本文主要是介绍【论文】self-contrastive learning: Single-viewed Supervised Contrastive Framework using Sbu-network,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Review:

SelfCon:


Framework:
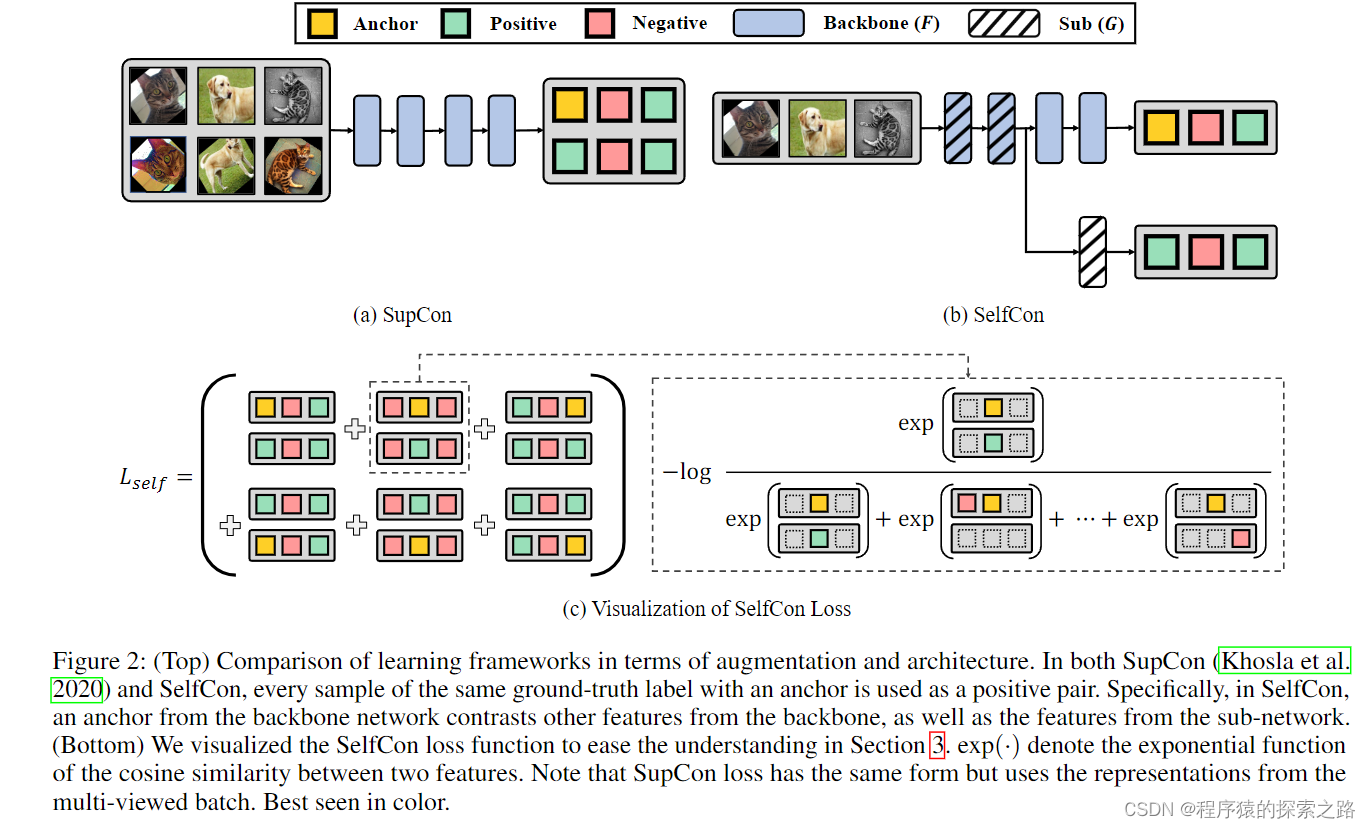
Idea:

Paper:

这篇关于【论文】self-contrastive learning: Single-viewed Supervised Contrastive Framework using Sbu-network的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
