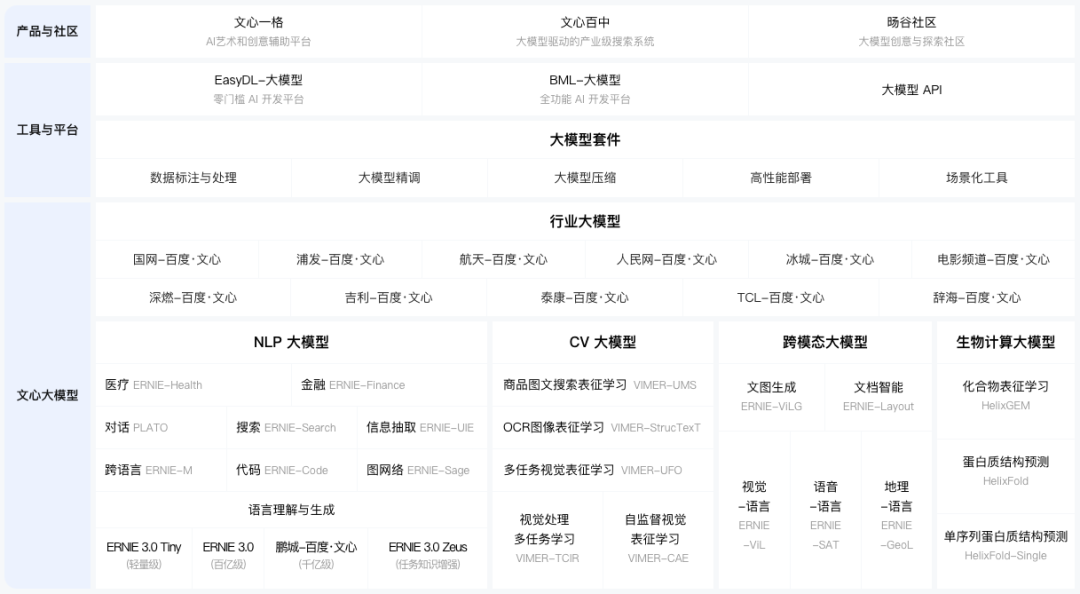
随着数据井喷、算法进步和算力突破,效果好、泛化能力强、通用性强的预训练大模型(以下简称“大模型”),成为人工智能发展的关键方向与人工智能产业应用的基础底座。
文心大模型源于产业、服务于产业,是产业级知识增强大模型,涵盖基础大模型、任务大模型、行业大模型,大模型总量达36个,并构建了业界规模最大的产业大模型体系。文心大模型配套了丰富的工具与平台层,包括大模型开发套件、API以及内置文心大模型能力的EasyDL和BML开发平台。百度通过大模型与国产深度学习框架融合发展,打造了自主创新的AI底座,大幅降低了AI开发和应用的门槛,满足真实场景中的应用需求,真正发挥大模型驱动AI规模化应用的产业价值。欢迎点击阅读原文访问官网地址。
-
文心大模型官网地址
https://wenxin.baidu.com/
相关项目地址
-
官网地址
https://www.paddlepaddle.org.cn
-
PaddleNLP
https://github.com/PaddlePaddle/PaddleNLP
-
FastDeploy
https://github.com/PaddlePaddle/FastDeploy
-
PaddleSlim
https://github.com/PaddlePaddle/PaddleSlim
-
Paddle Lite
https://github.com/PaddlePaddle/Paddle-Lite
参考文献
[1] Liu W, Chen X, Liu J, et al. ERNIE 3.0 Tiny: Frustratingly Simple Method to Improve Task-Agnostic Distillation Generalization[J]. arXiv preprint arXiv:2301.03416, 2023.
[2] Su W, Chen X, Feng S, et al. ERNIE-Tiny: A Progressive Distillation Framework for Pretrained Transformer Compression[J]. arXiv preprint arXiv:2106.02241, 2021.
[3] Wang S, Sun Y, Xiang Y, et al. ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation[J]. arXiv preprint arXiv:2112.12731, 2021.
[4] Sun Y, Wang S, Feng S, et al. ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation[J]. arXiv preprint arXiv:2107.02137, 2021.
[5] Hou L, Huang Z, Shang L, Jiang X, Chen X and Liu Q. DynaBERT: Dynamic BERT with Adaptive Width and Depth[J]. arXiv preprint arXiv:2004.04037, 2020.
[6] Wu H, Judd P, Zhang X, Isaev M and Micikevicius P. Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation[J]. arXiv preprint arXiv:2004.09602v1, 2020.
这篇关于文心ERNIE 3.0 Tiny新升级!端侧压缩部署“小” “快” “灵”!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







