本文主要是介绍pyspark.ml.feature特征工程常用方法(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本篇博文主要是对pyspark.ml.feature模块的函数进行介绍,也可以直接看官网文档。其中博文的数据皆来自官方文档中例子。官方文档地址: http://spark.apache.org/docs/latest/api/python/pyspark.ml.html
pyspark.ml.feature 函数概括:
__all__ = ['Binarizer', 'Bucketizer', 'CountVectorizer', 'CountVectorizerModel', 'DCT',
'ElementwiseProduct', 'HashingTF', 'IDF', 'IDFModel', 'IndexToString', 'MinMaxScaler',
'MinMaxScalerModel', 'NGram', 'Normalizer', 'OneHotEncoder', 'PCA', 'PCAModel',
'PolynomialExpansion', 'RegexTokenizer', 'RFormula', 'RFormulaModel', 'SQLTransformer',
'StandardScaler', 'StandardScalerModel', 'StopWordsRemover', 'StringIndexer',
'StringIndexerModel', 'Tokenizer', 'VectorAssembler', 'VectorIndexer', 'VectorSlicer',
'Word2Vec', 'Word2VecModel']
1、MinMaxScaler(min=0.0, max=1.0, inputCol=None, outputCol=None)
MinMaxScaler归一化数据到特定的范围,被称为最小最大正则或者缩放。
计算公式如下:
Rescaled(e_i) = (e_i - E_min) / (E_max - E_min) * (max - min) + min
For the case E_max == E_min, Rescaled(e_i) = 0.5 * (max + min)
其中:[min,max]为欲归一化的特定范围,e_i待处理数据,E_max数据最大值,E_min数据最小值。
from pyspark.ml.feature import MinMaxScaler>>> from pyspark.ml.linalg import Vectors
>>> df = spark.createDataFrame([(Vectors.dense([0.0]),), (Vectors.dense([2.0]),)], ["a"])
>>> mmScaler = MinMaxScaler(inputCol="a", outputCol="scaled")
>>> model = mmScaler.fit(df)
>>> model.originalMin
DenseVector([0.0])
>>> model.originalMax
DenseVector([2.0])
>>> model.transform(df).show()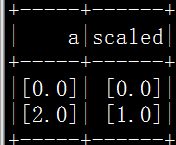
ss
这篇关于pyspark.ml.feature特征工程常用方法(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



