端侧专题

2024年AI芯片峰会——边缘端侧AI芯片专场
概述 正文 存算一体,解锁大模型的边端侧潜力——信晓旭 当下AI芯片的亟需解决的问题 解决内存墙问题的路径 产品 面向大模型的国产工艺边缘AI芯片创新与展望——李爱军 端侧AI应用“芯”机遇NPU加速终端算力升级——杨磊 边缘端的大模型参数量基本小于100B AI OS:AI接口直接调用AI模型完成任务 具身智能的大脑芯片 大模

面壁小钢炮3.0发布:端侧ChatGPT时代的技术飞跃
一、面壁小钢炮3.0模型介绍 ➤ MiniCPM 3.0 开源地址: 🔗 https://github.com/OpenBMB/MiniCPM 🔗 https://huggingface.co/openbmb/MiniCPM3-4B 2024年9月5日,面壁智能发布 MiniCPM3-4B!该模型的表现超越 Phi-3.5-mini-instruct 和 GPT-3

端侧模型 + 硬件:AI爆发的下一个机会?|端侧模型|AI硬件|人工智能
目录 1. 端侧模型与AI硬件的技术发展现状 1.1 端侧模型的定义与发展 1.2 专用AI硬件的发展 2. 端侧模型 + 硬件的应用场景 2.1 智能手机与个人设备 2.2 物联网与边缘计算 2.3 自动驾驶与无人机 3. 端侧模型 + 硬件的优势 3.1 低延迟与高实时性 3.2 数据隐私与安全性 3.3 节省带宽与降低成本 3.4 高度定制与灵活性 4. 端侧模型

碎碎念:关于小模型或者端侧大模型
今年有个有趣的现象,大厂分别推出能够在端侧运行的小模型 Microsoft:Phi-3 Vision 4.2b,支持 文本、图像输入,可以运行在 surface 上 Google:Gemini Nano 1.8b/3.2b,支持文本,可以运行在手机上 Apple:Apple Intelligence 3b,支持文本图像,可以运行在手机上 意味着,大厂们都想通过大模型来强化自家系统的竞争力,

微软发布 Phi-3.5 系列模型,涵盖端侧、多模态、MOE;字节 Seed-ASR:自动识别多语言丨 RTE 开发者日报
开发者朋友们大家好: 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。 本期编辑:@SSN,@鲍勃 01 有话题的新闻

洋人道歉,「国产」出品,全球最强端侧多模态大模型!(懒人包)
最近,在AI圈发生了一件大事,那就是斯坦福AI团队因抄袭清华系开源大模型而引起了国际社交平台上的巨大争议。事件的核心围绕一款名为“Llama3-V”的斯坦福团队开发的多模态大模型,该模型一经发布,便以其低成本高效率的特性,在开源社区迅速走红。 然而,随着更多细节的披露,人们发现Llama3-V在架构和代码层面与清华系合作的面壁智能团队开发的MiniCPM-Llama3-V 2.5(外号“面壁小钢

LLMs之MiniCPM:MiniCPM(揭示端侧大语言模型的无限潜力)的简介、安装和使用方法、案例应用之详细攻略
LLMs之MiniCPM:MiniCPM(揭示端侧大语言模型的无限潜力)的简介、安装和使用方法、案例应用之详细攻略 目录 MiniCPM的简介 0、更新日志 1、公开的模型 2、局限性 3、文本模型评测 越级比较: 同级比较: Chat模型比较: DPO后模型比较: MiniCPM-2B-128k 模型评测 MiniCPM-MoE-8x2B模型评测 多模态模型

Llama3 端侧部署:算丰 SG2300x 与爱芯元智 AX650N
美国当地时间4月18日,Meta 开源了 Llama3 大模型,包括一个 8B 模型和一个 70B 模型在测试基准中,Llama 3 模型的表现相当出色,在实用性和安全性评估中,与那些市面上流行的闭源模型不相上下。 Llama3 性能指标: 相对于 LLama2,Llama3 的性能有了很大的提高: Meta 表示,Llama 3 在多个关键基准测试中展现出卓越性能,超越了业内先进的同类

【论文阅读】《Octopus v2: On-device language model for super agent》,端侧大模型的应用案例
今年LLM的发展趋势之一,就是端侧LLM快速发展,超级APP入口之争异常激烈。不过,端侧LLM如何应用,不知道细节就很难理解。正好,《Octopus v2: On-device language model for super agent》这篇文章可以解惑。 对比部署在云上,端侧大模型的好处主要来说就是:成本低、增强隐私。创建更小的模型以部署在智能手机、汽车、VR 耳机和个人电脑等边缘设备,等等
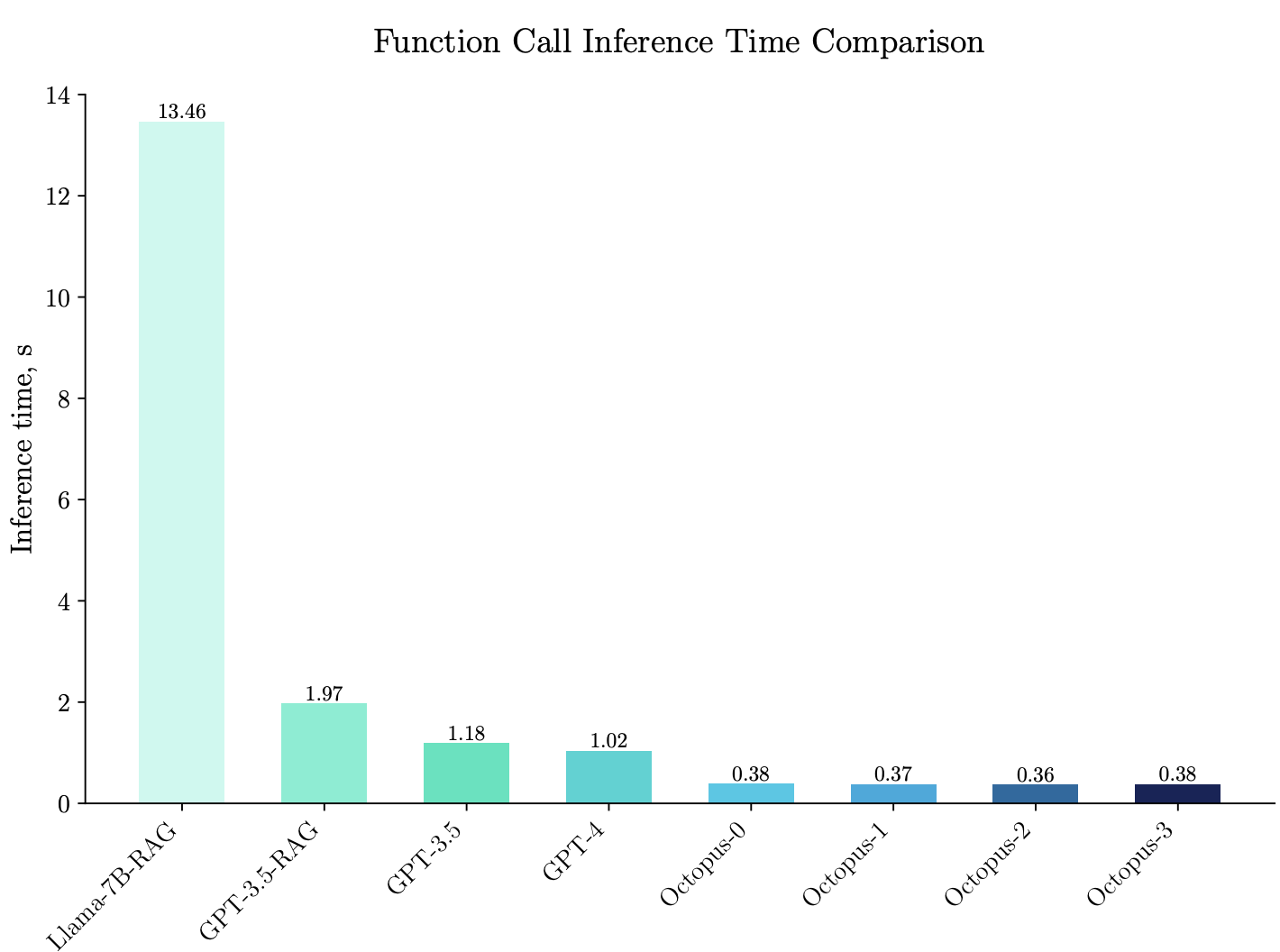
斯坦福发布端侧AI模型Octopus V2:推理比GPT-4快168%,准确率超Llama7B
斯坦福大学科研团队近期发布的Octopus V2端侧AI大模型犹如一颗璀璨的新星冉冉升起,凭借其卓越的性能和高效的推理能力,在业界引起了巨大轰动。 这款拥有20亿参数的端侧强大语言模型一亮相,便在开发者社群内迅速蹿红,首夜下载量即突破两千次大关,展现出前所未有的魅力。 Octopus V2的独特之处在于其能在智能手机、汽车和个人电脑等多种终端设备上流畅运行,尤其在涉及自动化工作流的任务中,它能
Kaldi sherpa-ncnn 端侧语音识别
本文介绍一款基于新一代 Kaldi 的、超级容易安装的、实时语音识别 Python 包:sherpa-ncnn。 小编注: 它有可能是目前为止,最容易 安装的实时语音识 别 Python 包(谁试谁知道)。 它的使用方法也是极简单的。 安装 pip install sherpa-ncnn 对的,就是这一句,所有的依赖都从源码安装。 其实目前 sherpa-ncnn 只有下面 3

LLM端侧部署系列 | 如何将阿里千问大模型Qwen部署到手机上?实战演示(下篇)
引言 简介 编译Android可用的模型 转换权重 生成配置文件 模型编译 编译apk 修改配置文件 绑定android library 配置gradle 编译apk 手机上运行 安装 APK 植入模型 效果实测 0. 引言 清明时节雨纷纷,路上行人欲断魂。 小伙伴们好,我是《小窗幽记机器学习》的小编:卖青团的小女孩,紧接前文LLM系列。今天这篇小作文

重磅| 淘宝轻量级的深度学习端侧推理引擎 MNN 开源
淘宝上的移动AI技术 现在你也可以在自己的产品中使用啦! 与 Tensorflow、Caffe2 等同时覆盖训练和推理的通用框架相比,MNN 更注重在推理时的加速和优化,解决在模型部署的阶段的效率问题,从而在移动端更高效地实现模型背后的业务。这和服务器端 TensorRT 等推理引擎的想法不谋而合。 在大规模机器学习应用中,考虑到大规模的模型部署,机器学习的推理侧计算量往往是训练

叶顺舟:手机SoC音频趋势洞察与端侧AI技术探讨 | 演讲嘉宾公布
后续将陆续揭秘更多演讲嘉宾! 请持续关注! 2024中国国际音频产业大会(GAS)将于2024年3.27 - 28日在上海张江科学会堂举办。大会将以“音无界,@未来(Audio, @Future)”为主题。大会由中国电子音响行业协会、上海市浦东新区先进音视频技术协会共同主办,上海国展展览中心有限公司承办。 GAS 2024作为中国最大的音频产业盛会之一,不仅展示了音频技术
落地端侧,2B模型如何以小搏大?|对话面壁CEO李大海
文|郝 鑫 “AGI是一场马拉松”,面壁智能联合创始人、CEO,知乎CTO李大海道。 作为一个马拉松的爱好者,李大海深知在大模型的竞争中,一时的“快”只是暂时的,更重要的是把赛程中的每一步都跑下来,跑踏实。 回顾面壁智能的发展历程也确实如此,2018年脱胎于清华NLP实验室,发布了全球首个知识指导的预训练模型ERNIE;2020年成为悟道大模型的首发主力阵容;2022年成立
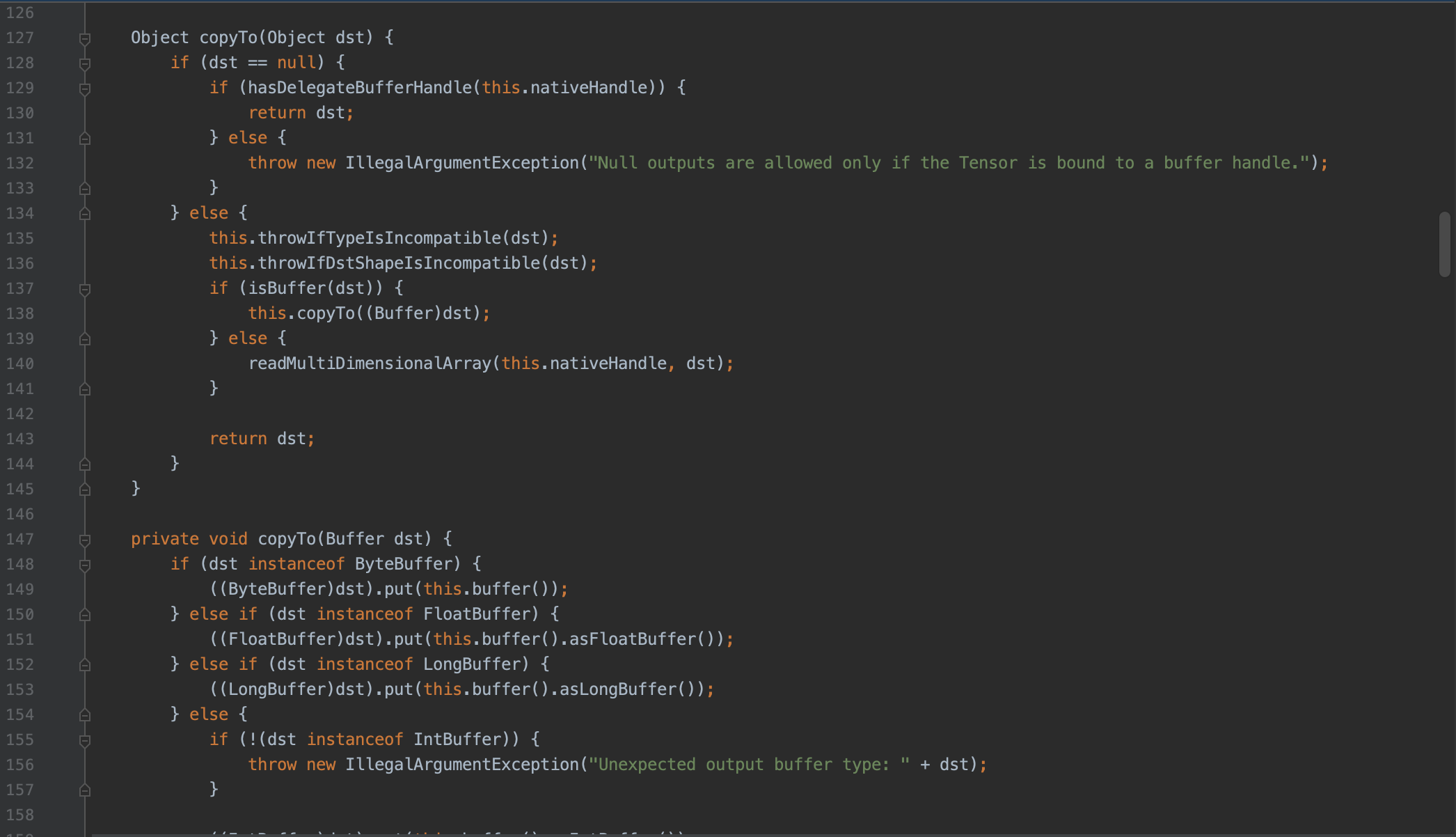
端侧AI-58同城Android部落帖子重排实现
1. 需求方案设计 利用手机端的运算能力,进行实时推荐。点击回退列表场景下,用端上的压缩模型对已下发的推荐结果,进行实时重排序。 1.1 模型 AB Test、热更新、下载 一级页加载首页数据时,算法后端服务器下发当前用户的模型 modelJson 数据: {"scene" : 1,"modelUrl": "https://58cdn.com.cn/xxx/1/modelandConf
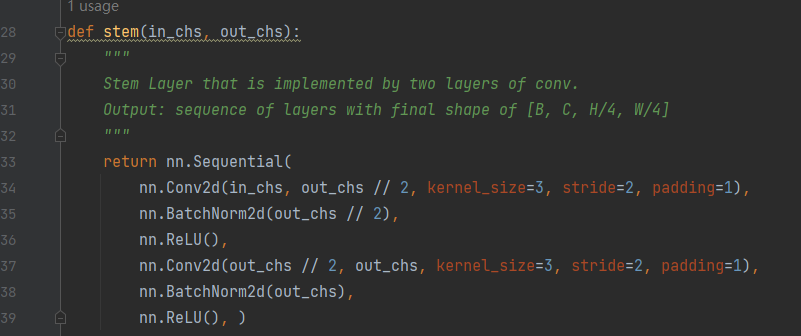
2023年度端侧transformer类分类力作SwiftFormer模型解读
写在前面:本篇直接结合代码来理解网络的笔记 paper: Swiftformer-paper code: https://github.com/Amshaker/SwiftFormer 文章目录 网络结构精析零、整体一、patch embed二、stage 网络结构精析 零、整体 可以看到结构中,整体就是: stem -> 5X(convEncoder+S
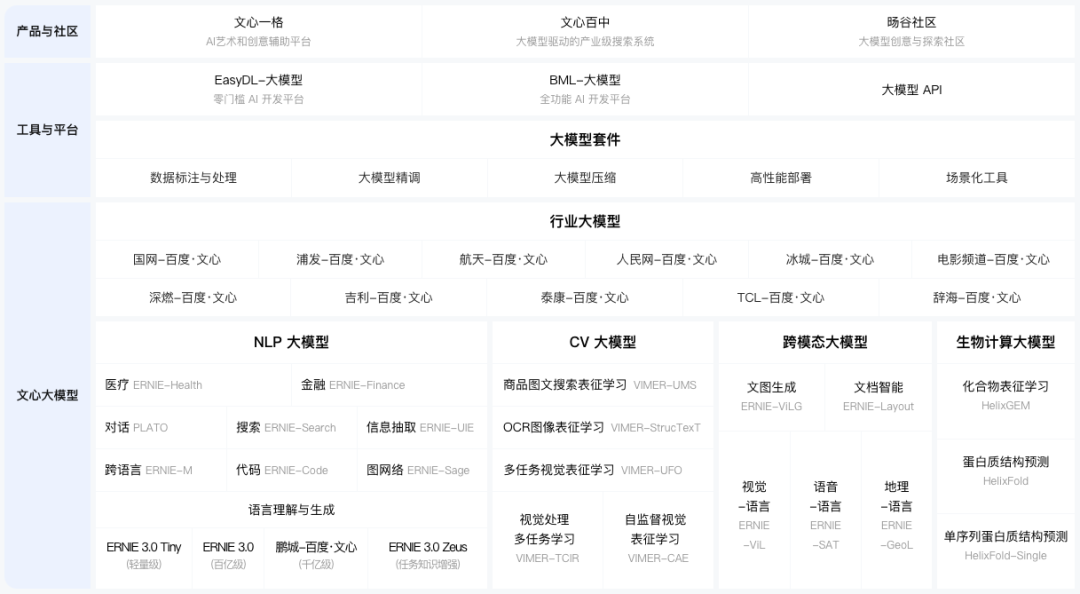
文心ERNIE 3.0 Tiny新升级!端侧压缩部署“小” “快” “灵”!
大家好,今天带来的是有关文心ERNIE 3.0 Tiny新升级内容的文章。 近年来,随着深度学习技术的迅速发展,大规模预训练范式通过一次又一次刷新各种评测基线证明了其卓越的学习与迁移能力。在这个过程中,研究者们发现通过不断地扩大模型参数便能持续提升深度学习模型的威力。然而,参数的指数级增长意味着模型体积增大、所需计算资源增多、计算耗时更长,而这无论出于业务线上响应效率的要求还是机器资源预算问题,

手机端侧文字识别:挑战与解决方案
在手机端侧实现文字识别,考虑资源限制和效率至关重要。 1.图像处理 在手机端侧进行图像预处理,必须精细权衡资源消耗与效果。 其中,快速灰度化是首步,它使用像素加权法(如YUV转换)将彩色图像转化为黑白,目的是减少数据维度,加速后续处理。 紧接着,自适应二值化如Otsu's方法或高斯自适应方法被应用,特别针对存在不均匀光线的图片,可以明显增强文字与背景的对比度。对于高分辨率图像,降采样是必要

AI端侧落地,京东AI技术如何部署边缘?
导语:随着物联网的快速发展,越来越多的用户希望将 AI能力下沉到边缘层,让边缘设备能够自动处理关心的一些数据,再把结果上报到云平台。这样做既节省了资源,又提高了运算效率。 随着技术进步,手机等移动设备已成为非常重要的本地深度学习载体,然而日趋异构化的硬件平台和复杂的终端侧的使用状况,让AI技术在端侧的应用能力颇受挑战。端侧模型的推理往往面临着算力和内存的限制,为了能够完整的支持众多硬件