本文主要是介绍Marginal Contrastive Correspondence for Guided Image Generation(MCL-Net)论文翻译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:https://arxiv.org/abs/2204.00442
摘要
基于范例的图像翻译在来自于不同域的条件输入和范例图像之间建立密集的对应关系,旨在使用详细的范例风格实现真实的图像翻译。现有的研究通过最小化两个域的特征集距离,隐式的建立跨域对应。然而,这些方法由于没有明确利用域不变特征,因此可能不能有效减小域间隔,从而导致经常出现次优的对应和图像翻译。我们设计了一个边缘对比学习网络(Marginal Contrastive
Learning Network , MCL-Net),它探索使用对比学习为真实的基于范例的图像翻译学习域不变特征。具体来说,我们设计了一个新的域边缘对比损失,显式的指导密集对应关系的建立。然而,仅使用域不变语义建立对应关系可能会削弱纹理模式,导致纹理生成降级。因此,我们设计了一个自对应映射(Self-Correlation Map , SCM),它以场景结构作为辅助信息,极大的改善了对应关系的建立。我们针对各种图像翻译任务,进行了定量和定性实验,实验结果证明该方法的优越性与有效性。
引言
图像翻译是指以其他领域的特定输入为特定条件生成图像,随着GANs的生成出现,该方面的研究已经取得了显著的成就。作为一个典型的不适定问题,随着一个条件输入可以对应多个图像范例,多样的解决方案自然的应用于图像翻译任务。对生成风格的如实控制不仅可以在一定条件下实现多样化生成,而且可以实现用户灵活的控制所所需生成。但是,生成具有可靠风格的高保真图像仍然面临巨大的挑战。
为了解决风格控制的挑战,一个主要的方法是使用变分编码器,将图像风格正则化为高斯分布,就像SPADE做的一样,但是由于VAEs的后验崩塌现象,该方法经常面临生成质量不高的问题。另一个方向是使用从示例中提取的风格指导生成。例如,Zhu等人提出,为每个语义区域使用专门的放个编码,实现风格控制。但是潜码通常使用风格编码器提取,它一般只反映出全局风格,很难捕获详细结构。直到最近,基于范例的图像翻译任务在密集对应方面进行积极的探索,并成为了很有前途的实现如实风格控制的方法。具体来说,Zhang等人提出了在条件输入和给定范例之间建立密集语义,以此为翻译过程提供风格指导。Zheng和CoCosNet v2通过PatchMatch在高分辨率特征中建立密集语义对应关系,进一步加强了风格细节的保存。Zhan等人引入了一个通用的图像翻译框架,它包含了两个输入之间的特征对齐的最佳传输。对于不同域之间的匹配问题,建立对应的关键在于如何有效的学习域不变特征推动合适的匹配。然而,前面所提到的方法都是最小化条件特征和真实特征之间伪范例对损失和L1损失,隐式的对齐域间隔以建立对应关系,它们没有明确的建立域不变特征,可能会产生次最佳的特征对应。
在本文中,我们提出了边缘对比学习网络(Marginal Contrastive Learning Network , MCL-Net),引入了对比学习有效的提取域不变特征,用以建立域对应关系,如图1所示。特别的,对比学习应用于由不同编码器提取的条件输入和真值的特征。将每个输入特征看作一个锚点(anchor),将同一空间位置的特征向量看作正样本,剩余的特征作为负样本。通过最大化条件特征和图像特征的交互信息,对比学习可以明确的生成域不变特征。此外,本文提出了边缘对比损失(marginal contrastive loss ,MCL)增强域不变特征的辨别性,这可以有效控制过度平滑或不准确的对应。MCL的偏差角对对保存边缘的正锚点起惩罚作用。
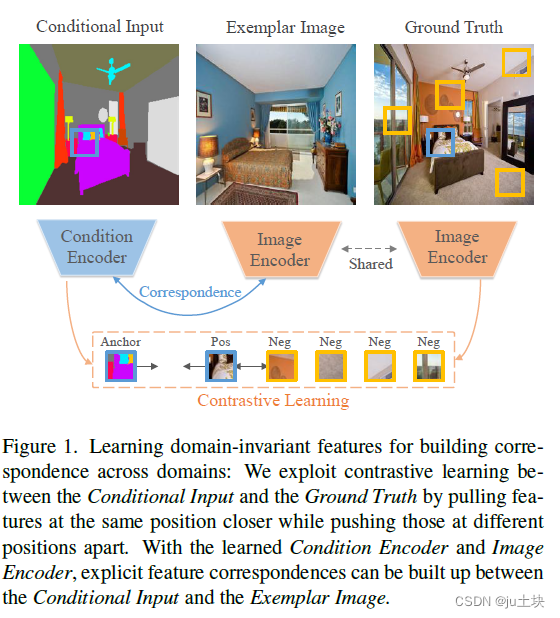
另一方面,先前建立对应关系的方法大多是在不了解场景结果的情况下,依靠相应的局部特征建立对应关系。它意味着,在建立对应关系时,场景结构是不匹配的,这将导致扭曲的纹理图案和退化的生成效果。因此,应该使用场景结构,如物体外形来促进对应关系的建立,特别是精细纹理图案的保存。我们观察到自监督映射甚至能即使在外观变化的情况下也能编码完整的图像结构,首次启发,我们设计了自相关映射机制(selfcorrelation map ,SCM),显示的表示与特征相关的场景结构,有效的推动特征的建立。
本文的贡献可以总结为3个方面。
- 在基于范例的图像翻译框架中引入了对比学习,明确的学习域不变特征,以建立对应关系。
- 提出了一种显得边缘对比损失,增强表示空间中的特征识别力, 有利于具体准确的对应关系的建立;
- 设计了一个自相关映射,以正确的表示场景结构,并在建立对应关系的同时,有效的促进纹理模式的保存。
相关工作
Image-to-Image Translation
Contrastive Learning
近年来对比学习已经在各种计算机视觉任务中展示除了他的有效性。其主要思想是通过将正样本拉到锚点附近,将负样本推开,来学习表示。在各种后阶段的会谈中,广泛探讨了不同的采样策略和对比损失。例如,chen和he通过增强原始数据获得正样本;tian等将同一样本的不同视图看作正对。在InfoNCE顶部,Park等人引入了PatchNCE,在未配对的图像翻译任务中采用对比学习,他将图像patch看作样本。在本研究中,基于InfoNCE设计了新的边缘对比损失。有效的提高了域不变特征的辨识性。
提出的方法
整个模型框架如图2所示,对比网络使用提出的边缘对比学习提取域不变特征以建立对应关系,这也进一步使用它扭曲到与条件输入对齐。在扭曲示例和条件输入的指导下,生成网络生成最后的结果。
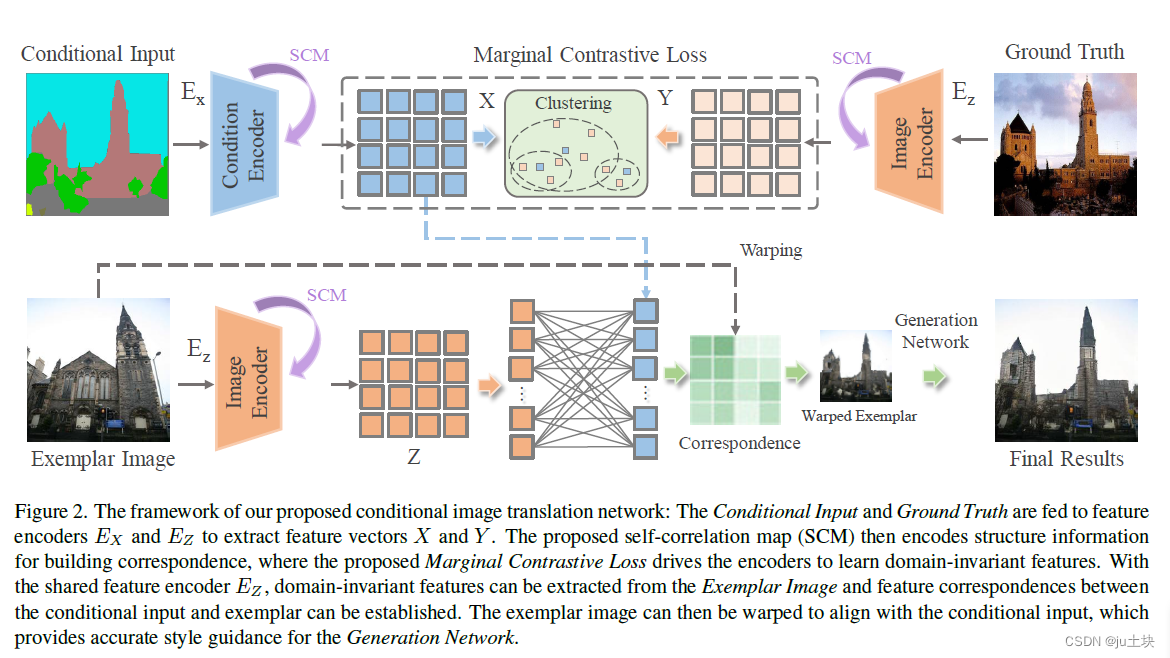
Correspondence Network
分别使用两个编码器编码输入图片(条件输入,示例&真值图片)。通过计算特征级的余弦相似度,建立两个编码特征中的对应关系 。
过去的方法是使用伪范例对损失和L1损失推动编码器学习,但是前者不能明确的鼓励域不变特征的学习,后者仅简单最小化相同空间位置的特征距离,忽略了不同位置的特征间的距离。因此引入对抗损失。
Contrastive Correspondence
对比学习是无监督表示学习的有利工具。为了指导positive和negative对进行对比学习,将真值图像喂入编码器Ez中,获得编码特征y;将条件图像的特征x作为锚点,则对应的特征y是正例,其他N-1个特征是反例。我们将向量归一化都一个单位球面上,防止空间崩塌或膨胀。然后,使用噪声对比估计框架指导两个输入之间的对比学习:
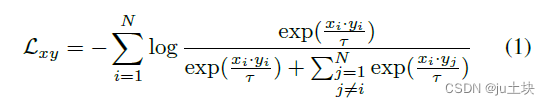
Marginal Contrastive Learning :
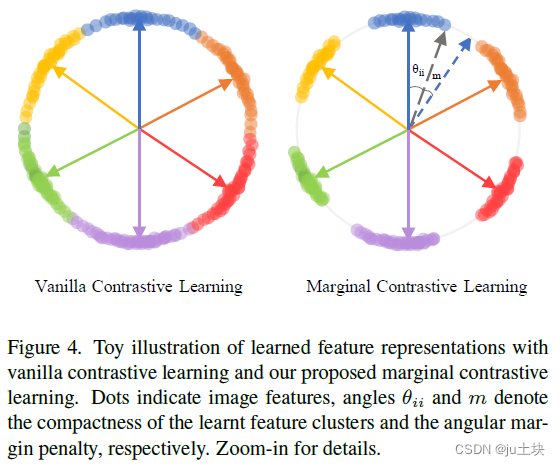
对比学习能够编码域不变特征,而在两组特征之间建立准确的对应关系需要特征间的高辨识度。原来的对比训练趋向于在不同的特征簇中产生平滑的转换,这可能会带来平滑和不稳定的对应关系。受到ArcFace中加性角边缘损失,我们提出了边缘对比损失来扩大超球面上特征的可分性,这产生更明确精准的对应关系,如图3所示。

具体来说,由于建立对应关系的特征是归一化后的,因此公式1中可以被重写为
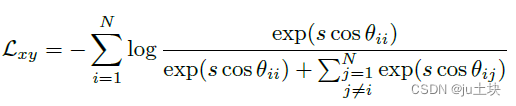
因此,嵌入特征以s为半径,分布在超球面上每个特征中心周围。为了同时增强类内紧凑性和类间差异,我们将一个角边缘惩罚(m)加到正样本上,形成如下的边缘对比损失:
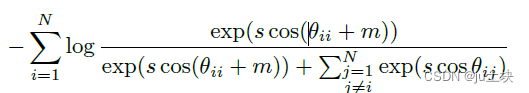
所提出的MCL在归一化超平面上加入角边缘惩罚,有效的扩大了图正的可分性,如图4所示:
Self-Correlation Map
过去研究在不知道场景结构的前提下,依赖对应的局部特征建立对应关系。然而,完全依赖局部特征建立对应会损害图像的纹理特征,导致生成结构的降级。直观上来说,除了局部特征,场景结构也可以作为辅助信息,以保留纹理,促进对应关系的建立。因此,本模型在对应网络中引入了自相关映射(SCM),使用场景结构建立对应关系。
由于同一类别的所有区域都表现出了某种形式的自相关,特征自相关映射有效的编码了完整的物体形状,如图5所示。通过估计每个空间位置的这些特征的共性,可以显式的表示出所有位置的场景结构。因此,给定编码特征X, 一个特征的自相关映射为:
![]()

与编码风格和纹理等各种属性的原始特征不同,自相关映射只能捕获空间相关性。为了使用SCM建立对应关系,我们将64*64的SCM转换为4096的列向量,然后使用全连接层将向量维度降低到256。256维的特征与编码后的特征在对应空间位置进行拼接,来计算对应关系的余弦相似度。随着使用提出的边缘对比学习被用于学习域不变特征,对比损失函数也驱动了自相关映射的学习。
Generation Network
扭曲示例提供风格指导,条件输入提供给语义指导,生成网络旨在生成忠于范例风格和条件语义的高保真的图像。具体的网络结构与SPADE有关。
Loss Functions
对应网络和生成网络共同优化,学习跨域对应并实现高保真图像的生成。条件输入:X,真值:Y,范例图像:Z。条件编码和图像编码分别为Ex和Ez,生成器和判别器分别为G,D。
Correspondence Network
- 边缘对比损失:Lmcl
- 特征一致损失:编码器用于提取域不变特征,因此提取到的条件特征和对应的真值特征应该是一致的。
![]()
- 循环一致损失:为了保留在扭曲过程中的图片信息,使用一个相反的扭曲过程,可以将扭曲范例图像恢复为原始的示例。下面式子中,T是对应矩阵。
![]()
- 伪范例对损失:虽然收集扭曲示例的真值很难,但是我们可以将增强的显示图像作为一个范例,从而获得伪范例对损失。因此可以惩罚扭曲示例和增强的现实图像之间的差异,如下:
![]()
Generation Network
- 感知损失:最小化语义不一致性
![]()
- 上下文损失:在风格上具有一致性
![]()
- 对抗性损失
因此总损失为:
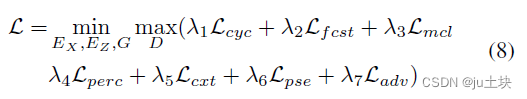
实验
总结
这篇关于Marginal Contrastive Correspondence for Guided Image Generation(MCL-Net)论文翻译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







