本文主要是介绍19-Self-supervised-Visual-Feature-Learning-with-Deep-Neural-Networks-A-Survey,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
who
- Longlong Jing and Yingli Tian ∗ , Fellow, IEEE
- 2019-
what
- 为了避免收集和注释大规模数据集的大量成本,作为无监督学习方法的子集,提出了自我监督学习方法,以从大规模未标记数据中学习一般图像和视频特征,而无需使用任何人工标注的标签。
一些术语
1. Pseudo label:
- 伪标签是基于pretext tasks的数据属性自动生成的标签。
2. Pretext Task
- Pretext tasks 是网络要解决的预先设计的任务,通过学习Pretext tasks 的目标函数来学习视觉特征。
3. Downstream Task
- 用于评估自我监督学习所学习的特征的质量。
- 需要人工标注的标签来解决Downstream Task。
- 在某些应用程序中,Downstream Task可以与Pretext tasks 一样不使用任何人工注释标签。
4. Self-supervised Learning
- 无监督学习方法的一个子集。
- 学习方法,其中使用自动生成的标签明确训练ConvNets;
本综述仅关注视觉特征的自我监督学习方法
where
动机
1. 经过预先训练的模型,并针对其他任务进行了调整,主要有两个原因
- 从大规模不同数据集中学习的参数提供了一个很好的起点,因此,对其他任务的网络训练可以更快地收敛;
- 在大规模数据集上训练的网络已经学习了层次结构特征,这有助于减少其他任务训练期间的过拟合问题,特别是当其他任务的数据集很小或者训练标签很少时。
2. 要从未标记的数据中学习视觉特征
- 为了避免耗时且昂贵的数据标注;
- 一种流行的解决方案是提出网络要解决的各种pretext tasks,同时通过学习pretext tasks的目标函数来训练网络,并通过该过程学习特征。
3. pretext tasks共享两个共同属性
- ConvNets需要捕获图像或视频的视觉特征来解决pretext tasks,
- 可以基于图像或视频的属性自动生成用于pretext tasks的伪标签。
整体思路框架

创新
- 据我们所知,这是第一个关于深度ConvNets的自我监督视觉特征学习的全面调查,这将有助于该领域的研究人员。
- 深入审查最近开发的自我监督学习方法和数据集。
- 提供了定量性能分析和现有方法的比较。
不同学习方法的函数
1. 监督学习函数
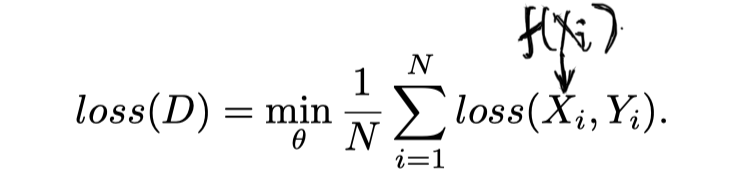
2. 半监督学习函数
这篇关于19-Self-supervised-Visual-Feature-Learning-with-Deep-Neural-Networks-A-Survey的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








