本文主要是介绍端侧AI-58同城Android部落帖子重排实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 需求方案设计
利用手机端的运算能力,进行实时推荐。点击回退列表场景下,用端上的压缩模型对已下发的推荐结果,进行实时重排序。
1.1 模型 AB Test、热更新、下载
一级页加载首页数据时,算法后端服务器下发当前用户的模型 modelJson 数据:
{"scene" : 1,"modelUrl": "https://58cdn.com.cn/xxx/1/modelandConfig.zip", // tflite模型+对应的配置文件远程地址的地址"version": "20210825cg422", // string, 模型版本号,同时是ab test 号"md5": "xgiegk2k324" // 文件的md5, 下载后校验比对
}
server 的模型是如何而来的呢?
我们前期对部落用户行为特征进行了埋点上报,包括:
| # | 特征 |
|---|---|
| 1 | 进入页面时间戳 |
| 2 | 退出页面时间戳 |
| 3 | 点赞行为 |
| 4 | 是否点击收藏 |
| 5 | 评论帖子行为 |
| 6 | 是否播放视频 |
| 7 | 点开大图浏览 |
| 8 | 是否点击相关推荐 |
| 9 | 是否上下回滚 |
| 10 | 滚动次数 |
| 11 | 分享帖子行为 |
| 12 | 赞赏作者行为 |
| 13 | 认可标签行为 |
| 14 | 取消认可标签行为 |
| 15 | 点击关注行为 |
| 16 | 点击进入作者个人主页 |
| 17 | 举报作者行为 |
| 18 | 点击话题 |
| 19 | 是否点击部落 |
| 20 | 是否点赞评论 |
| 21 | 是否取消点赞评论 |
| 22 | 评论曝光条数 |
| 23 | 举报评论行为 |
算法同学会对上报的数据进行加工训练,形成特定的特征模型。
1.2 数据预处理
由于 TensorFlow Lite 的 select 库在 Android 上为 8M,在 iOS 上达到 100M,所以最终我们选择自己实现算法侧需要的 Bucketize、LabelEncoder 算法,对数据进行预处理
internal object TensorflowSelects {const val DEF_INPUT_VAL = Int.MIN_VALUEprivate const val DEF_VAL = 0/*** Returns the indices of the buckets to which each value in the input belongs,* where the boundaries of the buckets are set by boundaries.* Return a new tensor with the same size as input.* If right is False (default), then the left boundary is closed.* More formally, the returned index satisfies the following rules.*/fun bucketize(input: FloatArray? , boundaries: Array<Float>?): IntArray? {if (input == null || input.isEmpty() || boundaries == null || boundaries.size < 2) {return null}val len = input.sizeval result = IntArray(len)for (i in 0 until len) {val boundariesLen = boundaries.sizeresult[i] = boundariesLenif (input[i] == DEF_INPUT_VAL.toFloat()) {result[i] = DEF_VAL} else {for (j in 0 until boundariesLen) {if (input[i] < boundaries[j]) {result[i] = jbreak}}}}return result}/*** 整形类型特征 - labelEncoder*/fun labelencoder(input: IntArray? , dic: IntArray?): IntArray? {if (input == null || input.isEmpty() || dic == null || dic.isEmpty()) {return null}val len = input.sizeval result = IntArray(len)for (i in 0 until len) {var index = DEF_VALif (input[i] != DEF_INPUT_VAL) {val len1 = dic.sizefor (j in 0 until len1) {if (dic[j] == input[i]) {index = jbreak}}}result[i] = index}return result}
}
原始数据:
{"last_click": {"info_id": "111111","feature": {"800026": "887","220003": "1389","220010": "1",..."220001": "22","800039": "0.318"}},"resort_list": [{"info_id": "222222","feature": {"800024": "1366","220003": "1028","800028": "900000003",..."800019": "-1","220001": "8","800039": "0.318"}}, {"info_id": "333333","feature": {"800026": "887","220003": "576","800037": "0.215",..."800028": "900000003","220001": "7","800039": "0.318"}}]
}
经过特征组装、特征 field 改名、 配置文件解析、特征工程预处理,最终得到如下输入特征值(以下是待预测的两条数据):
{"l300017": [0, 0],..."f211014": [1, 4],"f300002": [0, 0],..."d14": [0, 0],"d15": [0, 0],"d16": [0, 0],..."d19": [0, 0],"f220107": [2, 2],..."l300014": [0, 0],"f210003": [0, 0],"f211011": [1, 3]
}
1.3 模型加载
传入模型的本地路径,初始化模型解释器 Interpreter
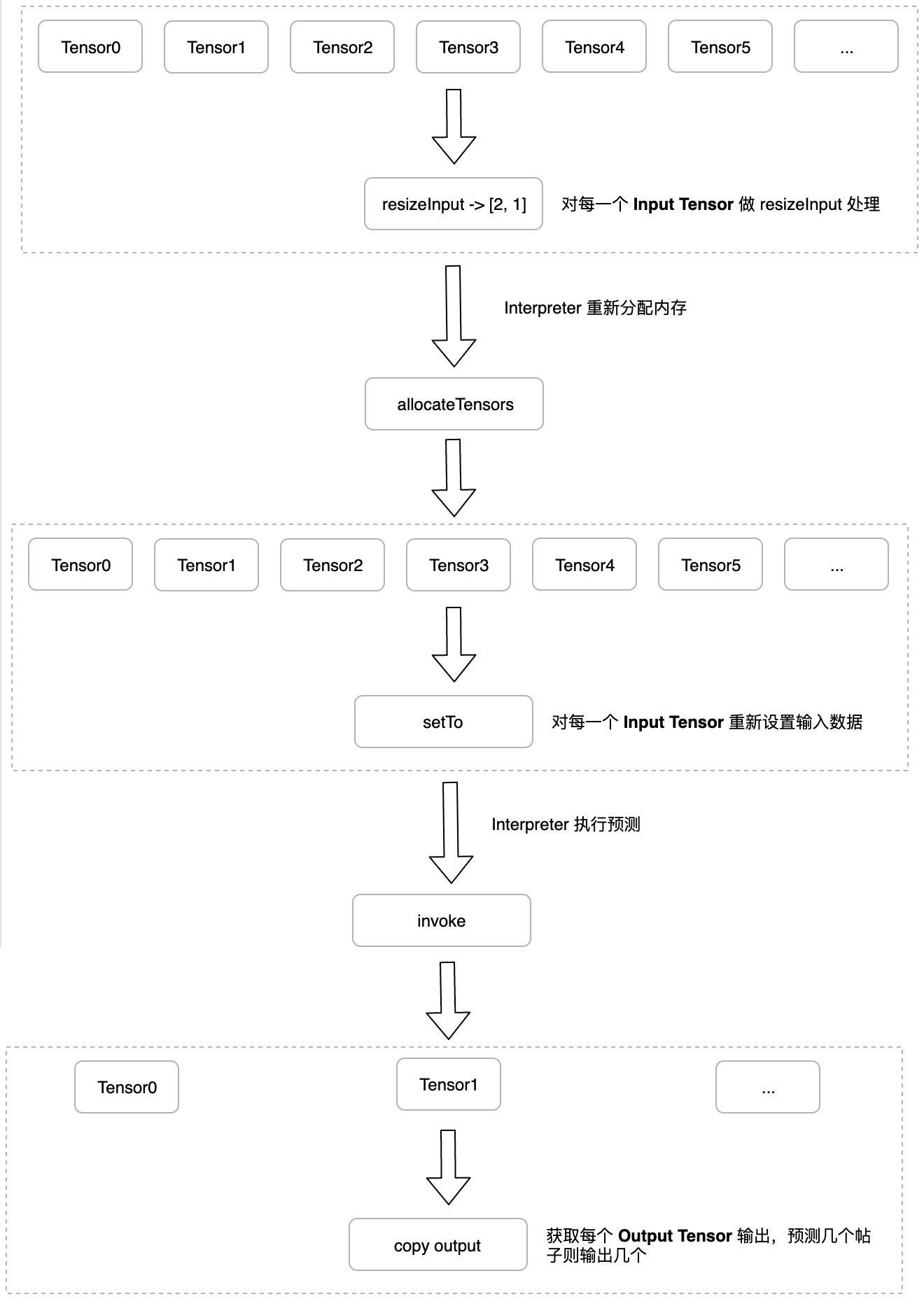
1.4 解释器针对每一个 inputTensor 执行 resizeInput
由于是由客户端自行通过算法处理数据,可能和模型预置的输入参数纬度不一致,所以需要进行 resizeInput 操作 (模型的输入是多个 Tensor 对象,输出也是多个 Tensor 对象):
- 遍历 interpreter.inputTensorCount
- 对每一个 index,取出 inputTensor;
- 从 inputTensor 中取出 inputTensor.name --> field;
- 根据 field 从输入的特征值拿到输入,例如遍历的 index=0,对应 field=d0,则输入为 [1,1]
- 把输入转换为 Data,注意这里不要有 JSON API,要保持数据对齐;
- 调用 interpreter.resizeInput 方法,把输入的 shape 传入到对应 index 的 inputTensor 中
以下是 iOS 端的代码实现,仅供参考:
for index in 0 ..< allFeatureCount {guard let inputTensor : Tensor = try self.interpreter?.input(at: index) else {finished([])return}let field : String = inputTensor.nameguard let itemInput : [Int64] = input[field] as? [Int64] else {finished([])return}let dimensions = [itemInput.count, 1]let shape = Tensor.Shape(dimensions)let inputData = Data(copyingBufferOf: itemInput)let tensor = Tensor(name: field,dataType: .int64,shape: shape,data: inputData,quantizationParameters: nil)try self.interpreter?.resizeInput(at: index, to: tensor.shape)
}
1.5 重新分配内存
解释器 allocateTensors:
以下是 iOS 端的代码实现,仅供参考:
// Allocate memory for the model's input `Tensor`s.
try self.interpreter?.allocateTensors()
1.6 Copy the input data to the input Tensor
把特征向量转换后的 Data 传入到解释器的每一个 inputTensor:
以下是 iOS 端的代码实现,仅供参考:
for index in 0 ..< allFeatureCount {guard let inputTensor : Tensor = try self.interpreter?.input(at: index) else {finished([])return}let field : String = inputTensor.namelet itemInput : [Int64] = input[field] as! [Int64]let inputData = Data(copyingBufferOf: itemInput)// Copy the input data to the input `Tensor`.try self.interpreter?.copy(inputData, toInputAt: index)
}
1.7 执行预测
以下是 iOS 端的代码实现,仅供参考:
// Run inference by invoking the `Interpreter`.
try self.interpreter?.invoke()
1.8 得到预测结果 outputTensor
以下是 iOS 端的代码实现,仅供参考:
// Get the output `Tensor`
let outputTensor = try self.interpreter?.output(at: 0)// Copy output to `Data` to process the inference results.
let outputSize = outputTensor?.shape.dimensions.reduce(1, {x, y in x * y})
let outputData = UnsafeMutableBufferPointer<Float32>.allocate(capacity: outputSize!)
outputTensor?.data.copyBytes(to: outputData, count: 1)
得到类似如下的分数:
[0.25,0.15]
最后回传给 js 端,让部落 js 业务对帖子进行重排
2. Android 端实现
这边我们只贴出最核心的推断逻辑
2.1 躺坑 - 按照 iOS 流程照猫画虎
发现 Android 除了获取 inputTensor、resizeInput、allocateTensors 和 iOS API 类似外,其他拷贝输入、预测执行、获取输出的 public API 都没有,而且执行预测还必须传入输入输出:
但是发现了和 iOS 类似的剩余几个 API,包括设置输入数据、获取输出,但 API 都不是 public:
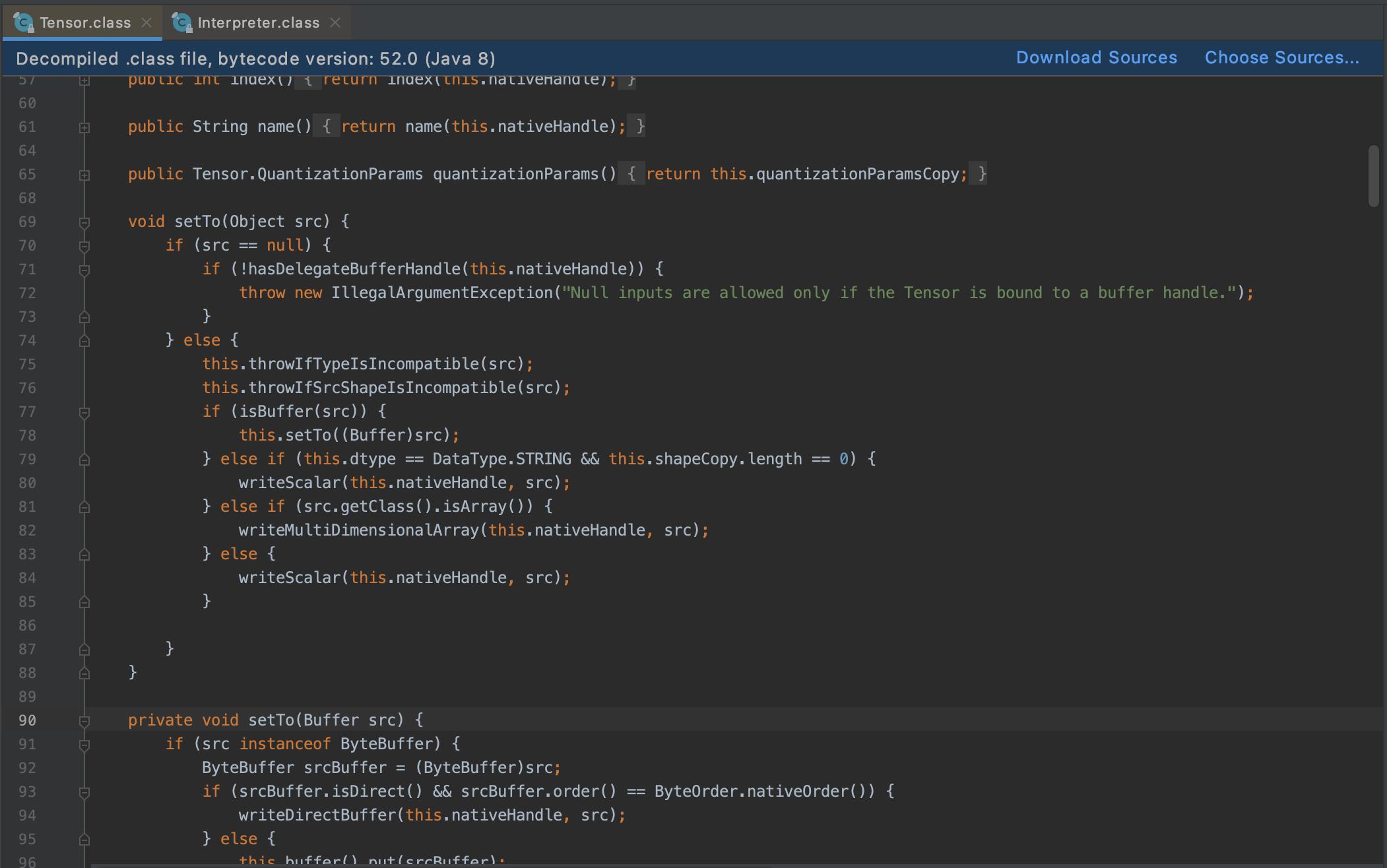
尝试反射调用?
val interpreter: Interpreter = TensorflowProvider.getInstance(applicationContext).getTFLite()// resizeInputval inputTensorCount = interpreter.inputTensorCountLog.i("tony" , "inputTensorCount = $inputTensorCount")val interpreterInput: MutableList<Array<Long?>> = ArrayList()for (i in 0 until inputTensorCount) {val inputTensor = interpreter.getInputTensor(i)val field = inputTensor.name().replace("serving_default_" , "").replace(":0" , "")val itemInput = arrayOfNulls<Long>(2)trainData.optJSONArray(field)?.let {val length = it.length()for (j in 0 until length) {itemInput[j] = it.getLong(j)}}interpreterInput.add(itemInput)val dims = intArrayOf(itemInput.size , 1)try {interpreter.resizeInput(i , dims)} catch (e: Throwable) {Log.i("tony" , "resizeInput err = " + e.message)}}// allocateTensorsinterpreter.allocateTensors()var tensorClz: Class<*>? = nulltry {tensorClz = Class.forName("org.tensorflow.lite.Tensor")} catch (e: Exception) {}// setTo inputvar setToMethod: Method? = nulltry {setToMethod = tensorClz?.getDeclaredMethod("setTo" , Object::class.java)setToMethod?.isAccessible = true} catch (e: Exception) {Log.i("tony" , "reflect org.tensorflow.lite.Tensor.setTo err = " + e.message)}for (i in 0 until inputTensorCount) {val inputTensor = interpreter.getInputTensor(i)try {Log.i("tony" , "setTo = " + Arrays.toString(interpreterInput[i]))setToMethod?.invoke(inputTensor , interpreterInput[i])} catch (e: Throwable) {Log.i("tony" , "setTo err = " + e.message)}}// runtry {val interpreterClz = Class.forName("org.tensorflow.lite.Interpreter")val wrapperField = interpreterClz.getDeclaredField("wrapper")wrapperField.isAccessible = trueval wrapper = wrapperField.get(interpreter)val nativeInterpreterWrapperClz = Class.forName("org.tensorflow.lite.NativeInterpreterWrapper")val runMethod = nativeInterpreterWrapperClz.getDeclaredMethod("run" , Long::class.java , Long::class.java)runMethod.isAccessible = trueval interpreterHandleField = nativeInterpreterWrapperClz.getDeclaredField("interpreterHandle")interpreterHandleField.isAccessible = trueval errorHandleField = nativeInterpreterWrapperClz.getDeclaredField("errorHandle")errorHandleField.isAccessible = truerunMethod.invoke(wrapper , interpreterHandleField.get(wrapper) , errorHandleField.get(wrapper))} catch (e: Throwable) {Log.i("tony" , "run err = " + e.message)}// handle outputval outputTensorCount = interpreter.outputTensorCountLog.i("tony" , "outputTensorCount = $outputTensorCount")var refreshShapeMethod: Method? = nulltry {refreshShapeMethod = tensorClz?.getDeclaredMethod("refreshShape")refreshShapeMethod?.isAccessible = true} catch (e: Exception) {Log.i("tony" , "reflect org.tensorflow.lite.Tensor.refreshShape err = " + e.message)}for (i in 0 until outputTensorCount) {val outputTensor = interpreter.getOutputTensor(i)try {refreshShapeMethod?.invoke(outputTensor)} catch (e: Throwable) {Log.i("tony" , "refreshShape err = " + e.message)}}// copy outputvar copyToMethod: Method? = nulltry {copyToMethod = tensorClz?.getDeclaredMethod("copyTo" , Any::class.java)copyToMethod?.isAccessible = true} catch (e: Exception) {Log.i("tony" , "reflect org.tensorflow.lite.Tensor.copyTo err = " + e.message)}for (i in 0 until outputTensorCount) {val outputTensor = interpreter.getOutputTensor(i)try {val output = FloatArray(1)copyToMethod?.invoke(outputTensor , output)Log.i("tony" , "output = " + Arrays.toString(output))} catch (e: Throwable) {Log.i("tony" , "copyTo err = " + e.message)}}
出现内存分配异常、输入与 shape 无法对应、执行结果为 NAN 等各种异常,且官方文档对这块的资源非常少。
2.2 曙光 - read source code
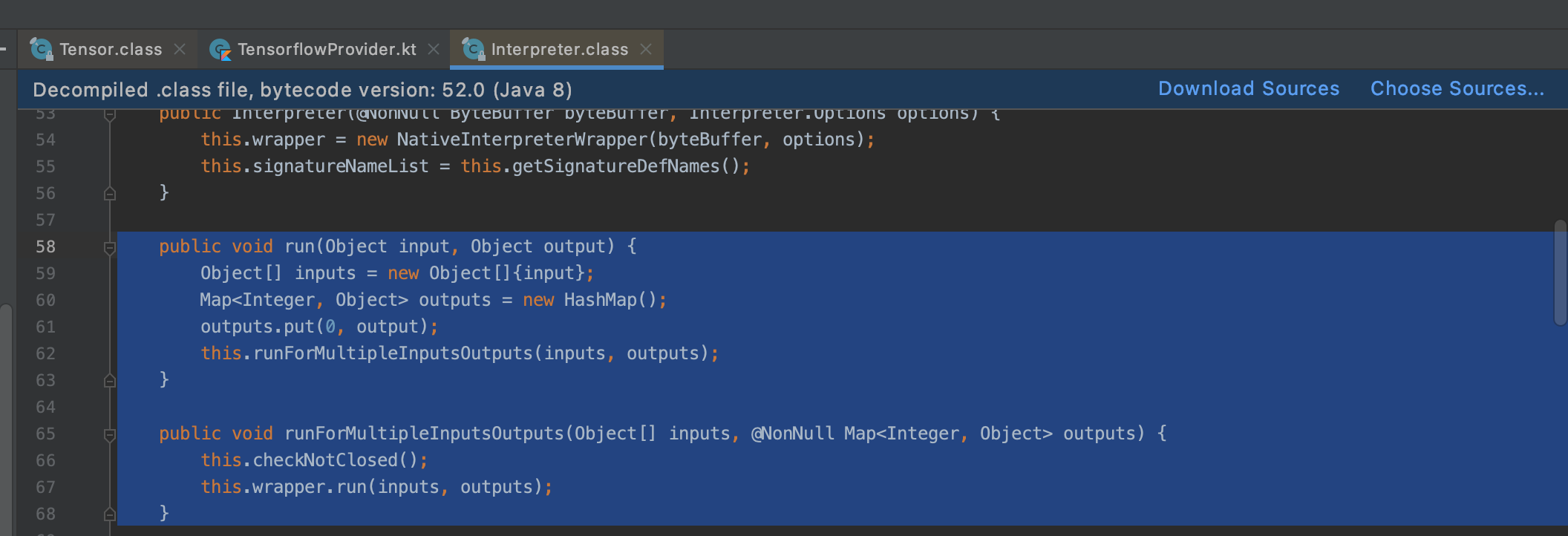
调不通不要怕,读源码一步步 debug 断点调试,从 Interpreter.run() 开始:
public void run(Object input, Object output) {Object[] inputs = new Object[]{input};Map<Integer, Object> outputs = new HashMap();outputs.put(0, output);this.runForMultipleInputsOutputs(inputs, outputs);}public void runForMultipleInputsOutputs(Object[] inputs, @NonNull Map<Integer, Object> outputs) {this.checkNotClosed();this.wrapper.run(inputs, outputs);}
进入 org.tensorflow.lite.NativeInterpreterWrapper.run(),发现了新大陆,果然是 google 亲儿子:
void run(Object[] inputs, Map<Integer, Object> outputs) {if (inputs != null && inputs.length != 0) {if (outputs != null && !outputs.isEmpty()) {// 检测每个输入 Tensor 是否需要重新 resizeInputfor(int i = 0; i < inputs.length; ++i) {Tensor tensor = this.getInputTensor(i);// 计算输入需要的张量纬度,如果和模型中的不一致,则 resizeInput int[] newShape = tensor.getInputShapeIfDifferent(inputs[i]);if (newShape != null) {this.resizeInput(i, newShape);}}boolean needsAllocation = !this.isMemoryAllocated;// 如果有 resizeInput 操作,则重新申请内存if (needsAllocation) {allocateTensors(this.interpreterHandle, this.errorHandle);this.isMemoryAllocated = true;}// 给每一个输入 Tensor 设置数据for(int i = 0; i < inputs.length; ++i) {this.getInputTensor(i).setTo(inputs[i]);}// 执行预测run(this.interpreterHandle, this.errorHandle);// 如果有 resizeInput 操作,则重新设置输出 Tensor 的 shapeif (needsAllocation) {for(int i = 0; i < this.outputTensors.length; ++i) {if (this.outputTensors[i] != null) {this.outputTensors[i].refreshShape();}}}// 将输出 buffer 进行拷贝Iterator var13 = outputs.entrySet().iterator();while(var13.hasNext()) {Entry<Integer, Object> output = (Entry)var13.next();this.getOutputTensor((Integer)output.getKey()).copyTo(output.getValue());}this.inferenceDurationNanoseconds = inferenceDurationNanoseconds;} else {throw new IllegalArgumentException("Input error: Outputs should not be null or empty.");}} else {throw new IllegalArgumentException("Input error: Inputs should not be null or empty.");}}
这不是完全已经封装好了?
2.3 尝试直接将输入数据进行预测
(1) 尝试直接传入 Arrays(long[]) 进行预测,发现输入与 shape 对应不上
(2) 将输入数据转换成 Arrays(LongBuffer) 进行预测,断点调试发现内部重新进行了 resizeInput 操作,但是新的 input shape 为 [2],我们预期的为 [2, 1],得到的预测结果为 [NAN, NAN]
(3) 查看重新计算 shape 的源码,发现输入是二维数组,则新的输入 shape 为 [2, 1],但由于输入做了二维包装,最终获取的预测结果为 [0.0, 0.0]
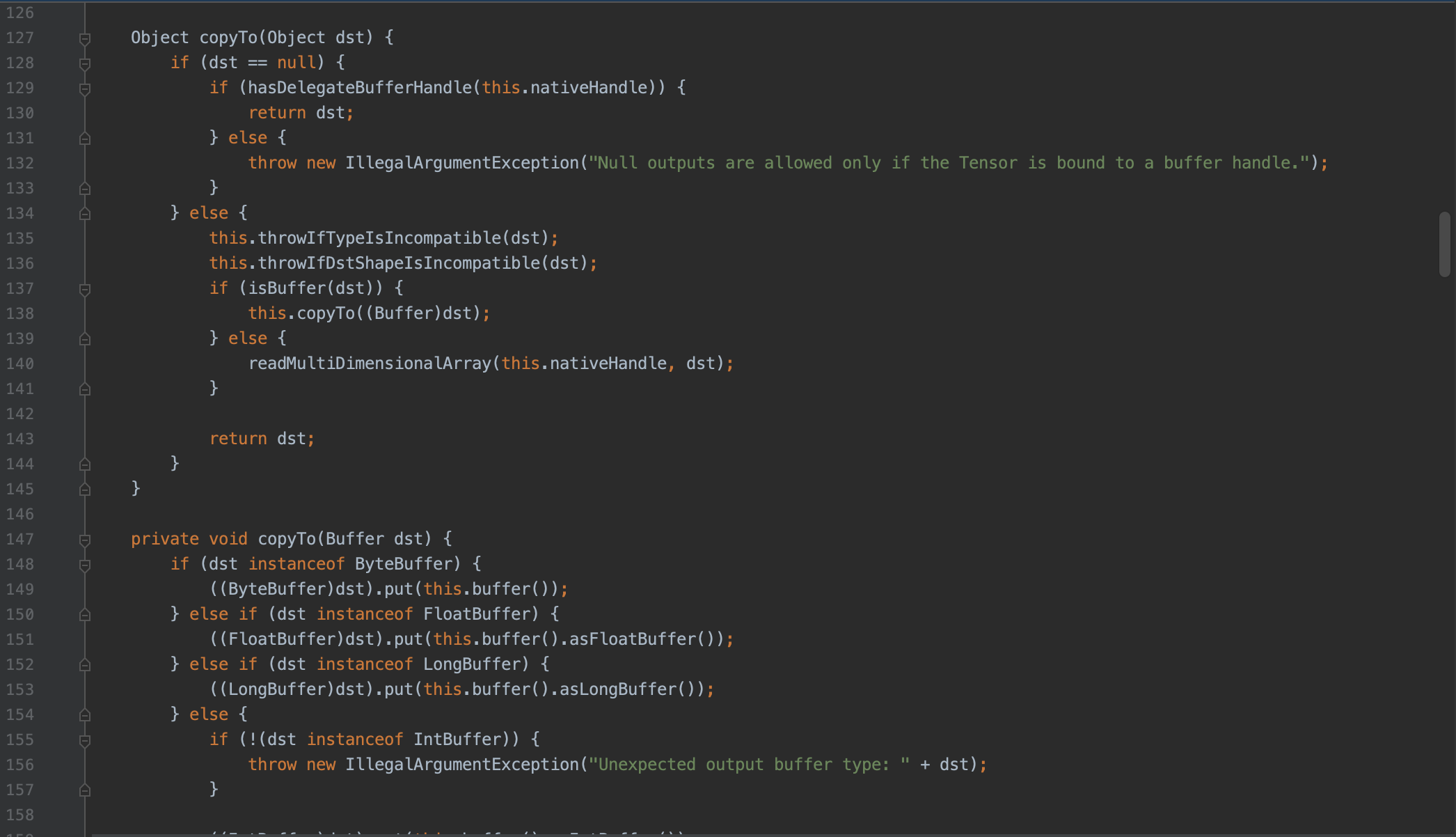
2.4 破案
那能不能外部先对每一个 Input Tensor 做 resizeInput([2, 1]) 操作,然后再调用 run 呢?试水一波,毫无疑问,run 内部又重新 resizeInput 到 [2] 了,继续看源码:
int[] newShape = tensor.getInputShapeIfDifferent(inputs[i]);
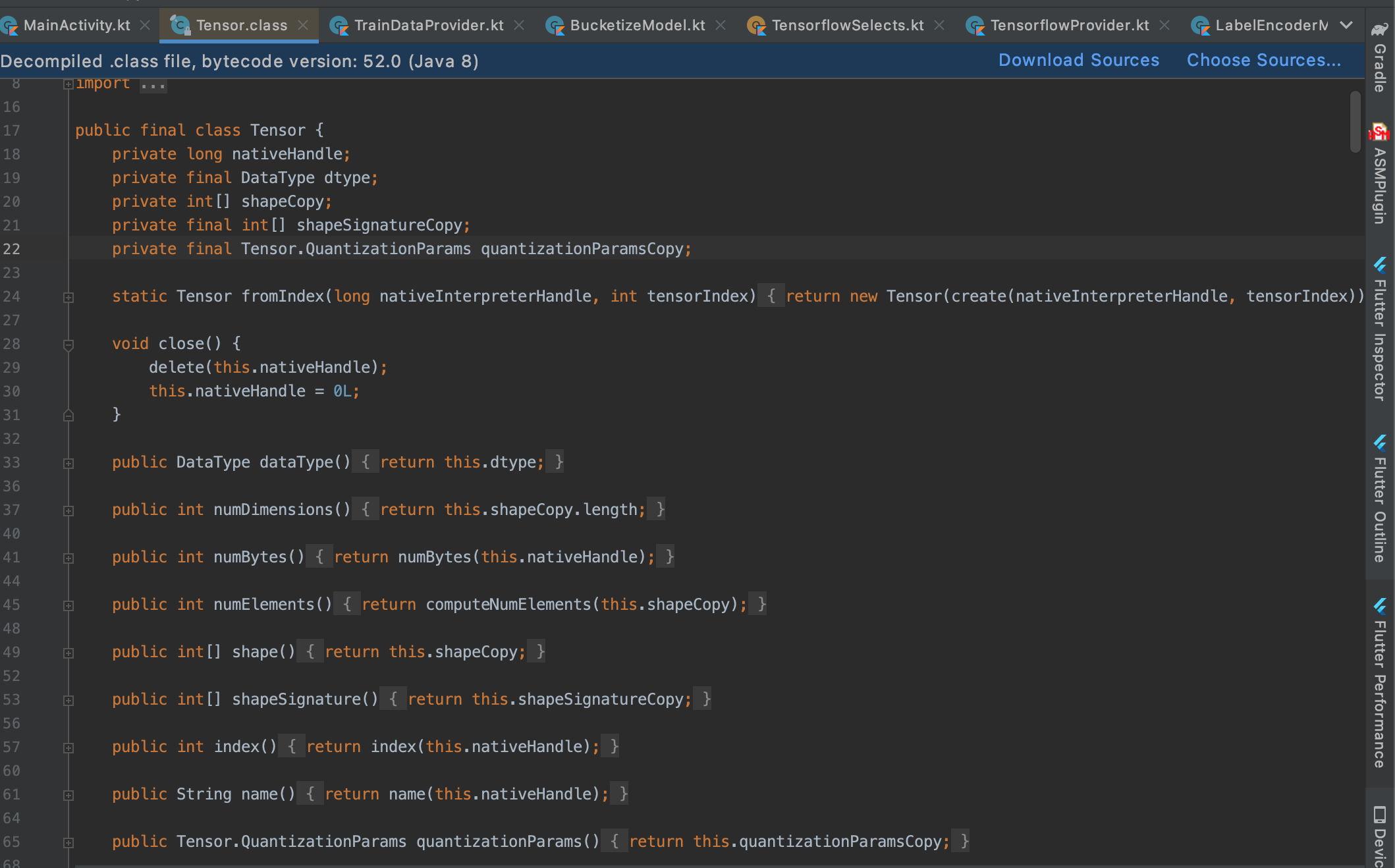
-> Tensor.class
int[] getInputShapeIfDifferent(Object input) {if (input == null) {return null;} else if (isBuffer(input)) {return null;} else {this.throwIfTypeIsIncompatible(input);int[] inputShape = this.computeShapeOf(input);return Arrays.equals(this.shapeCopy, inputShape) ? null : inputShape;}}
可以看到如果传入的是 Buffer 类型,则不会重新生成 shape,最终调通代码为:
fun doInterpreter(trainData: TrainData): FloatArray? {try {val interpreter = getTFLite()val inputTensorCount = interpreter.inputTensorCountLog.i("tony" , "inputTensorCount = $inputTensorCount")val interpreterInput: MutableList<LongBuffer> = ArrayList()for (i in 0 until inputTensorCount) {val inputTensor = interpreter.getInputTensor(i)val field = inputTensor.name().replace(":0".toRegex() , "")val fieldData = trainData.raw.optJSONArray(field)val len = fieldData?.length() ?: 2val itemInput = LongArray(len)if (fieldData != null) {for (j in 0 until len) {itemInput[j] = fieldData.optLong(j)}} else {Arrays.fill(itemInput , 0L)}// 使用 Buffer,这样 run 内部不会重新 resize 校正interpreterInput.add(LongBuffer.wrap(itemInput))// 一定要手动 resizeinterpreter.resizeInput(i , intArrayOf(len , 1))}val output: MutableMap<Int , Any> = HashMap()// 输出为帖子的数量val outputBuffer = FloatBuffer.allocate(trainData.outputCounts)outputBuffer.order()output[0] = outputBufferinterpreter.runForMultipleInputsOutputs(interpreterInput.toTypedArray() , output)return outputBuffer.array()} catch (e: Throwable) {Log.i("tony" , "doInterpreter error = ${e.message}")return null}}
3. Tensorflow lite 冲突问题
集成到 58App 时,遇到了 Tensorflow lite 冲突问题,58App 10.23.0 Android 端侧重排需求 (该需求 iOS 在上个版本已上线),在端侧基于用户行为对部落帖子进行重排,基于 Tensorflow lite 标准库 2.3.0、2.5.0 可正常运行。而 58App 中,信安 SDK 已存在一套自编译裁剪的 Tensorflow lite 库,使用该库无法加载端侧重排的模型。
标准库:
org.tensorflow:tensorflow-lite:xxx
信安剪裁库:
com.wuba.xxzl:tensorflow:xxx
3.1 前期调研、沟通结论
| 方案 | 结论 | |
|---|---|---|
| 1 | 算法侧对重排模型做适配 | 无法适配,裁剪库缺少很多基本 op |
| 2 | 和信安团队沟通 | 信安基于 58App、安居客两个的平台包大小压力,对标准的 Tensorflow lite 库做了裁剪 |
| 3 | 关于 iOS | 信安 SDK iOS 侧还未提供 Tensorflow lite 相关的能力 (正在开发中),目前 58App iOS 侧端侧重排需求已使用标准的 Tensorflow lite 上线,后期也会存在同样的问题 |
结论:
- 算法侧无法使用裁剪库适配模型,并且基于后期业务考虑,需要将 Tensorflow lite 库列入基础库管理标准
- 信安侧升级到标准库的难点在于 58App、安居客的包大小压力
- 信安 iOS 侧后期将支持 Tensorflow lite 能力,和已上线业务也将会存在同样的问题
3.2 包大小测试
以下数据基于 58App Android 10.23.0 release 包 (v7a) 产出:
| 库 | Apk 大小 | |
|---|---|---|
| 1 | com.wuba.xxzl:tensorflow:1.0.1 | 110.3 M |
| 2 | org.tensorflow:tensorflow-lite:2.3.0 | 110.8 M |
| 3 | org.tensorflow:tensorflow-lite:2.5.0 (最新版) | 110.9 M |
最终通过数据推动信安侧去升级为标准 Tensorflow lite 库
4. 模型大小优化
端上重排模型和端上特种中心添加了更多端上特征,模型复杂度显著增大,新模型大小从 10M 以内 --> 50M+ ,模型太大影响流量下载速度,而且未来迭代模型会继续增大,需要在使用复杂模型的时候同时控制模型大小。
方案:模型拆分,云端相结合,更多的输入数据处理交由云端。
5. 效果数据
点击回退列表的ctr相对提升7.9%,uvctr相对提升15.34%;feed流整体ctr相对提升2.77%,uvctr稳定(回退推荐场景不涉及整体uvctr提升)
这篇关于端侧AI-58同城Android部落帖子重排实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




