ml专题
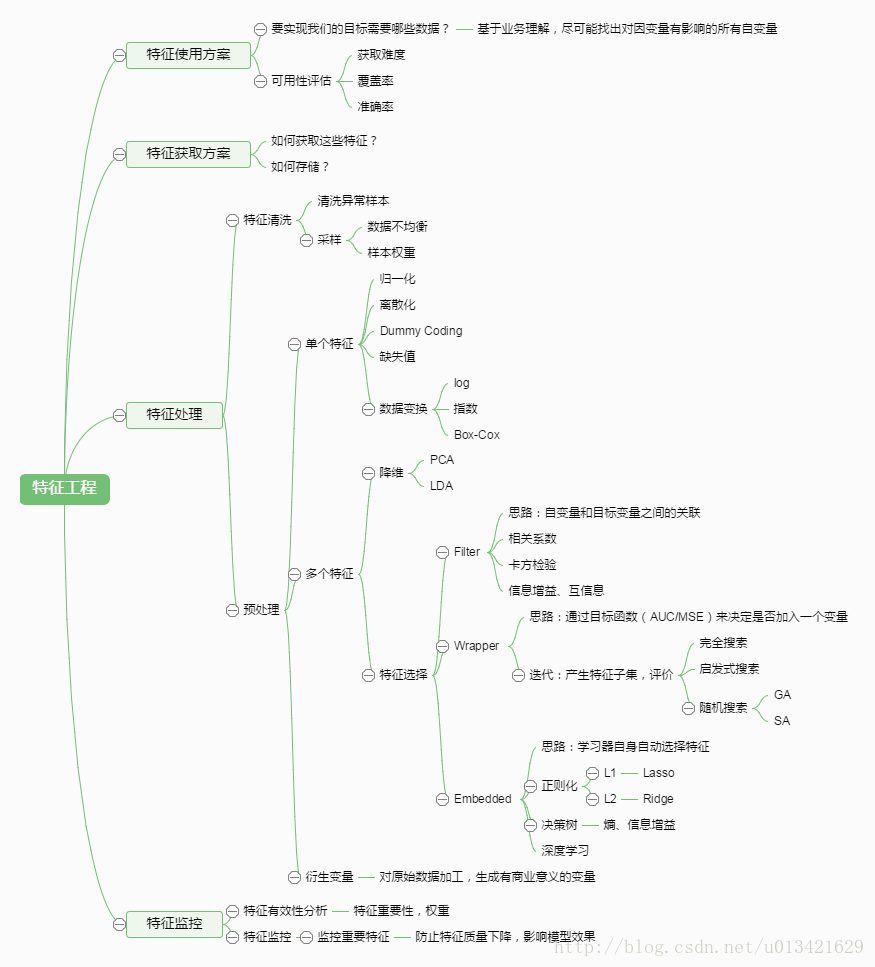
【ML--05】第五课 如何做特征工程和特征选择
一、如何做特征工程? 1.排序特征:基于7W原始数据,对数值特征排序,得到1045维排序特征 2. 离散特征:将排序特征区间化(等值区间化、等量区间化),比如采用等量区间化为1-10,得到1045维离散特征 3. 计数特征:统计每一行中,离散特征1-10的个数,得到10维计数特征 4. 类别特征编码:将93维类别特征用one-hot编码 5. 交叉特征:特征之间两两融合,x+y、x-y、

【ML--04】第四课 logistic回归
1、什么是逻辑回归? 当要预测的y值不是连续的实数(连续变量),而是定性变量(离散变量),例如某个客户是否购买某件商品,这时线性回归模型不能直接作用,我们就需要用到logistic模型。 逻辑回归是一种分类的算法,它用给定的输入变量(X)来预测二元的结果(Y)(1/0,是/不是,真/假)。我们一般用虚拟变量来表示二元/类别结果。你可以把逻辑回归看成一种特殊的线性回归,只是因为最后的结果是类别变
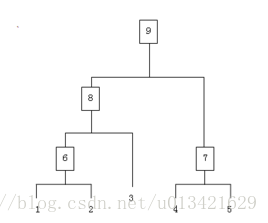
【ML--13】聚类--层次聚类
一、基本概念 层次聚类不需要指定聚类的数目,首先它是将数据中的每个实例看作一个类,然后将最相似的两个类合并,该过程迭代计算只到剩下一个类为止,类由两个子类构成,每个子类又由更小的两个子类构成。 层次聚类方法对给定的数据集进行层次的分解,直到某种条件满足或者达到最大迭代次数。具体又可分为: 凝聚的层次聚类(AGNES算法):一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来


智能科技的浪潮:AI、ML、DL和CV的探索之旅
智能科技的浪潮:AI、ML、DL和CV的探索之旅 前言人工智能:智能科技的基石从专用到通用:AI的分类与演进机器学习:数据中的智慧算法的力量:经典与创新深度学习:解锁复杂性之门神经网络的深度:基础与应用计算机视觉:赋予机器“看”的能力从看到理解:CV的挑战与应用未来展望:技术的融合与创新结语 前言 在这个信息爆炸、技术革新日新月异的时代,我们正站在一个全新科技革命的门槛上。

opencv之ML学习
OpenCV3.3中 K-最近邻法(KNN)接口简介及使用 https://blog.csdn.net/fengbingchun/article/details/78485669 OpenCV3.3中决策树(Decision Tree)接口简介及使用 https://blog.csdn.net/fengbingchun/article/details/78882055 OpenCV3.3中

ML学习导库出现的问题1
问题描述: 使用如下语句进行库的调用时,发现k_means_不存在,但是你确定有与此相关的,可能由于版本的原因名字有所更改 from sklearn.cluster.k_means_ import k_means 可以参考使用如下语句进行看 import sklearn.clusterprint(dir(sklearn.cluster)) ['AffinityPropagation'
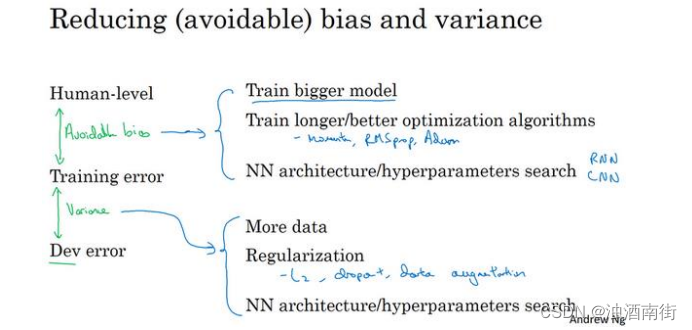
吴恩达深度学习笔记:机器学习(ML)策略(1)(ML strategy(1))1.11-1.12
目录 第三门课 结构化机器学习项目(Structuring Machine Learning Projects)第一周 机器学习(ML)策略(1)(ML strategy(1))1.11 超过人的表现(Surpassing human- level performance)1.12 改 善 你 的 模 型 的 表 现 ( Improving your model performance)

吴恩达深度学习笔记:机器学习(ML)策略(1)(ML strategy(1))1.9-1.10
目录 第三门课 结构化机器学习项目(Structuring Machine Learning Projects)第一周 机器学习(ML)策略(1)(ML strategy(1))1.9 可避免偏差(Avoidable bias)1.10 理解人的表现(Understanding human-level performance) 第三门课 结构化机器学习项目(Structurin
数学/ML/DL文章索引(2020.9.20更新)
西瓜书 1.绪论 2.模型评估与选择 3.线性模型 4.决策树 5.神经网络 6.svm 7.贝叶斯分类器 8.集成学习 9.聚类 10.降维与度量学习 11.特征选择与稀疏学习 12.计算学习理论 13.半监督学习 14.概率图 15.规则学习 16.强化学习 统计学习方法 5.决策树 6.逻辑回归与最大熵 7.支持向量机 8.提升方法 9.EM 10.隐马尔可夫 11.条件随机场 12.

使用 ML.NET CLI 自动进行模型训练
ML.NET CLI 可为 .NET 开发人员自动生成模型。 若要单独使用 ML.NET API(不使用 ML.NET AutoML CLI),需要选择训练程序(针对特定任务的机器学习算法的实现),以及要应用到数据的数据转换集(特征工程)。 每个数据集的最佳管道各不相同,从所有选择中选择最佳算法增加了复杂性。 此外,每个算法都有一组要调整的超参数。 因此,可能会花费数周甚至数月时间进行机器学习模

吴恩达深度学习笔记:机器学习(ML)策略(1)(ML strategy(1))1.3-1.4
目录 第三门课 结构化机器学习项目(Structuring Machine Learning Projects)第一周 机器学习(ML)策略(1)(ML strategy(1))1.3 单一数字评估指标(Single number evaluation metric)1.4 满足和优化指标(Satisficing and optimizing metrics) 第三门课 结构化

近屿OJAC带你解读:什么是ML?
概念定义 ML是机器学习(Machine Learning)的缩写。机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习和改进,而无需进行明确的编程指令。简单来说,机器学习涉及到开发算法和统计模型,让计算机利用数据来做出预测或决策。 机器学习为何重要? 为什么要使用机器学习?由于数据量越来越大,种类越来越多,计算能力越来越强,高速互联网越来越普及,机器学习的重要性与日俱增。这
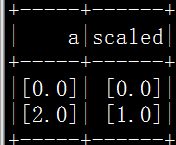
pyspark.ml.feature特征工程常用方法(二)
本篇博文主要是对pyspark.ml.feature模块的函数进行介绍,也可以直接看官网文档。其中博文的数据皆来自官方文档中例子。官方文档地址: http://spark.apache.org/docs/latest/api/python/pyspark.ml.html pyspark.ml.feature 函数概括: __all__ = ['Binarizer', 'Bucketizer',

pyspark.ml.feature特征工程常用方法(一)
本篇博文主要是对pyspark.ml.feature模块的函数进行介绍,也可以直接看官网文档。其中博文的数据皆来自官方文档中例子。官方文档地址: http://spark.apache.org/docs/latest/api/python/pyspark.ml.html pyspark.ml.feature 函数概括: __all__ = ['Binarizer', 'Bucketizer',
StanFord ML 笔记 第九部分
第九部分: 1.高斯混合模型 2.EM算法的认知 1.高斯混合模型 之前博文已经说明:http://www.cnblogs.com/wjy-lulu/p/7009038.html 2.EM算法的认知 2.1理论知识之前已经说明:http://www.cnblogs.com/wjy-lulu/p/7010258.html 2.2公式的推导 2.2.1. Jense
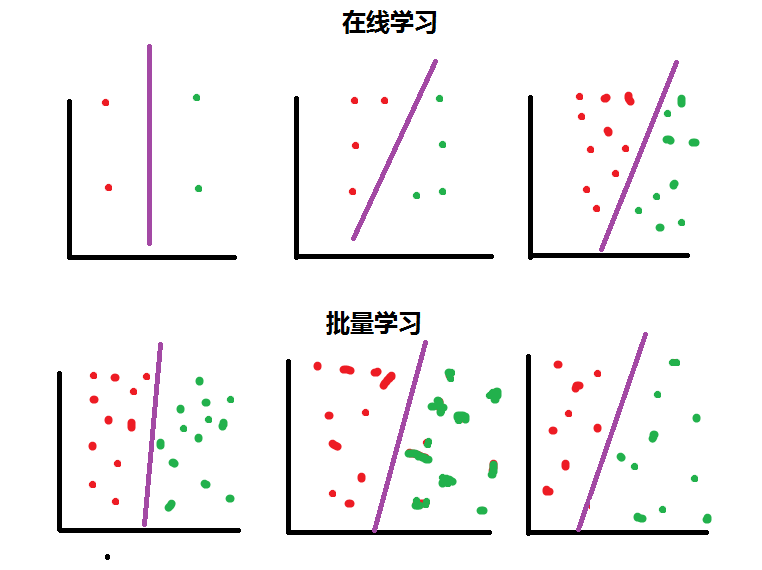
StanFord ML 笔记 第八部分
第八部分内容: 1.正则化Regularization 2.在线学习(Online Learning) 3.ML 经验 1.正则化Regularization 1.1通俗解释 引用知乎作者:刑无刀 解释之前,先说明这样做的目的:如果一个模型我们只打算对现有数据用一次就不再用了,那么正则化没必要了,因为我们没打算在将来他还有用,正则化的目的是为了让模型的
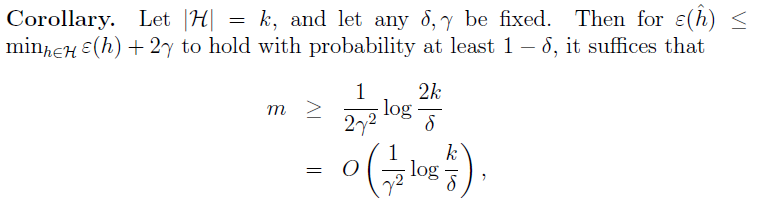
StanFord ML 笔记 第六部分第七部分
第六部分内容: 1.偏差/方差(Bias/variance) 2.经验风险最小化(Empirical Risk Minization,ERM) 3.联合界(Union bound) 4.一致收敛(Uniform Convergence) 第七部分内容: 1. VC 维 2.模型选择(Model Selection) 2017.11.3注释:这两个部分都是讲述理论
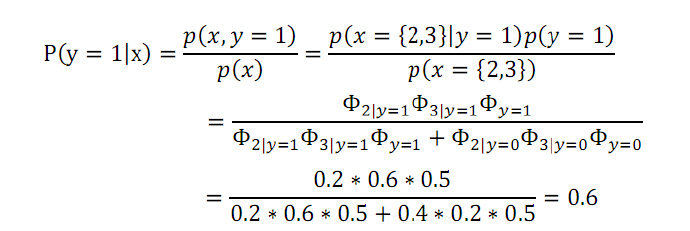
StanFord ML 笔记 第五部分
1.朴素贝叶斯的多项式事件模型: 趁热打铁,直接看图理解模型的意思:具体求解可见下面大神给的例子,我这个是流程图。 在上篇笔记中,那个最基本的NB模型被称为多元伯努利事件模型(Multivariate Bernoulli Event Model,以下简称 NB-MBEM)。该模型有多种扩展,一种是在上一篇笔记中已经提到的每个分量的多值化,即将p(x
Spark ML机器学习库评估指标示例
本文主要对 Spark ML库下模型评估指标的讲解,以下代码均以Jupyter Notebook进行讲解,Spark版本为2.4.5。模型评估指标位于包org.apache.spark.ml.evaluation下。 模型评估指标是指测试集的评估指标,而不是训练集的评估指标 1、回归评估指标 RegressionEvaluator Evaluator for regression,

深入浅出 Core ML
Machine Learning 基本介绍 机器学习是一门人工智能的科学。它通过对经验、数据进行分析,来改进现有的计算机算法,优化现有的程序性能。其基本流程如下图: 如图,机器学习有三个要素: 数据(Data)学习算法(Learning Algorith)模型(Model) 以图片分析 App 为例,这个场景下的数据、学习算法和模型分别对应: 数据:各种花的图片。这些数据称为此次机器学
【scikit-learn006】随机森林(Random Forest)ML模型实战及经验总结(更新中)
1.一直以来想写下基于scikit-learn训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架随机森林(Random Forest)相关知识体系 3.欢迎批评指正,欢迎互三,跪谢一键三连! 3.欢迎批评指正,欢迎互三,跪谢一键三连! 3.欢迎批评指正,欢迎互三,跪谢一
【scikit-learn003】K近邻ML模型实战及经验总结(更新中)
1.一直以来想写下基于scikit-learn训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架K近邻(K-Nearest Neighbors, KNN)机器学习模型相关知识体系 3.欢迎批评指正,欢迎互三,跪谢一键三连! 3.欢迎批评指正,欢迎互三,跪谢一键三连! 3
ML 算法之TF-IDF
TF-IDF直观来说就是来确定一个词对某一篇文档的重要性,而这个重要性的核定还用基于一个语料库。 由于TF-IDF这样的一个功能,它就可以被用来提取一个文档中的关键字 当我们有了关键字之后,关键字就又可以代表一个文档,并用其来计算文档之间的相似度 TF-IDF的解释: TF(term frequency)的计算:这个文档中的每个词出现的频率IDF(inverse document frequ