本文主要是介绍吴恩达深度学习笔记:机器学习(ML)策略(1)(ML strategy(1))1.11-1.12,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 第三门课 结构化机器学习项目(Structuring Machine Learning Projects)
- 第一周 机器学习(ML)策略(1)(ML strategy(1))
- 1.11 超过人的表现(Surpassing human- level performance)
- 1.12 改 善 你 的 模 型 的 表 现 ( Improving your model performance)
第三门课 结构化机器学习项目(Structuring Machine Learning Projects)
第一周 机器学习(ML)策略(1)(ML strategy(1))
1.11 超过人的表现(Surpassing human- level performance)
很多团队会因为机器在特定的识别分类任务中超越了人类水平而激动不已,我们谈谈这些情况,看看你们自己能不能达到。
我们讨论过机器学习进展,会在接近或者超越人类水平的时候变得越来越慢。我们举例谈谈为什么会这样。

假设你有一个问题,一组人类专家充分讨论辩论之后,达到 0.5%的错误率,单个人类专家错误率是 1%,然后你训练出来的算法有 0.6%的训练错误率,0.8%的开发错误率。所以在这种情况下,可避免偏差是多少?这个比较容易回答,0.5%是你对贝叶斯错误率的估计,所以可避免偏差就是 0.1%。你不会用这个 1%的数字作为参考,你用的是这个差值,所以也许你对可避免偏差的估计是至少 0.1%,然后方差是 0.2%。和减少可避免偏差比较起来,减少方差可能空间更大。
但现在我们来看一个比较难的例子,一个人类专家团和单个人类专家的表现和以前一样,但你的算法可以得到 0.3%训练错误率,还有 0.4%开发错误率。现在,可避免偏差是什么呢?现在其实很难回答,事实上你的训练错误率是 0.3%,这是否意味着你过拟合了 0.2%,或者说贝叶斯错误率其实是 0.1%呢?或者也许贝叶斯错误率是 0.2%?或者贝叶斯错误率是 0.3%呢?你真的不知道。但是基于本例中给出的信息,你实际上没有足够的信息来判断优化你的算法时应该专注减少偏差还是减少方差,这样你取得进展的效率就会降低。还有比如说,如果你的错误率已经比一群充分讨论辩论后的人类专家更低,那么依靠人类直觉去判断你的算法还能往什么方向优化就很难了。所以在这个例子中,一旦你超过这个 0.5%的门槛,要进一步优化你的机器学习问题就没有明确的选项和前进的方向了。这并不意味着你不能取得进展,你仍然可以取得重大进展。但现有的一些工具帮助你指明方向的工具就没那么好用了。

现在,机器学习有很多问题已经可以大大超越人类水平了。例如,我想网络广告,估计某个用户点击广告的可能性,可能学习算法做到的水平已经超越任何人类了。还有提出产品建议,向你推荐电影或书籍之类的任务。我想今天的网站做到的水平已经超越你最亲近的朋友了。还有物流预测,从𝐴到𝐵开车需要多久,或者预测快递车从𝐴开到𝐵需要多少时间。或者预测某人会不会偿还贷款,这样你就能判断是否批准这人的贷款。我想这些问题都是今天的机器学习远远超过了单个人类的表现。
请注意这四个例子,所有这四个例子都是从结构化数据中学习得来的,这里你可能有个数据库记录用户点击的历史,你的购物历史数据库,或者从𝐴到𝐵需要多长时间的数据库,以前的贷款申请及结果的数据库,这些并不是自然感知问题,这些不是计算机视觉问题,或语音识别,或自然语言处理任务。人类在自然感知任务中往往表现非常好,所以有可能对计算机来说在自然感知任务的表现要超越人类要更难一些。
最后,这些问题中,机器学习团队都可以访问大量数据,所以比如说,那四个应用中,最好的系统看到的数据量可能比任何人类能看到的都多,所以这样就相对容易得到超越人类水平的系统。现在计算机可以检索那么多数据,它可以比人类更敏锐地识别出数据中的统计规律。
除了这些问题,今天已经有语音识别系统超越人类水平了,还有一些计算机视觉任务,一些图像识别任务,计算机已经超越了人类水平。但是由于人类对这种自然感知任务非常擅长,我想计算机达到那种水平要难得多。还有一些医疗方面的任务,比如阅读 ECG 或诊断皮肤癌,或者某些特定领域的放射科读图任务,这些任务计算机做得非常好了,也许超越了单个人类的水平。
在深度学习的最新进展中,其中一个振奋人心的方面是,即使在自然感知任务中,在某些情况下,计算机已经可以超越人类的水平了。不过现在肯定更加困难,因为人类一般很擅长这种自然感知任务。所以要达到超越人类的表现往往不容易,但如果有足够多的数据,已经有很多深度学习系统,在单一监督学习问题上已经超越了人类的水平,所以这对你在开发的应用是有意义的。我希望有一天你也能够搭建出超越人类水平的深度学习系统。
1.12 改 善 你 的 模 型 的 表 现 ( Improving your model performance)
你们学过正交化,如何设立开发集和测试集,用人类水平错误率来估计贝叶斯错误率以及如何估计可避免偏差和方差。我们现在把它们全部组合起来写成一套指导方针,如何提高学习算法性能的指导方针。

所以我想要让一个监督学习算法达到实用,基本上希望或者假设你可以完成两件事情。首先,你的算法对训练集的拟合很好,这可以看成是你能做到可避免偏差很低。还有第二件事你可以做好的是,在训练集中做得很好,然后推广到开发集和测试集也很好,这就是说方差不是太
大。
在正交化的精神下,你可以看到这里有第二组旋钮,可以修正可避免偏差问题,比如训练更大的网络或者训练更久。还有一套独立的技巧可以用来处理方差问题,比如正则化或者收集更多训练数据。
总结一下前几段视频我们见到的步骤,如果你想提升机器学习系统的性能,我建议你们看看训练错误率和贝叶斯错误率估计值之间的距离,让你知道可避免偏差有多大。换句话说,就是你觉得还能做多好,你对训练集的优化还有多少空间。然后看看你的开发错误率和训练错误率之间的距离,就知道你的方差问题有多大。换句话说,你应该做多少努力让你的算法表现能够从训练集推广到开发集,算法是没有在开发集上训练的。
如果你想用尽一切办法减少可避免偏差,我建议试试这样的策略:比如使用规模更大的模型,这样算法在训练集上的表现会更好,或者训练更久。使用更好的优化算法,比如说加入 momentum 或者 RMSprop,或者使用更好的算法,比如 Adam。你还可以试试寻找更好的新神经网络架构,或者说更好的超参数。这些手段包罗万有,你可以改变激活函数,改变层数或者隐藏单位数,虽然你这么做可能会让模型规模变大。或者试用其他模型,其他架构,如循环神经网络和卷积神经网络。在之后的课程里我们会详细介绍的,新的神经网络架构能否更好地拟合你的训练集,有时也很难预先判断,但有时换架构可能会得到好得多的结果。
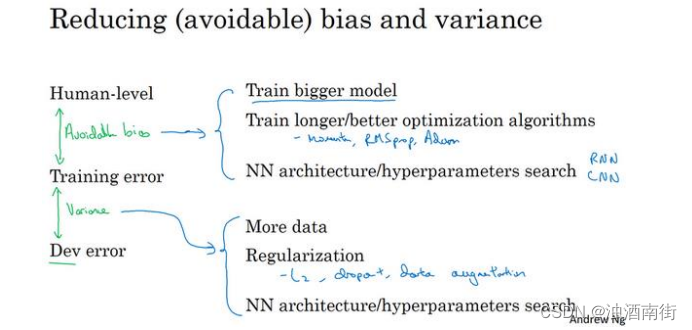
另外当你发现方差是个问题时,你可以试用很多技巧,包括以下这些:你可以收集更多数据,因为收集更多数据去训练可以帮你更好地推广到系统看不到的开发集数据。你可以尝试正则化,包括𝐿2正则化,dropout 正则化或者我们在之前课程中提到的数据增强。同时你也可以试用不同的神经网络架构,超参数搜索,看看能不能帮助你,找到一个更适合你的问题的神经网络架构。
我想这些偏差、可避免偏差和方差的概念是容易上手,难以精通的。如果你能系统全面地应用本周课程里的概念,你实际上会比很多现有的机器学习团队更有效率、更系统、更有策略地系统提高机器学习系统的性能。
这篇关于吴恩达深度学习笔记:机器学习(ML)策略(1)(ML strategy(1))1.11-1.12的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





