feature专题

【机器学习 sklearn】特征筛选feature_selection
特征筛选更加侧重于寻找那些对模型的性能提升较大的少量特征。 继续沿用Titannic数据集,这次试图通过特征刷选来寻找最佳的特征组合,并且达到提高预测准确性的目标。 #coding:utf-8from __future__ import divisionimport sysreload(sys)sys.setdefaultencoding('utf-8')import timest

feature_column相关接口
在TensorFlow中,特征列(Feature column)是原始数据和 Estimator 之间的接口,它告诉Estimator如何使用数据。 原始数据集包含各种各样的特征,有的特征是数值,比如年龄,长度、速度;有的特征是文字,比如,地址、Email内容、数据库查询语句等 神经网络接受的输入,只能是数值,而且是整理好的数值 所以,原始数据 和 神经网络输入需求之间需要一个桥梁,这个

Detection简记2-DAFE-FD: Density Aware Feature Enrichment for Face Detection
创新点 1.使用密度估计模型增强检测中的特征图 总结 整个流程还是很清晰的。 conv1-3的特征图经过密度估计模块由检测器D1进行检测。 D2-4分别是四个检测器。 FFM是特征融合模块,将不同层不同大小的特征融合。 FFM网络结构如下: 首先使用1X1的卷积减少两组特征的厚度到128,然后使用双线性插值统一两组特征图的尺寸,然后相加。类似于cvpr2017的SSH。 多尺度检测器的网

rust feature 简介
Rust 的 feature 是一种机制,用于在编译时选择性地启用或禁用代码的某些部分。通过 feature,你可以在 Cargo.toml 中定义哪些功能需要启用,并在代码中通过条件编译来控制代码的编译与否。下面是 feature 机制的详解: 1. 基本概念 Feature: 是一个编译时的标志,允许你有选择性地启用某些代码路径、依赖项或编译选项。Default Feature: 默认启用

特征选择错误:The classifier does not expose coef_ or feature_importances_ attributes
在利用RFE进行特征筛选的时候出现问题,源代码如下: from sklearn.svm import SVRmodel_SVR = SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='auto',kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verb
Learning Policies for Adaptive Tracking with Deep Feature Cascades
Learning Policies for Adaptive Tracking with Deep Feature Cascades ICCV17 shotlight 作者:Chen Huang, CMU postdoctor,导师 Deva Ramanan summary 文章主要贡献在于速度与精度的权衡(AUC 0.638,fps 23),通过强化学习策略,来控制网络的深度,使得精度和
Structure-Aware Feature Fusion for Unsupervised Domain Adaptation
Structure-Aware Feature Fusion for Unsupervised Domain Adaptation 摘要引言相关工作UDA中的分布匹配方法 Model 摘要 无监督域适应(Unsupervised Domain Adaptation,UDA)旨在从有标注的源域中学习并迁移通用特征到无任何标注的目标域。现有的方法仅对高层次的表示进行对齐,却没有利
【译】PCL官网教程翻译(21):旋转投影统计(RoPs)特征 - RoPs (Rotational Projection Statistics) feature
英文原网址查看 旋转投影统计(RoPs)特征 在本教程中,我们将学习如何使用pcl::ROPSEstimation类来提取点特性。在这门课中实现的特征提取方法是由Yulan Guo, Ferdous Sohel, Mohammed Bennamoun, Min Lu and Jianwei Wanalso在他们的文章《旋转投影统计用于三维局部表面描述和目标识别》中提出的。 理论基础 特征提

【译】PCL官网教程翻译(17):快速点特征直方图(FPFH)描述符 -Fast Point Feature Histograms (FPFH) descriptors
英文原文阅读 快速点特征直方图(FPFH)描述符 计算复杂度直方图(见点特征直方图(PFH)描述符)对于一个给定的有 n n n个点的点云 P P P为 O ( n k 2 ) O (nk ^ 2) O(nk2), k k k是每个点P的最邻近点个数。对于要求实时或接近实时的应用程序,密集点的特征直方图的计算效率是一个一个主要问题。 本教程描述了PFH公式的简化,称为快速点特征直方图(FPF

【译】PCL官网教程翻译(16):点特征直方图(PFH)描述符 -Point Feature Histograms (PFH) descriptors
英文原网页查看。 点特征直方图(PFH)描述符 就点特征表示而言,表面法线和曲率估计是在表示特定点周围的基本的几何形状方面。虽然计算速度极快,也很容易,但是它们不能捕捉太多的细节,因为它们只能用很少的值来近似一个点的k邻域的几何形状。直接的结果是,大多数场景将包含许多具有相同或非常相似的特征值的点,从而减少了它们的信息特征。 本教程介绍了一组为简单起见而创建的3D特征描述符PFH(点特征直方图

深度学习 --- VGG16能让某个指定的feature map激活值最大化图片的可视化(JupyterNotebook实战)
VGG16能让某个指定的feature map激活值最大化图片的可视化 在前面的文章中,我用jupyter notebook分别实现了,预训练好的VGG16模型各层filter权重的可视化和给VGG16输入了一张图像,可视化VGG16各层的feature map。深度学习 --- VGG16卷积核的可视化(JupyterNotebook实战)-CSDN博客文章浏览阅
软件工程中的feature和function
参考http://www.englishvincent.com/?p=171一文,对特性与功能差异做一个总结: Feature,特性,在词典中的解释是:A feature of something is an interestingor important part or characteristic of it。feature本意是指特点,指事务有鲜明特征方面的属性,对应到产品或解决方案所具有
darknet获取网络某一层的feature代码
当我们在命令行中执行./darknet detect fridge.cfg fridge.weights dog.jpg时,代码流程是:detect到了detector.c文件里面的test_detector函数里面的test_detector,然后在test_detector函数里面首先用parse_network_cfg_custom读取 cfg配置文件,并且用load_weights

GEE错误:Property ‘species_ID‘ of feature ‘0_0‘ is missing.
目录 错误 数据属性 现有的属性信息 原始代码 错误解析 已经写过的博客 错误 Image (Error) Property 'species_ID' of feature '0_0' is missing. 数据属性 现有的属性信息 原始代码 var sp = ee.FeatureCollection("projects/ee-aptiawo

深度学习 --- VGG16各层feature map可视化(JupyterNotebook实战)
VGG16模块的可视化 VGG16简介: VGG是继AlexNet之后的后起之秀,相对于AlexNet他有如下特点: 1,更深的层数!相对于仅有8层的AlexNet而言,VGG把层数增加到了16和19层。 2,更小的卷积核!不仅如此,相对于AlexNet中的大卷积核(如下图中的 11x11和5x5卷积核),VGG中只使

C++20中的Feature Test Mocros
C++20定义了一组预处理器宏,用于测试各种语言和库的feature。 Feature Test Mocros(特性测试宏)是C++20中引入的一种强大机制,用于应对兼容性问题。Feature Test Mocros作为预处理器指令(preprocessor directives)出现,它使你能够在编译过程中仔细检查特定语言或库功能(particular language
计算机图形的简单概念了解(目的是了解GPU相关feature含义)
Table of Contents 1. 引言2. 导论 2.1. 图形概念2.2. 图形的表示方法2.3. 图形的操作2.4. 什么是光栅?2.5. 锯齿2.6. 帧和位平面2.7. 最低刷新率是30帧/s。否则会有卡顿。2.8. 扫描转换?2.9. 视频和图形?2.10. 图形处理流程简介 3. 光栅扫描图形学 3.1. 画直线3.2. 画圆3.3. 椭圆3.4. N次多项式的一般函数,
基于图像特征的视觉跟踪系统(Feature-based visual tracking systems)--一篇Visual Tracking Benchmark (2013)综述
reference:http://blog.csdn.net/anshan1984/article/details/8866455 最近读到一篇关于视觉跟踪的综述性文章,“Evaluation of Interest Point Detectors and Feature Descriptors for Visual Tracking”,发表在2011年3月International Jour

风格迁移学习笔记(2):Universal Style Transfer via Feature Transforms
以下将分为3个部分介绍: 1.提出的background和sense2.proposal network pipeline3.results Background 先来review一下过去的架构. 1.传统的neural style存在两个巨大的弊端: 调参/耗时。即不仅需要我们对neural style的层级进行大量调参,而且整个迭代过程是对于z噪声进行迭代,非常耗时。
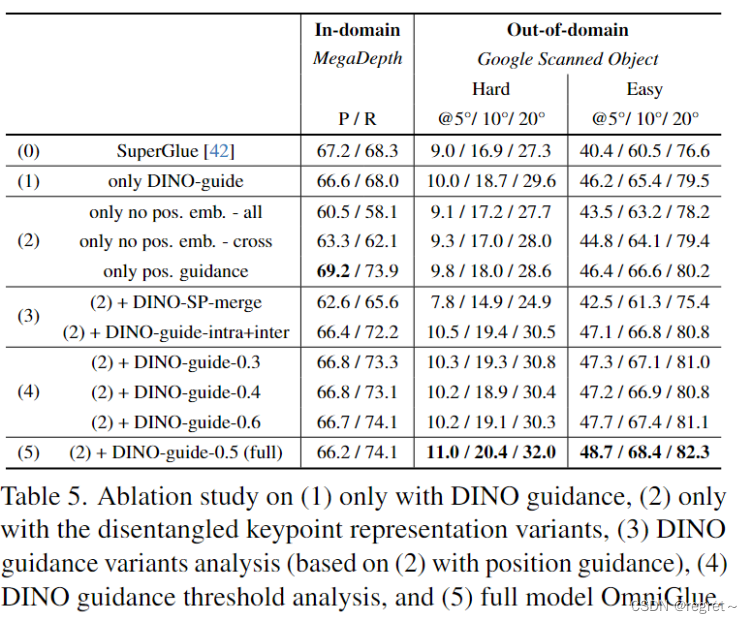
OmniGlue: Generalizable Feature Matching with Foundation Model Guidance
【引用格式】:Jiang H, Karpur A, Cao B, et al. OmniGlue: Generalizable Feature Matching with Foundation Model Guidance[J]. arXiv preprint arXiv:2405.12979, 2024. 【网址】:https://arxiv.org/pdf/2405.12979 【开源代码
uva 658 - It's not a Bug, it's a Feature!(优先队列Dijkstra)
题目链接:uva 658 - It's not a Bug, it's a Feature! 题目大意:有一个软件,有n个bug, 然后现在有m个补丁,然后m行,分别给出补丁需要的时间,以及原始状态和修复后的状态。对于原始状态,‘-’代表不能有这个bug,‘+’代表必须有这个bug,‘0’表示可有可无;对于修复后的状态,‘-’代表可以修复这个bug,‘+”代表会新增这个bug,’0‘
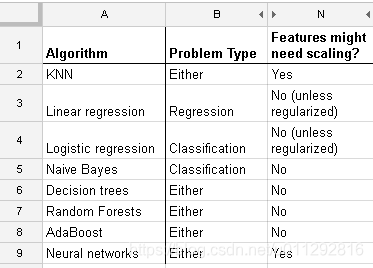
哪些机器学习算法需要进行特征缩放 - feature scaling
通常以距离或者相似度(例如标量积scaler product)作为计算量的算法: 例如KNN, SVM。 而基于概率图模型(graphical model)的算法:Fisher LDA ,Naive Bayes, Decision trees 和 Tree-based 集成方法 (RF, XGB)不会受到特征缩放的影响。 Reference: https://stats.stackexchang
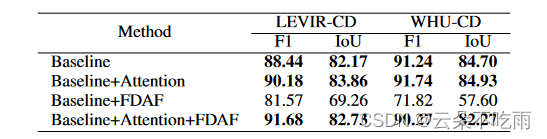
Feature Manipulation for DDPM based Change Detection
基于去噪扩散模型的特征操作变化检测 文章提出了一种基于去噪扩散概率模型(DDPM)的特征操作变化检测方法。变化检测是计算机视觉中的经典任务,涉及分析不同时间捕获的图像对,以识别场景中的重要变化。现有基于扩散模型的方法主要关注提取特征图,而本文的方法专注于操作扩散模型提取的特征图,使其在语义上更有用。文章提出了两种方法:特征注意力(Feature Attention)和流对齐融合(Flow Dua
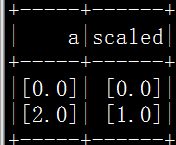
pyspark.ml.feature特征工程常用方法(二)
本篇博文主要是对pyspark.ml.feature模块的函数进行介绍,也可以直接看官网文档。其中博文的数据皆来自官方文档中例子。官方文档地址: http://spark.apache.org/docs/latest/api/python/pyspark.ml.html pyspark.ml.feature 函数概括: __all__ = ['Binarizer', 'Bucketizer',

pyspark.ml.feature特征工程常用方法(一)
本篇博文主要是对pyspark.ml.feature模块的函数进行介绍,也可以直接看官网文档。其中博文的数据皆来自官方文档中例子。官方文档地址: http://spark.apache.org/docs/latest/api/python/pyspark.ml.html pyspark.ml.feature 函数概括: __all__ = ['Binarizer', 'Bucketizer',
使用JGit来实现master分支和feature分支之间的代码比对并获取增量代码
为了使用JGit来实现master分支和feature分支之间的代码比对并获取增量代码,我们需要执行几个步骤。这里是一个大致的步骤说明和相应的Java代码示例: 初始化JGit仓库打开仓库获取master和feature分支的引用遍历两个分支的提交历史,找出不同的提交比较这些不同提交的更改,获取增量代码 注意:直接获取增量代码(如文件内容的变化)在JGit中可能相对复杂,因为JGit主要用于处