本文主要是介绍CMNet:Contrastive Magnification Network for Micro-Expression Recognition 阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AAAI 2023的一篇文章,东南大学几位老师的工作,用于做微表情识别中的运动增强工作, 以下是阅读时记录的笔记。

摘要:
However,existing magnification strategies tend to use the features offacial images that include not only intensity clues as inten-sity features,leading to the intensity representation deficientof credibility.In addition,the intensity variation over time,which is crucial for encoding movements,is also neglected.
现有运动增强的方法,既包含了有效线索,也包含了很多低可信度的线索。同时,强度随时间变化的特征也被忽略了。这是现有工作的缺点。
intensity clues
强度线索(Intensity Clues)指的是与微表情强度相关的信息或特征。在微表情识别中,微表情的强度通常表示表情的明显程度或者说强烈程度。
we devise an Intensity Distillation(ID)loss to acquire the in-tensity clues by contrasting the difference between frames,given that the difference in the same video lies only in theintensity.
设计了一种强度蒸馏(ID)损失,通过对比帧之间的差异来获取强度线索。假设前提是认为在同一视频中,差异主要在强度上发生。这个是所做的工作。
the intensity clues are calibrated to followthe trend of the original video.
对强度线索进行校准,以跟随原始视频的趋势。对强度的校准,也是本文的创新点之一。
due to the lackof truth intensity annotation of the original video,we buildthe intensity tendency by setting each intensity vacancy anuncertain value,which guides the extracted intensity cluesto converge towards this trend rather some fixed values.
由于原始视频缺乏真实的强度标注,我们通过将每个强度空缺设置为不确定值来构建强度趋势,从而引导提取的强度线索朝向这一趋势而不是某些固定值。这个是强度值的特点。
简介
However,a ME is localized with slightmovements and lasts only a short time,which makes itdifficult to spot and recognize.
然而,微表情的运动轻微且持续时间短,这使得难以察觉和识别。这个是微表情识别的难点。
Many MER methods adopt-ing magnification stratgies,e.g.,Eulerian motion magni-fication(EMM),Global Lagrangian motion magnification
许多MER方法采用放大策略,例如欧拉运动放大(EMM)、全局拉格朗日运动放大(GLMM)。这个是常用的运动放大方法。
Generally,the magnification strategies implemented inthese methods mainly include two ways,i.e,in the imagespace and in the feature space.
放大策略一般包含两大类分支,基于图像空间和基于特征空间。
How-ever,this strategy can not adjust the intensity informationspecific to different ME instances.
图像增强方式对微表情的强度和其他运动强度均会增强。(因为是底层数据的操作,不包含语义信息)
where the features can bedynamically changed during the training stage,thus the in-tensity clues are more applicable to different ME instances.
特征增强的优点是在训练阶段动态调整,因此可以用在不同的微表情应用上。
a feature vector,considered as a rep-resentation of intensity,is extracted independently and con-strainted by a loss,during the attenuation of which the net-work achieves intensity enhancement.
作为强度的一种表示,特征向量被独立地提取出来,并受到一个损失的约束,在这个过程中,网络实现了强度增强。这个是特征空间增强实现的过程
the fea-tures they extracted contain not only intensity clues,but alsofacial texture clues,so it is difficult to interpret whether theperformance is improved by magnifying intensity clues orother information.
他们提取的特征不仅包含强度线索,还包含人脸纹理线索,因此很难解释是否通过放大强度线索或其他信息来提高性能。这个是缺点之一,缺乏可解释性。
in the original video,the intensity changes with a certain trend over time(Liu,Zong,and Zheng 2022;Zong et al.2018),while the featuresmay be out of order under no restrictions on its tendency.
在原始视频中,强度随时间以一定的趋势变化,而特征在不限制其趋势的情况下可能会失序。感觉应该是方法不具备随时间变化的能力。
we pro-pose a novel contrastive magnification network for micro-expression recognition,which achieves coordination be-tween increasing intensity as well as confining tendency.
我们提出了一种新的用于微表情识别的对比放大网络,该网络实现了增加强度和限制趋势之间的协调。
以下是文章的两大创新点:
We propose an Intensity Distillation loss to encode ex-plicit intensity features,underpinned by the differencebetween ME frames in a video clip.
我们提出了一种强度蒸馏损失来编码显式的强度特征,其基础是视频片段中ME帧之间的差异。
We achieve intensity variation consistency by enforcinga Wilcoxon rank sum test loss,which calibrates the ex-tracted intensity clues to optimize following the built ten-dency.
我们通过执行Wilcoxon秩和检验损失来实现强度变化一致性,该损失对提取的强度线索进行校准,以遵循所构建的准则进行优化。
相关工作
this strategy only produce static images,where the degree of magnification is impossible to adjust inthe training stage,resulting in its inadaptability to differentME samples.
该策略仅产生静态图像,在训练阶段无法调整放大倍数,导致其对不同的ME样本不具有适应性。这是微表情增强前期方法(图像增强)的缺点。
These works provide novel insightsin extracting adaptive intensity clues,but is less persuasiveon the features constrainted by loss.In addition,they ne-glect the intensity variation inherent in ME videos,whichmay lead to the disorder of intensity features along the time axis.
这些工作在提取自适应强度线索方面提供了新的见解,但在损失约束的特征上缺乏说服力。此外,他们忽略了ME视频中固有的强度变化,这可能导致强度特征在时间轴上的无序性。这个是特征增强方法的缺陷。(特征空间增强的缺点)
Basically,it aimsat learning transferable representations invariant to differ-ent data augmentations
迁移学习的目标是学习对不同的数据增强具有不变性的可迁移表示
Our work aims to build the contrast betweendifferent frames to extract intensity clues.
我们的工作旨在建立不同帧之间的对比度来提取强度线索。这个是引入对比学习的意义。
In our ap-proach,we adopted this test to calibrate the extracted inten-sity clues to conform to the variation of the built prototype.
Wilcoxon Rank Sum Test的作用是检验两组样本是否属于同一个分布。在我们的方法中,我们采用了这个测试来校准提取的强度线索,以符合所建立的原型的变化。
提出的工作
这个是整个工作的框图,后面依次介绍各部分的工作。

We manage to extract the in-tensity clues through the intensity clues encoder(ICE)
提出使用强度线索编码器完成强度线索的提取。
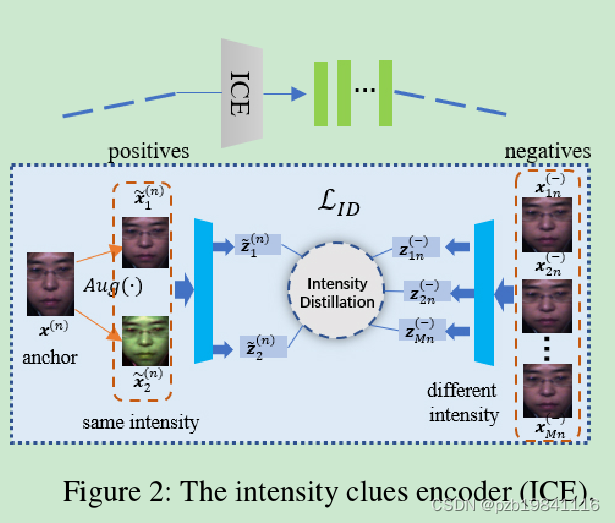

这里是为了构建正样本对。(通过图像变换获得,后面实验有介绍)
hey are chosen from the remainingframes apart from the current anchor x(n)
负样本则是从视频中其他帧中获取。
Considerating the motion variation is weak in the origi-nal video,as we expect to achieve better contrast result,weneed to encourage intra-video separability.
后面的操作为了提升正负样本之间的差异性。

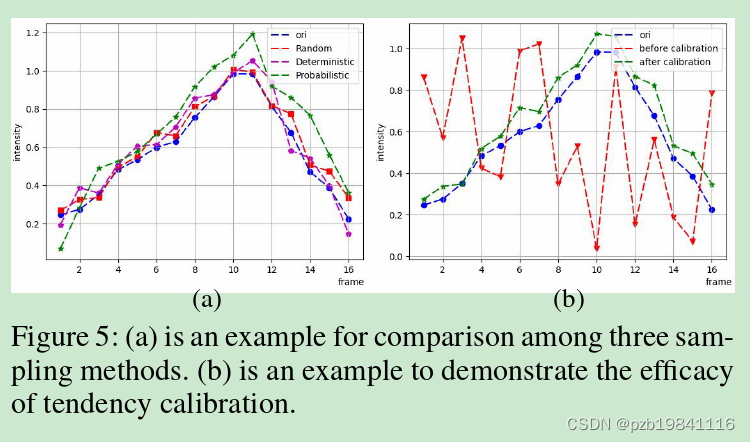
获取负样本的三种方法,第一种是全都取,第二种的相同的概率抽取,第三种先计算锚定帧与其他帧之间的差异,再将差异通过softmax转换成概率。
An intensity distillation loss,aimming to distinguish the positives from the negatives,isenforced based on the features,
基于特征的强度蒸馏损失,旨在区分正面和负面样本。强度蒸馏损失的计算方法如下:

The video clips in ME databases present with continuousvariation of expressions,where intensity is minimal at theonset frame and reaches the peak at the apex frame,thenstarts to decline until the offset frame.
微表情视频片段中的强度变化特点,起始帧最弱,到峰值帧时达到最大值,然后逐渐转弱到结束帧。(先验知识)
we need to calibrate the extracted intensity clues tobe arranged according to a certain tendency,where the ten-dency is built from the intensity variation of original videoclip.
我们需要对提取的强度线索进行校准,使其按照一定的倾向性排列,这是趋势一致性需要做的事情。
This isachieved by placing each intensity vacancy a Gaussian dis-tribution,insteading of endowing a fixed value,
这是通过将每个强度空位放置为高斯分布来实现的,而不是赋予一个固定值,这个是主要的指导思想。

devide the whole video into two segments with the apexas the boundary.The apex has the peak intensity with 1as the mean,and the onset along with offset has the mini-mum intensity withϵas the mean.
用峰值帧将视频分为两段,峰值帧的强度为1,起始终止帧为ϵ
we adopt the 3σprinciple,where the majority of sampled points fall in therange of[µ−3σ,µ+3σ]
这里限定了强度值的取值范围。
the distribution is given as below
下面阐述了各帧强度的分布。

The ICE block outputs theintensity features corresponding to frames,then the networkdeals with them into single intensity values
ICE块输出与帧相对应的强度特征,并由网络处理为单一的强度值
Based on the modeled prototype of the intensitycurve,we next calibrate the extracted intensity features tovary following the curve,achieved by a Wilcoxon rank sumtest method.
根据强度曲线的建模原型,用Wilcoxon rank sumtest对提取的强度特征进行校准,使其按照曲线变化。
后面公式较为复杂,主要是计算出一个p值。

The p-value decides whether the two samples fit hypothesis.
这个p值可以衡量S1和S2是否属于同一个分布。
Here we devise aWilcoxon rank sum test loss to penalize the samples whichfail to follow the built prototype with a margin
在这里,我们设计了一个Wilcoxon秩和检验损失来惩罚那些未能遵循已建立的原型的样本,本质上就是个损失函数

after the intensity clues are calibrated,they are conducted the element-wise product with the facialtexture features outputted from the facial feature encoder(FFE).
强度线索标定后,与面部特征编码器( FFE )输出的面部纹理特征进行逐元素乘积,作为后续的特征向量。
For these features,a LSTM is used to capturethe dependencies in the sequence and aggregates them intoa vector v,which is the final representation of a ME videoclip used for recognition.
对于这些特征,使用LSTM来捕获序列中的依赖关系,并将它们聚合成一个向量v,该向量是用于识别的ME视频片段的最终表示。
这个是整个模型的损失函数,包含强度蒸馏损失函数,概率分布损失函数和分类损失函数,用一个系数向量乘加起来。

实验
The data augmentation strategy used for augment-ing anchor samples are ColorJitter,RandomGrayscale and GaussianBlur.
数据增强用到了颜色抖动、随机灰度和高斯模糊。颜色抖动,这是一种调整图像颜色的数据增强方法。它可以随机地调整图像的亮度、对比度、饱和度和色调,以增加训练样本的多样性。通过在颜色空间引入随机性,模型更容易适应不同光照条件和颜色变化。随机灰度,这个方法是将图像转换为灰度图,并且这个转换的过程是随机的。这种方法有助于使模型对于单通道图像(灰度图)的输入更具鲁棒性,同时也增加了数据的多样性。高斯模糊,这是一种模糊图像的方法,通过应用高斯滤波器来/减小图像中每个像素的变化。这有助于降低图像中噪音的影响,使模型更专注于图像中的主要特征。高斯模糊还可以在一定程度上模拟图像中的运动模糊,从而提高模型对于运动相关特征的学习能力。
做了横向对比实验和消融实验,肯定是提出的方法最好

还做了其他实验,包括损失函数中几个子项之间的系数关系,选取负样本的策略等。

As we men-tioned before,the purpose of this prototype is to guide thenetwork to learn the overall tendency,where the values areinsignificant.
正如我们前面提到的,这个原型的目的是引导网络学习整体趋势,其中的值是不显著的。这里解释了强度校准后,跟原来趋势一样就行,不一定非要数据相同的原因。(下图右边子图)
结论
Our strategy comesfrom two perspectives:intensity enhancement and tendencyconsistency.
我们的策略来自两个角度:强度增强和趋势一致性。这个是本文的创新点。
这篇关于CMNet:Contrastive Magnification Network for Micro-Expression Recognition 阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







