supervised专题

论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes
论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes 优势 1、构建了一个用于监督原始视频去噪的基准数据集。为了多次捕捉瞬间,我们手动为对象s创建运动。在高ISO模式下捕获每一时刻的噪声帧,并通过对多个噪声帧进行平均得到相应的干净帧。 2、有效的原始视频去噪网络(RViDeNet),通过探

COD论文笔记 ECCV2024 Just a Hint: Point-Supervised Camouflaged Object Detection
这篇论文的主要动机、现有方法的不足、拟解决的问题、主要贡献和创新点: 1. 动机 伪装物体检测(Camouflaged Object Detection, COD)旨在检测隐藏在环境中的伪装物体,这是一个具有挑战性的任务。由于伪装物体与背景的细微差别和模糊的边界,手动标注像素级的物体非常耗时,例如每张图片可能需要 60 分钟来标注。因此,作者希望通过减少标注负担,提出了一种仅依赖“点标注”的弱

3D Deeply Supervised Network for Automatic Liver Segmentation from CT Volumes
下面博主详细翻译了该篇论文,可以当做详尽的参考,并认真学习。 【参考】论文笔记:3D Deeply Supervised Network for Automatic Liver Segmentation from CT 数据集: MICCAI-SLiver07[1] 数据预处理: 作者没有讲数据预处理的过程。 CRF 轮廓精细修正: 参考上述博主博客。 参考文献: [1]Heimann,

机器学习-算法-半监督学习:半监督学习(Semi-supervised Learning)算法
人工智能-机器学习-算法-半监督学习:半监督学习(Semi-supervised Learning)算法 一、半监督学习算法提出的背景1、监督学习算法2、无监督学习算法3、监督学习的特征选择方法4、无监督学习的特征选择方法5、问题的提出 二、学术名词区分1、主动学习(active learning)2、归纳式学习(inductive learning)3、直推式学习(transductive
![[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners](https://i-blog.csdnimg.cn/direct/4cc9701420354cecb5eba7197a705453.png)
[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners
1、目的 借助无监督预训练来提升半监督学习的效果 2、方法 1)unsupervised/self-supervised pretrain -> task-agnostic -> big (deep and wide) neural network可以有效提升准确性

【Deep Learning】Self-Supervised Learning:自监督学习
自监督学习 本文基于清华大学《深度学习》第12节《Beyond Supervised Learning》的内容撰写,既是课堂笔记,亦是作者的一些理解。 在深度学习领域,传统的监督学习(Supervised Learning)的形式是给你输入 x x x和标签 y y y,你需要训练一个基于参数 θ \theta θ的神经网络 f θ ( x ) f_\theta(x) fθ(x)使其能

CVPR2023论文速览自监督Self-Supervised相关38篇
Paper1 Self-Supervised Video Forensics by Audio-Visual Anomaly Detection 摘要原文: Manipulated videos often contain subtle inconsistencies between their visual and audio signals. We propose a video foren

G7 - Semi-Supervised GAN 理论与实战
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目录 理论知识模型实现引用、配置参数初始化权重定义算法模型模型配置模型训练训练模型 模型效果总结与心得体会 理论知识 在条件GAN中,判别器只用来判断图像的真和假,到了条件GAN中,图像本身其实是有标签的,这时候我们可能会想,为什么不直接让判别器输出图像的标签呢?本节要探究的SGAN就

【论文总结】weakly- and semi-supervised learning of a DCNN for semantic Image Segmentation
一、概述 这篇文章研究了如何从弱注释的训练数据(如边界框或图像级标签)或少量强标记图像和许多弱标记图像的组合中学习DCNN用于语义图像分割的问题,在弱超监督和半监督条件下提出了期望最大化(EM)方法。 代码:https://bitbucket.org/deeplab/deeplab-public(caffe框架) 二、研究内容及方法 文章将焦点放在用弱标签训练调参上

Self Supervised Learning部分相关论文简介(上)
Self Supervised Learning部分相关论文简介(上) 摘要:自监督论文阅读#1 "Context Encoders: Feature Learning by Inpainting" [CVPR 2016]#2 Multi-task Self-Supervised Visual Learning [2017]#3 Unsupervised Visual Representat

内涵:半监督学习之Temporal Ensembling For Semi-supervised Learning
一、 引言 这篇文章是ICLR2017的一篇文章,是半监督学习领域的一篇经典文章,以这篇文章作为进入半监督学习的一个切入点。 在这篇文章中,作者的将其工作描述为self-ensembling,而具体来讲有两点:1. Π model 2. temporal ensembling。 We describe two ways to implement self-ensembling, Π-

Datacamp 笔记代码 Supervised Learning with scikit-learn 第四章 Preprocessing and pipelines
更多原始数据文档和JupyterNotebook Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python Datacamp track: Data Scientist with Python - Course 21 (4) Exercise Exploring categorical features The G

SiT : Self-supervised vision Transformer
从NLP Transformer中借鉴而来的视觉 Transformer 在使用大规模监督数据或某种形式的协同监督(例如教师网络)进行预训练时已被证明是有效的。这些经过监督预训练的视觉Transformer在下游任务中通过最小的改动就能取得出色的结果。 随着监督预训练(SP)和自监督预训练(SSP)在下游应用(如分类、定位、分割等)之间的性能差距逐渐缩小,自监督学习(SSL)在计算机视觉领域正逐
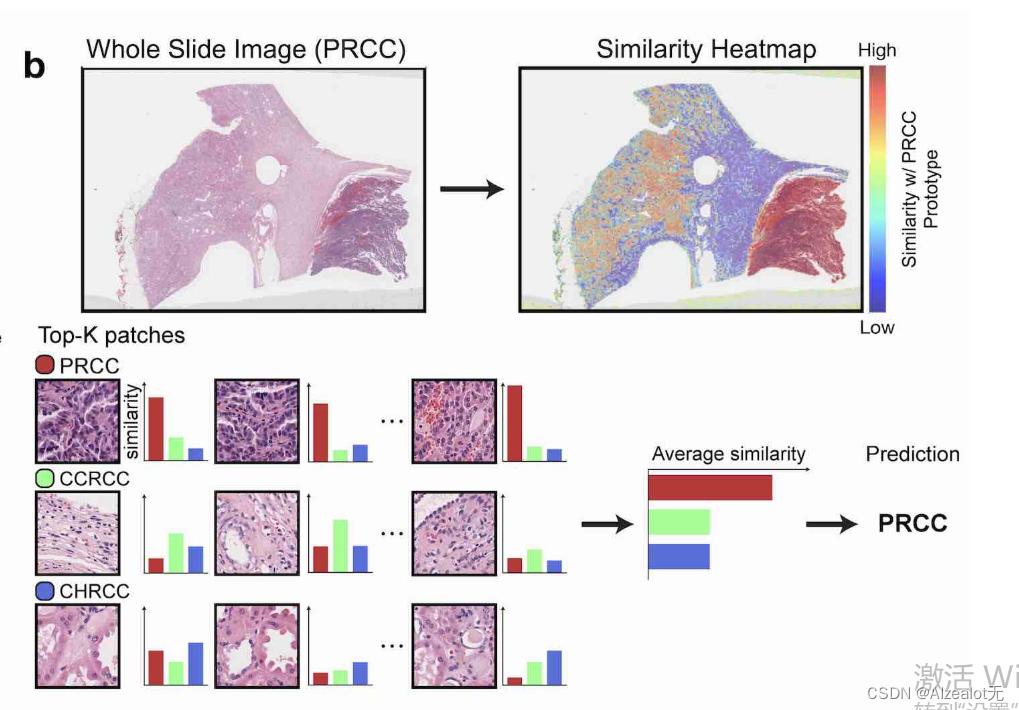
论文解读之A General-Purpose Self-Supervised Model for Computational Pathology
一、前言 目前,有很多无知者认为计算机在疾病诊断上超过了人类,他们的理解是计算机在美丽国的某个什么医师测评上得分超过了人类。这比较可笑和无知。 笔者认为:病理图像的病症复杂、种类繁多,同时数据集很少并且标注极为困难。故而,能用于训练的高质量数据很少,并且模型的可解释性还不足。 因此,AI在疾病诊断上的表现想要接近和超过人类专家还很遥远。故而目前火热的名词只是辅助诊断,并不是AI诊断。 本次

Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(十) 使用 LoRA 微调常见问题答疑
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(一) LLaMA-Factory简介
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3

TNNLS:Fast Self-Supervised Clustering With Anchor Graph论文阅读
1 Abstract 由于避免了使用通常在现实世界中不足的标记样本,无监督学习被视为在聚类任务中的快速和强大策略。然而,直接从原始数据集进行聚类会导致高计算成本,这限制了其在大规模和高维问题上的应用。最近,基于锚点的理论被提出来部分缓解这个问题,并自然地稀疏化了亲和力矩阵,但仍然存在挑战,即在保持高效性的同时获得出色的性能。为了解决这个问题,我们首先提出了一个快速的半监督框架(FSSF),结合了
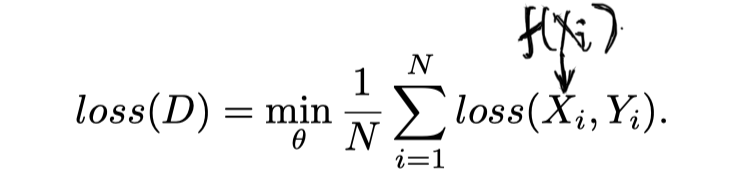
19-Self-supervised-Visual-Feature-Learning-with-Deep-Neural-Networks-A-Survey
who Longlong Jing and Yingli Tian ∗ , Fellow, IEEE2019- what 为了避免收集和注释大规模数据集的大量成本,作为无监督学习方法的子集,提出了自我监督学习方法,以从大规模未标记数据中学习一般图像和视频特征,而无需使用任何人工标注的标签。 一些术语 1. Pseudo label: 伪标签是基于pretext tasks的数据属性

Revisiting-Dilated-Convolution-A-Simple-Approach-for-Weakly-and-Semi-Supervised
when 魏云超组的18年cvpr spot who 弱监督语义分割问题的新方法,用扩张卷积得到注意力图,可能能够在GAIN的大框架上面修改 why 提出 尽管弱监督分割方法取得了显着的进步,但仍然不如全监督的方法。我们认为性能差距主要来自他们学习从图像级监督产生高质量密集对象定位图的限制。为了弥补这种差距,我们重新审视了空洞卷积[1]并揭示了如何以一种新颖的方式利用它来有效地克服弱

18-Weakly-Supervised-Semantic-Segmentation-Network-with-Deep-Seeded-Region-Growing
when cvpr18 what 本文研究了仅使用图像级标签作为监督来学习图像语义分割网络的问题,这一点很重要,因为它可以显着减少人类的标注工作。最近关于该问题的最新方法首先使用深度分类网络推断每个对象类的稀疏和鉴别区域,然后使用鉴别区域作为监督来训练语义分割网络。在种子区域扩展的传统图像分割方法的启发下,我们提出从鉴别区域开始训练语义分割网络,逐步增加种子区域扩展的像素级监督。种子区域扩
18-Weakly-Supervised-Semantic-Segmentation-by Iteratively-Mining-Common-Object-Features
when CVPR 2018 who(影响了谁) 图像标签监督下的弱监督语义分割是一项具有挑战性的任务,因为它直接将高级语义与低级别外观相关联。为了弥合这一差距,在本文中,我们提出了一个迭代的自下而上和自上而下的框架,它可以扩展对象区域并优化分割网络。 why(为什么提出) 弱监督的语义分割非常具有挑战性,因为它直接将高级语义与低级别外观相关联。 由于只有图像标签可用,因此大多数先前

17-WILDCAT-Weakly-Supervised-Learning-of-DeepConvNets
who(对谁有效) 弱监督图像语义分割 where 只有图像级标签的数据 when CVPR 2017 what(WILDCAT是什么) 这篇论文提出了一个框架,可以使用弱监督的方法识别一个物体显著的局部特征。首先我们来直观感受下结果,如下图所示,WILDCAT可以识别狗的头部和腿部信息,从而利用这些信息来对狗进行Localization和segmentation. 结
深度学习中的黑科技:自监督学习(Self-Supervised Learning)
在人工智能领域,深度学习已成为推动技术革新的核心力量。然而,深度学习的一个重要瓶颈是对大量标记数据的依赖性。在这个背景下,自监督学习(Self-Supervised Learning, SSL)作为一种新兴的学习范式,越来越受到研究者的关注。自监督学习能够利用未标记的数据学习到有用的特征表示,这一潜力巨大的领域正在开启机器学习的新篇章。 一、什么是自监督学习? 自监督学习是一种机器学习框架,旨

论文阅读 Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
Adaptive Consistency Regularization for Semi-Supervised Transfer Learning 论文题目:自适应一致性正则化方法用于半监督迁移学习 作者单位:百度大数据研究院 作者:Abulikemu Abuduweili 代码地址:https://github.com/SHI-Labs/Semi-Supervised-Transfer-Lea
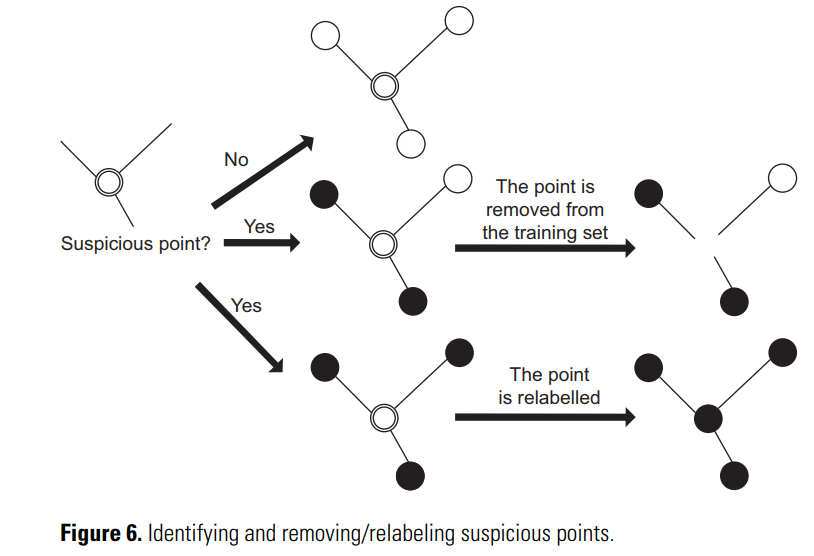
论文阅读笔记:A brief introduction to weakly supervised learning
论文:A brief introduction to weakly supervised learning / 对弱监督学习的简要介绍 作者:Zhi-Hua Zhou / 周志华 发表刊物:National Science Review 发表年度:2018 下载地址:https://academic.oup.com/nsr/article/5/1/44/4093912 Abstract / 摘要
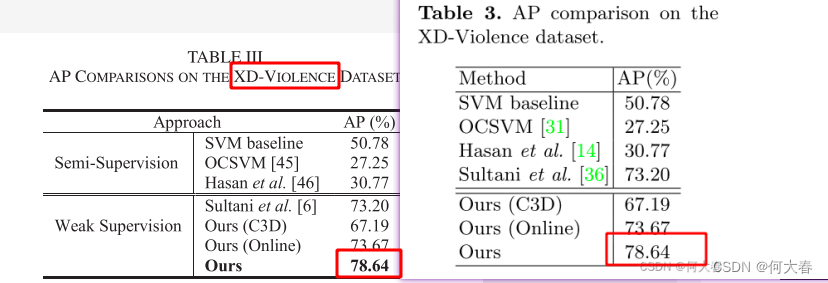
Weakly Supervised Audio-Visual Violence Detection 论文阅读
Weakly Supervised Audio-Visual Violence Detection 论文阅读 摘要III. METHODOLOGYA. Multimodal FusionB. Relation Modeling ModuleC. Training and Inference IV. EXPERIMENTSV. CONCLUSION阅读总结 文章信息: 发表于: