本文主要是介绍G7 - Semi-Supervised GAN 理论与实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目录
- 理论知识
- 模型实现
- 引用、配置参数
- 初始化权重
- 定义算法模型
- 模型配置
- 模型训练
- 训练模型
- 模型效果
- 总结与心得体会
理论知识
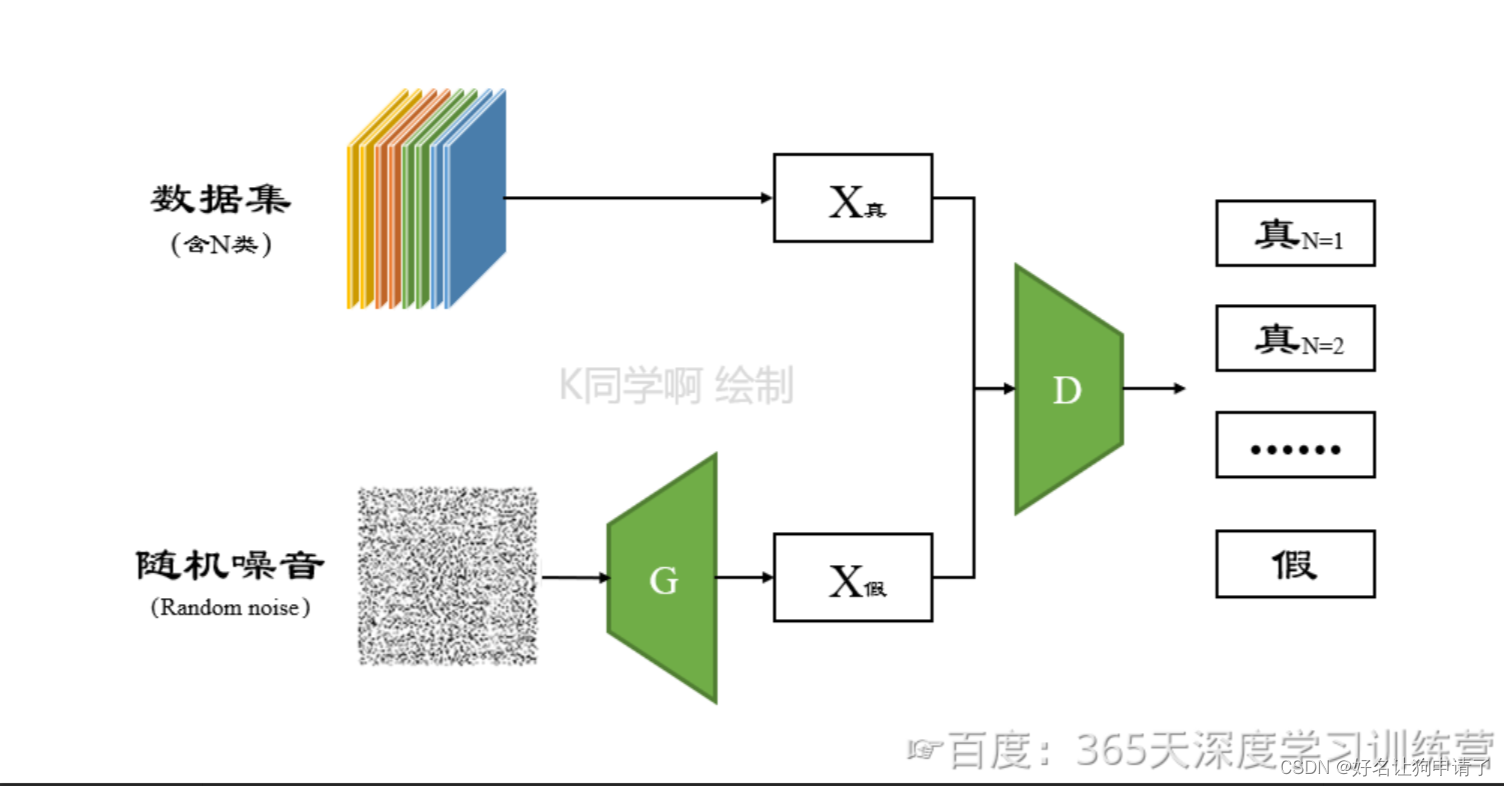
在条件GAN中,判别器只用来判断图像的真和假,到了条件GAN中,图像本身其实是有标签的,这时候我们可能会想,为什么不直接让判别器输出图像的标签呢?本节要探究的SGAN就实现了这样一个GAN网络。
SGAN将GAN拓展到半监督学习,通过强制判别器D来输出类别标签来实现。
SGAN在一个数据集上训练一个生成器G和一个判别器D,输入是N类中的一个,在训练的时候,判别器D也被用于预测输入是属于N+1类中的哪一个,这个N+1是对应了生成器G的输出,这里的判别器D同时也充当起了分类器C的效果。
经过实验发现,这种方法可以用于训练效果更好的判别器D,并且可以比普通的GAN产生更加高质量的样本。
Semi-Supervised GAN有如下成果:
- 作者对GANs做了一个新的扩展,允许它同时学习一个生成模型和一个分类器,我们把这个拓展称为半监督GAN或者SGAN
- 实验结果表明,SGAN在有限数据集上比没有生成部分的基准分类器提升了分类性能
- 实验结果表明,SGAN可以显著地提升生成样本的质量并降低生成器的训练时间

对比生成效果发现,SGAN比普通的DCGAN算法的结果更好。
模型实现
引用、配置参数
import argparse
import os
import numpy as np
import mathfrom torchvision import datasets, transforms
from torchvision.utils import save_imagefrom torch.utils.data import DataLoader
from torch.autograd import Variableimport torch.nn as nn
import torch.nn.functional as F
import torch# 创建结果输出目录,没有就新增,有就跳过
os.makedirs('images', exist_ok=True)# 参数
n_epochs = 50 # 训练轮数
batch_size = 64 # 每个批次的样本数量
lr = 0.0002 # 学习率
b1 = 0.5 # Adam优化器的第一个动量衰减参数
b2 = 0.999 # Adam 优化器的第二个动量衰减参数
n_cpu = 8 # 用于批次生成的CPU线程数
latent_dim = 100 # 潜在空间的维度
num_classes = 10 # 数据集的类别数
img_size = 32 # 每个图像的尺寸(高度和宽度相等)
channels = 1 # 图像的通道数(灰度图像通道数为1)
sample_interval = 400 # 图像采样间隔# 全局设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
初始化权重
def weights_init_normal(m):classname = m.__class__.__name__if classname.find('Conv')!= -1:torch.nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find('BatchNorm') != -1:torch.nn.init.normal_(m.weight.data, 1.0, 0.02)torch.nn.init.normal_(m.bias.data, 0.0)
定义算法模型
# 生成器
class Generator(nn.Module):def __init__(self):super().__init__()# 创建一个标签嵌入层,用于将条件标签映射到潜在空间self.label_emb = nn.Embedding(num_classes, latent_dim)# 初始化图像尺寸, 用于上采样之前self.init_size = img_size //4# 第一个全连接层,将随机噪声映射到合适的维度self.l1 = nn.Sequential(nn.Linear(latent_dim, 128*self.init_size**2))# 生成器的卷积块self.conv_blocks = nn.Sequential(nn.BatchNorm2d(128),nn.Upsample(scale_factor=2),nn.Conv2d(128, 128, 3, stride=1, padding=1),nn.BatchNorm2d(128, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(128, 64, 3, stride=1, padding=1),nn.BatchNorm2d(64, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, channels, 3, stride=1, padding=1),nn.Tanh(),)def forward(self, noise):out = self.l1(noise)out = out.view(out.shape[0], 128, self.init_size, self.init_size)img = self.conv_blocks(out)return img
# 判别器,一个分类网络
class Discriminator(nn.Module):def __init__(self):super().__init__()def discriminator_block(in_filters, out_filters, bn=True):"""返回每个鉴别器块的层"""block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]if bn:block.append(nn.BatchNorm2d(out_filters, 0.8))return block# 鉴别器的卷积块self.conv_blocks = nn.Sequential(*discriminator_block(channels, 16, bn=False),*discriminator_block(16, 32),*discriminator_block(32, 64),*discriminator_block(64, 128),)# 下采样图像的高度和宽度ds_size = img_size // 2 ** 4# 输出层self.adv_layer = nn.Sequential(nn.Linear(128*ds_size**2, 1),nn.Sigmoid())self.aux_layer = nn.Sequential(nn.Linear(128*ds_size**2, num_classes + 1), nn.Softmax())def forward(self, img):out = self.conv_blocks(img)out = out.view(out.shape[0], -1)validity = self.adv_layer(out)label = self.aux_layer(out)return validity, label
模型配置
# 定义损失函数# 二元交叉熵损失,用于对抗训练
adversarial_loss = nn.BCELoss().to(device)
# 交叉熵损失,用于辅助分类
auxiliary_loss = nn.CrossEntropyLoss().to(device)# 初始化生成器和鉴别器
generator = Generator().to(device)
discriminator = Discriminator().to(device)# 初始化模型权重
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)# 配置数据加载器
os.makedirs('data/mnist', exist_ok=True)dataloader = DataLoader(datasets.MNIST('data/mnist',train=True,download=True,transform=transforms.Compose([transforms.Resize(img_size),transforms.ToTensor(),transforms.Normalize([0.5], [0.5])]),),batch_size=batch_size,shuffle=True)# 创建优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))
模型训练
for epoch in range(opt._epochs):for i, (imgs, labels) in enumerate(dataloader):batch_size = imgs.shape[0]# 生成对抗训练的标签valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=Falsefake = Variable(FloatTensor(batch_size, 2).fill_(0,0)fake_aux_gt = Variable(LongTensor(batch_size).fill_(opt.num_classes, requires_grad)
训练模型
for epoch in range(n_epochs):for i, (imgs, labels) in enumerate(dataloader):batch_size = imgs.shape[0]# 定义对抗训练的标签valid = torch.ones((batch_size, 1), requires_grad=False, device=device)fake = torch.zeros((batch_size, 1), requires_grad=False, device=device)fake_aux_gt= torch.ones((batch_size), dtype=torch.int64, device=device, requires_grad=False)*num_classes# 配置输入数据real_imgs = imgs.to(device)labels = labels.to(device)# ** 训练生成器 **optimizer_G.zero_grad()# 采样噪声和类别标签作为生成器的输入z = torch.rand([batch_size, latent_dim], device=device)# 生成一批图像gen_imgs = generator(z)# 计算生成器的损失衡量生成器欺骗鉴别器的能力validity, _ = discriminator(gen_imgs)g_loss = adversarial_loss(validity, valid)g_loss.backward()optimizer_G.step()# ** 训练鉴别器 **optimizer_D.zero_grad()# 真实图像的损失real_pred, real_aux = discriminator(real_imgs)d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2# 生成图像的损失fake_pred, fake_aux = discriminator(gen_imgs.detach())d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, fake_aux_gt)) /2# 总的鉴别器损失d_loss = (d_real_loss + d_fake_loss) / 2# 计算鉴别器准确率pred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)gt = np.concatenate([labels.data.cpu().numpy(), fake_aux_gt.data.cpu().numpy()], axis=0)d_acc = np.mean(np.argmax(pred, axis=1) == gt)d_loss.backward()optimizer_D.step()batches_done = epoch*len(dataloader) + iif batches_done % sample_interval == 0:save_image(gen_imgs.data[:25], 'images/%d.png' % batches_done, nrow=5, normalize=True)print('[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]' % (epoch, n_epochs, i, len(dataloader), d_loss.item(), 100*d_acc, g_loss.item()))
训练过程
[Epoch 0/50] [Batch 937/938] [D loss: 1.361139, acc: 50%] [G loss: 0.692496]
[Epoch 1/50] [Batch 937/938] [D loss: 1.339481, acc: 50%] [G loss: 0.743710]
[Epoch 2/50] [Batch 937/938] [D loss: 1.324114, acc: 50%] [G loss: 0.876165]
[Epoch 3/50] [Batch 937/938] [D loss: 1.163164, acc: 50%] [G loss: 1.803553]
[Epoch 4/50] [Batch 937/938] [D loss: 1.115438, acc: 50%] [G loss: 3.103937]
[Epoch 5/50] [Batch 937/938] [D loss: 1.045782, acc: 50%] [G loss: 4.149418]
[Epoch 6/50] [Batch 937/938] [D loss: 0.996207, acc: 56%] [G loss: 5.366407]
[Epoch 7/50] [Batch 937/938] [D loss: 0.944309, acc: 67%] [G loss: 5.629416]
[Epoch 8/50] [Batch 937/938] [D loss: 0.923516, acc: 71%] [G loss: 5.145832]
[Epoch 9/50] [Batch 937/938] [D loss: 0.941332, acc: 78%] [G loss: 3.469946]
[Epoch 10/50] [Batch 937/938] [D loss: 0.945412, acc: 75%] [G loss: 3.282685]
[Epoch 11/50] [Batch 937/938] [D loss: 0.862699, acc: 84%] [G loss: 3.509322]
[Epoch 12/50] [Batch 937/938] [D loss: 0.880701, acc: 87%] [G loss: 2.907838]
[Epoch 13/50] [Batch 937/938] [D loss: 0.853650, acc: 92%] [G loss: 4.008491]
[Epoch 14/50] [Batch 937/938] [D loss: 0.814380, acc: 93%] [G loss: 4.354833]
[Epoch 15/50] [Batch 937/938] [D loss: 0.907486, acc: 89%] [G loss: 4.128651]
[Epoch 16/50] [Batch 937/938] [D loss: 0.839670, acc: 87%] [G loss: 3.847980]
[Epoch 17/50] [Batch 937/938] [D loss: 1.118082, acc: 75%] [G loss: 3.573672]
[Epoch 18/50] [Batch 937/938] [D loss: 0.877845, acc: 87%] [G loss: 3.234770]
[Epoch 19/50] [Batch 937/938] [D loss: 1.176042, acc: 75%] [G loss: 4.499653]
[Epoch 20/50] [Batch 937/938] [D loss: 0.942495, acc: 84%] [G loss: 4.823555]
[Epoch 21/50] [Batch 937/938] [D loss: 0.874024, acc: 93%] [G loss: 3.880158]
[Epoch 22/50] [Batch 937/938] [D loss: 0.887224, acc: 90%] [G loss: 3.924105]
[Epoch 23/50] [Batch 937/938] [D loss: 0.876955, acc: 89%] [G loss: 4.332885]
[Epoch 24/50] [Batch 937/938] [D loss: 1.164700, acc: 79%] [G loss: 5.855463]
[Epoch 25/50] [Batch 937/938] [D loss: 0.824182, acc: 100%] [G loss: 3.745309]
[Epoch 26/50] [Batch 937/938] [D loss: 0.991236, acc: 87%] [G loss: 4.963309]
[Epoch 27/50] [Batch 937/938] [D loss: 0.906700, acc: 92%] [G loss: 5.675440]
[Epoch 28/50] [Batch 937/938] [D loss: 0.864558, acc: 93%] [G loss: 5.964598]
[Epoch 29/50] [Batch 937/938] [D loss: 0.788707, acc: 96%] [G loss: 7.074716]
[Epoch 30/50] [Batch 937/938] [D loss: 1.044333, acc: 84%] [G loss: 4.304685]
[Epoch 31/50] [Batch 937/938] [D loss: 0.797054, acc: 100%] [G loss: 5.197765]
[Epoch 32/50] [Batch 937/938] [D loss: 0.824380, acc: 100%] [G loss: 5.913801]
[Epoch 33/50] [Batch 937/938] [D loss: 0.978360, acc: 87%] [G loss: 3.314190]
[Epoch 34/50] [Batch 937/938] [D loss: 1.014248, acc: 78%] [G loss: 8.149563]
[Epoch 35/50] [Batch 937/938] [D loss: 1.352330, acc: 68%] [G loss: 8.068608]
[Epoch 36/50] [Batch 937/938] [D loss: 0.906131, acc: 89%] [G loss: 7.385222]
[Epoch 37/50] [Batch 937/938] [D loss: 0.813954, acc: 98%] [G loss: 5.816649]
[Epoch 38/50] [Batch 937/938] [D loss: 0.840815, acc: 98%] [G loss: 6.768866]
[Epoch 39/50] [Batch 937/938] [D loss: 0.864865, acc: 90%] [G loss: 2.277655]
[Epoch 40/50] [Batch 937/938] [D loss: 0.810660, acc: 93%] [G loss: 6.076533]
[Epoch 41/50] [Batch 937/938] [D loss: 1.189352, acc: 78%] [G loss: 4.746247]
[Epoch 42/50] [Batch 937/938] [D loss: 0.823831, acc: 90%] [G loss: 9.117917]
[Epoch 43/50] [Batch 937/938] [D loss: 0.975088, acc: 85%] [G loss: 2.690667]
[Epoch 44/50] [Batch 937/938] [D loss: 0.911645, acc: 89%] [G loss: 6.431296]
[Epoch 45/50] [Batch 937/938] [D loss: 1.214794, acc: 65%] [G loss: 5.860756]
[Epoch 46/50] [Batch 937/938] [D loss: 0.849733, acc: 98%] [G loss: 4.305855]
[Epoch 47/50] [Batch 937/938] [D loss: 0.910819, acc: 90%] [G loss: 6.148373]
[Epoch 48/50] [Batch 937/938] [D loss: 0.828892, acc: 96%] [G loss: 9.507065]
[Epoch 49/50] [Batch 937/938] [D loss: 1.086049, acc: 84%] [G loss: 5.026798]
模型效果
第一次输出的图像

25轮输出的图像

最后输出的图像

通过图像可以发现,不同类型的数字间有很大区别,SGAN可以生成的很好
总结与心得体会
SGAN对于GAN的改进,更像是一个拥有着部分共同权重的一组小模型,可以让每个分类的图像生成的更加精确,避免生成的图像同时拥有着几种手势的特点,有点不伦不类。
目前的判别器中,无法对生成的图像打上准确的标签,这样应该会影响生成的精度,如果可以结合CGAN,直接让生成器也学习不同分类的特点,然后让判别器精确的区分,应该可以得到一个更精确的条件生成网络。
这篇关于G7 - Semi-Supervised GAN 理论与实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








