pyspark专题

Pyspark DataFrame常用操作函数和示例
针对类型:pyspark.sql.dataframe.DataFrame 目录 1.打印前几行 1.1 show()函数 1.2 take()函数 2. 读取文件 2.1 spark.read.csv 3. 获取某行某列的值(具体值) 4.查看列名 5.修改列名 5.1 修改单个列名 5.2 修改多个列名 5.2.1 链式调用 withColumnRenamed 方法 5.2.2 使用
pyspark.sql.types
示例: from datetime import datetime, datefrom decimal import Decimalfrom pyspark.sql import SparkSessionfrom pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType, Arr

计算机毕业设计Hadoop+PySpark共享单车预测系统 PyHive 共享单车数据分析可视化大屏 共享单车爬虫 共享单车数据仓库 机器学习 深度学习
《Hadoop共享单车分析与预测系统》开题报告 一、课题背景与意义 1.1 课题背景 随着共享经济的快速发展,共享单车作为一种新型绿色环保的共享经济模式,在全球范围内迅速普及。共享单车通过提供便捷的短途出行服务,有效解决了城市居民出行的“最后一公里”问题,同时促进了低碳环保和绿色出行理念的推广。然而,随着共享单车数量的急剧增加,如何高效管理和优化单车布局成为共享单车运营商面临的重要挑战。

Spark实战(四)spark+python快速入门实战小例子(PySpark)
由于目前很多spark程序资料都是用scala语言写的,但是现在需要用python来实现,于是在网上找了scala写的例子改为python实现 1、集群测试实例 代码如下: from pyspark.sql import SparkSession if __name__ == "__main__":spark = SparkSession\.builder\.appName("P

计算机毕业设计PyHive+Hadoop深圳共享单车预测系统 共享单车数据分析可视化大屏 共享单车爬虫 共享单车数据仓库 机器学习 深度学习 PySpark
毕业设计题目基于 Hadoop 的共享单车布局规划 二、毕业设计背景 公共交通工具的“最后一公里”是城市居民出行采用公共交通出行的主要障碍,也是建设绿色城市、低碳城市过程中面临的主要挑战。 共享单车(自行车)企业通过在校园、地铁站点、公交站点、居民区、商业区、公共服务区等提供服务,完成交通行业最后一块“拼图”,带动居民使用其他公共交通工具的热情,也与其他公共交通方式产生协同效应。 共享单车是

pyspark API使用方法说明
pyspark API使用方法说明 参考:https://blog.csdn.net/weixin_41734700/article/details/80542017 https://blog.csdn.net/zwahut/article/details/90638252?utm_medium=distribute.

计算机毕业设计PySpark+Scrapy高考推荐系统 高考志愿填报推荐系统 高考爬虫 协同过滤推荐算法 Vue.js Django Hadoop 大数据毕设
目 录 第1章 绪论 1.1 研究背景 1.2 国内外现状 1.2.1 国外研究现状 1.2.2 国内研究现状 1.3 主要研究内容 1.4 论文框架结构 第2章 相关开发技术与理论 2.1 前端技术 1.Vue框架技术 2.Element-Plus 2.2 后端技术 1.PySpark 2.Django框架 3.Scrapy技术 2.3 协同过滤算法 1.基于
Pyspark中的ROW对象使用
文章目录 Pyspark中的ROW对象使用Row对象介绍Row对象创建使用Row对象创建DataFrameDataFrame转换为row对象Row对象包含的方法asDict()count()index() Pyspark中的ROW对象使用 Row对象介绍 在PySpark中,Row对象是DataFrame的基本组成单元,它封装了DataFrame中的每一行数据。每行数据以R

jupyter中使用pyspark连接spark集群
目标:此文在jupyter中配置pyspark,并非配置pyspark的内核,而是希望在python3的内核下,使用pyspark连接spark集群. 准备:spark单机版 , jupyter notebook ,且两者不在同一机子上 1.安装 在默认的jupyter notebook中是没有pyspark包的,所以需要下载依赖包才行. 网上现在有2个包,支持python 去连接 spa

PySpark,一个超级强大的 Python 库
大家好!我是炒青椒不放辣,关注我,收看每期的编程干货。 一个简单的库,也许能够开启我们的智慧之门, 一个普通的方法,也许能在危急时刻挽救我们于水深火热, 一个新颖的思维方式,也许能激发我们无尽的创造力, 一个独特的技巧,也许能成为我们的隐形盾牌…… 神奇的 Python 库之旅,第 14 章 目录 一、初识 PySpark二、基本操作三、DataFrame 和 Spark SQL四、

一文让你记住Pyspark下DataFrame的7种的Join 效果
最近看到了一片好文,虽然很简单,但是配上的插图可以让人很好的记住Pyspark 中的多种Join 类型和实际的效果。原英文链接 Introduction to Pyspark join types - Blog | luminousmen 。 假设使用如下的两个DataFrame 来进行展示 heroes_data = [('Deadpool', 3), ('Iron man', 1),('G

计算机毕业设计Hive+Hadoop深圳共享单车预测系统 共享单车数据分析可视化大屏 共享单车爬虫 共享单车数据仓库 机器学习 深度学习 PySpark
步骤: 1.Python采集深圳政府公开数据平台的共享单车数据(最大可采集上亿2017-2021数据),并用百度逆地理编码服务解析经纬度获取位置信息。并将数据上传hdfs; 2.可使用sklearn、卷积神经网络等算法对数据进行分析,对共享单车的订单量进行有效预测; 3.使用PyHive、Hadoop等技术对hdfs中的共线单车数据进行离线分析(有需要的话后期可以改造成PySpark Scala

Windows单机安装配置mongodb+hadoop+spark+pyspark用于大数据分析
目录 版本选择安装配置Java环境配置Hadoop配置Spark配置 安装pyspark使用Jupyter Notebook进行Spark+ MongoDB测试参考 版本选择 根据Spark Connector:org.mongodb.spark:mongo-spark-connector_2.13:10.3.0 的前提要求 这里选择使用最新的MongoDB 7.0.12社区版
PySpark withColumn更新或添加列
原文:https://sparkbyexamples.com/pyspark/pyspark-withcolumn/ PySparkwithColumn()是DataFrame的转换函数,用于更改或更新值,转换现有DataFrame列的数据类型,添加/创建新列以及多核。在本文中,我将使用withColumn()示例向您介绍常用的PySpark DataFrame列操作。 PySpark wit
pyspark ERROR lzo.GPLNativeCodeLoader: Could not load native gpl library
使用pyspark出现问题: 14/10/24 14:51:40 ERROR lzo.GPLNativeCodeLoader: Could not load native gpl library java.lang.UnsatisfiedLinkError: no gplcompression in java.library.path cp /usr/lib/hadoo

Parallelize your massive SHAP computations with MLlib and PySpark
https://medium.com/towards-data-science/parallelize-your-massive-shap-computations-with-mllib-and-pyspark-b00accc8667c (能翻墙直接看原文) A stepwise guide for efficiently explaining your models using SHAP.
PythonSQL应用随笔4——PySpark创建SQL临时表
零、前言 Python中直接跑SQL,可以很好的解决数据导过来导过去的问题,本文方法主要针对大运算量时,如何更好地让Python和SQL打好配合。 工具:Zeppelin 语法:PySpark(Apache Spark的Python API)、SparkSQL 数据库类型:Hive 一、相关方法 .createOrReplaceTempView() 在PySpark中,createOrRe

计算机毕业设计Python+Django农产品推荐系统 农产品爬虫 农产品商城 农产品大数据 农产品数据分析可视化 PySpark Hadoop Hive
课题研究的意义,国内外研究现状、水平和发展趋势 研究意义21世纪是一个信息爆炸的时代,人们在日常生活中可接触到的信息量非常之巨大。推荐系统逐步发展,其中又以个性化推荐系统最为瞩目。个性化推荐系统的核心在于个性化推荐算法,该算法不需要用户提供明确的需求,而是使用从用户那里收集到的各种信息作为特征,进而为用户建立个性化的偏好模型,最终把满足个人品味和需求的信息推荐给用户。 随着国内电商环
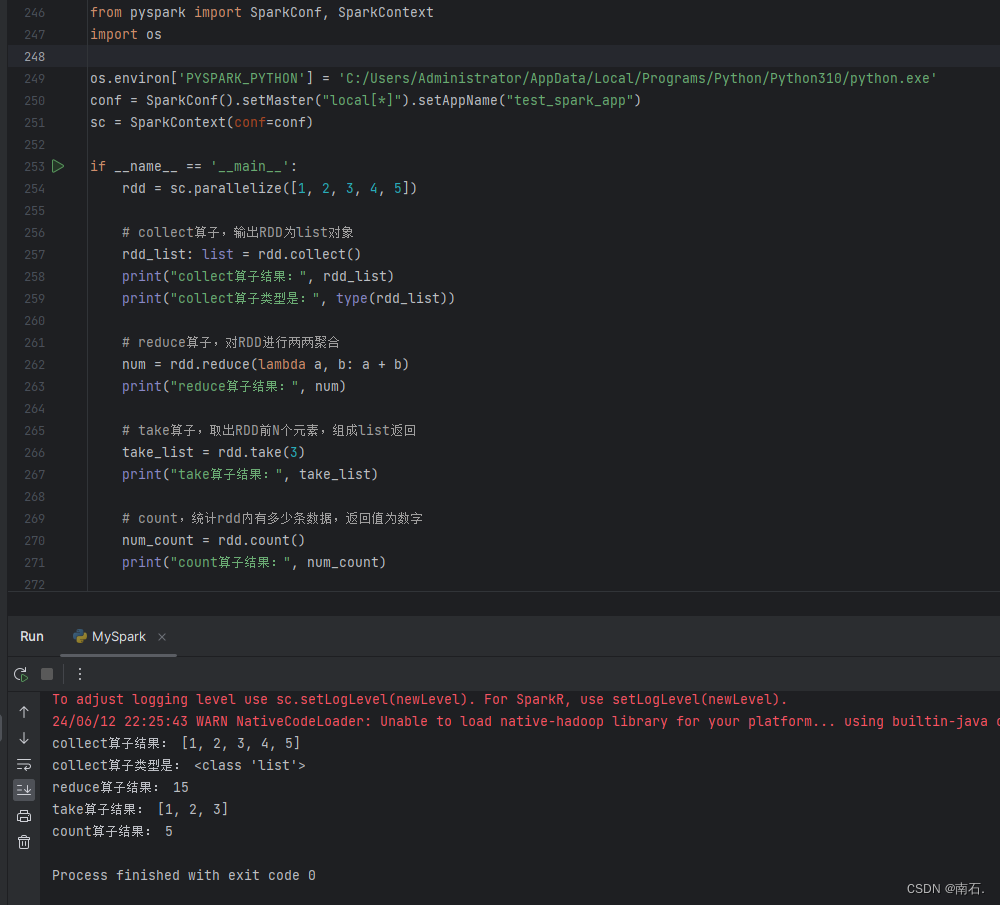
Python第二语言(十三、PySpark实战)
目录 1.开篇 2. PySpark介绍 3. PySpark基础准备 3.1 PySpark安装 3.2 掌握PySpark执行环境入口对象的构建 3.3 理解PySpark的编程模型 4. PySpark:RDD对象数据输入 4.1 RDD对象概念:PySpark支持多种数据的输入,完成后会返回RDD类的对象; 4.2 Python数据容器转RDD对象.parallelize

PyCharm 远程连接linux中Python 运行pyspark
PySpark in PyCharm on a remote server 1、确保remote端Python、spark安装正确 2、remote端安装、设置 vi /etc/profile 添加一行:PYTHONPATH= SPARKHOME/python/: SPARK_HOME/python/lib/py4j-0.8.2.1-src.zip source /etc/profile
利用pyspark评估lightgbm模型
1.打包conda虚拟环境并上传到hdfs (1)打包虚拟环境 cd /home/work/.conda/envs/light_gbm zip -r -q lgb.zip ./ 注意:这里打包的位置会影响到后面指定executor的pyspark环境。 一定要到虚拟环境light_gbm这一层目录下,而不是envs这一层目录 (2)把打包好的虚拟环境上传到hdfs hadoop fs
pyspark dataframe数据分析常用算子
目录 1.createDataFrame,创建dataframe2.show3. filter,过滤4.空值过滤空值填充5. groupBy,分组6.重命名列7.explode:一列变多行8.去重9. when10.union,合并dataframe11.like12.数据保存13.drop14.cast:数据类型转换 1.createDataFrame,创建datafram
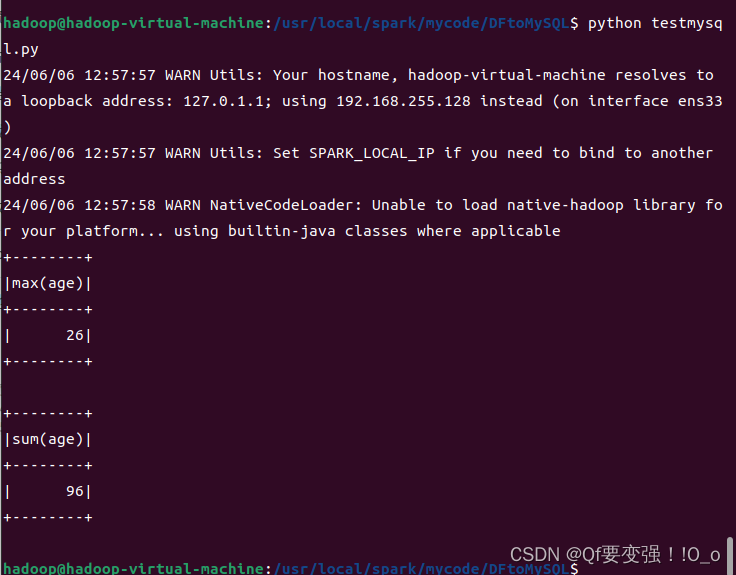
pyspark中使用mysql jdbc报错java.lang.ClassNotFoundException: com.mysql.jdbc.Driver解决
报错信息: py4j.protocol.Py4JJavaError: An error occurred while calling o33.load. : java.lang.ClassNotFoundException: com.mysql.jdbc.Driver 我的解决方法: 这个报错就是提示你找不到jar包,所以你需要去下载一个和你mysql版本匹配的jdbc connecto
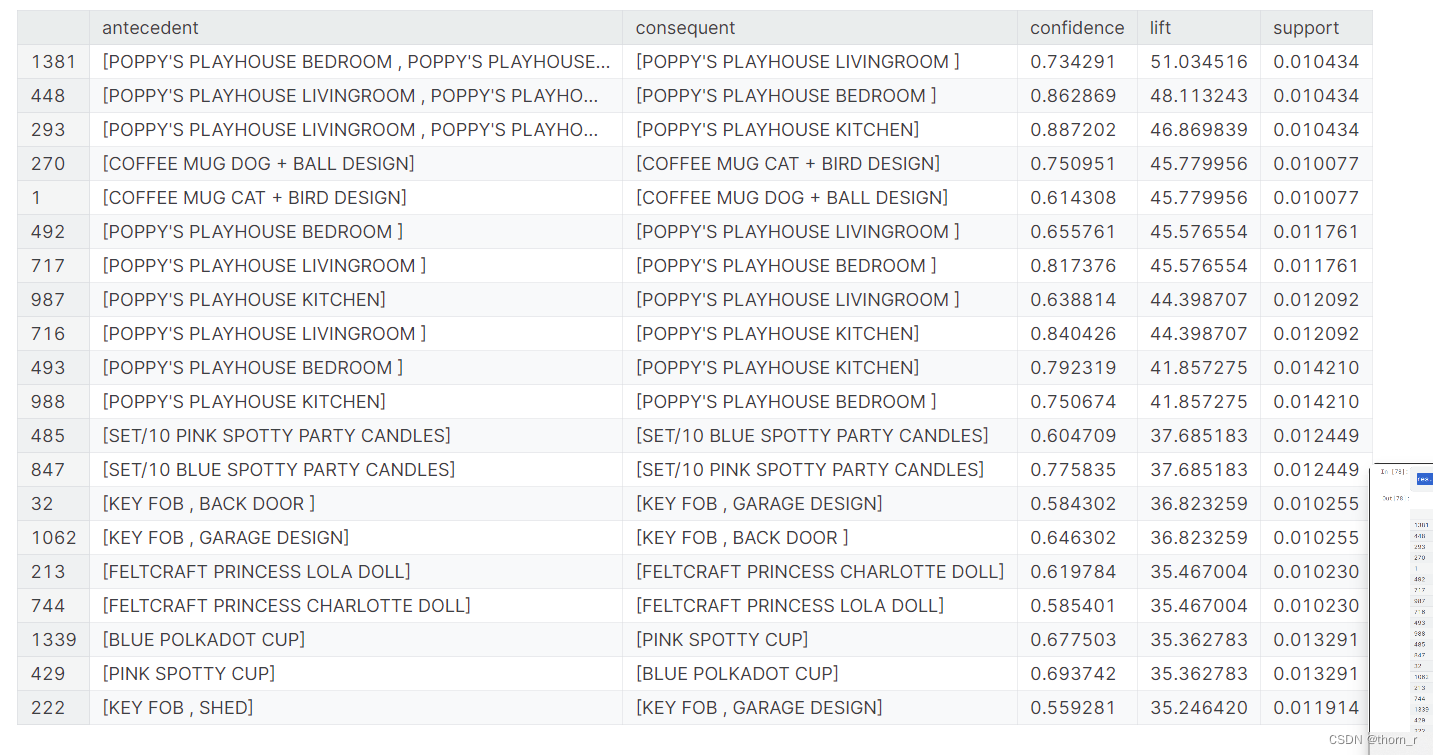
Kaggle线上零售 CRM分析(RFM+BG-NBD+生存分析+PySpark)
数据集地址:数据集地址 我的NoteBook地址:NoteBook地址 这个此在线零售数据集包含2009年12月1日至2011年12月9日期间的在线零售的所有交易。该公司主要销售独特的各种场合礼品。这家公司的许多客户都是批发商。本文将通过pyspark对数据进行导入与预处理,进行可视化分析并使用RFM、生存分析与BG-NBD模型进行对购买客户的各项分析。 1、数据集导入与清洗预处理 这一部分我

Linux 安装 pySpark
1、安装Java和Scale。 1.1、Java 参考 Java 安装运行 1.2、Scale安装 1)下载并解压 官网地址:https://www.scala-lang.org/download/ wget https://downloads.lightbend.com/scala/2.13.1/scala-2.13.1.tgz tar -zxvf scala-2.1
pyspark的安装配置
1、搭建基本spark+Hadoop的本地环境 https://blog.csdn.net/u011513853/article/details/52865076?tdsourcetag=s_pcqq_aiomsg 2、下载对应的spark与pyspark的版本进行安装 https://pypi.org/project/pyspark/2.3.0/#history 3、单词统