本文主要是介绍TNNLS:Fast Self-Supervised Clustering With Anchor Graph论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 Abstract
- 由于避免了使用通常在现实世界中不足的标记样本,无监督学习被视为在聚类任务中的快速和强大策略。然而,直接从原始数据集进行聚类会导致高计算成本,这限制了其在大规模和高维问题上的应用。最近,基于锚点的理论被提出来部分缓解这个问题,并自然地稀疏化了亲和力矩阵,但仍然存在挑战,即在保持高效性的同时获得出色的性能。为了解决这个问题,我们首先提出了一个快速的半监督框架(FSSF),结合了平衡的K均值基础的层次K均(BKHK)方法和二分图理论。此后,我们提出了一个涉及这一关键半监督框架的快速自监督聚类方法,在该方法中,所有标签都是从一个具有完全k个连通分量的构建的二分图中推断出来的。所提出的方法显著加速了一般的半监督学习,并通过锚点包含四个重要部分:1)通过BKHK算法获得锚点集作为临时结果;2)构建二分图;3)解决自监督问题,使用FSSF构建典型的概率模型;以及4)从BKHK中选择最具代表性的点作为锚点作为临时结果,并进行标签传播。在玩具示例和基准数据集上的实验结果表明,所提出的方法优于其他方法。
2 Algorithm

3 Optimization Strategy



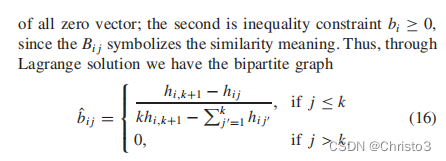

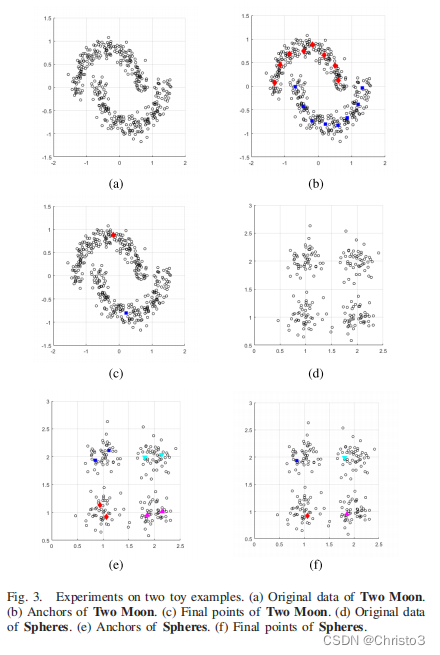
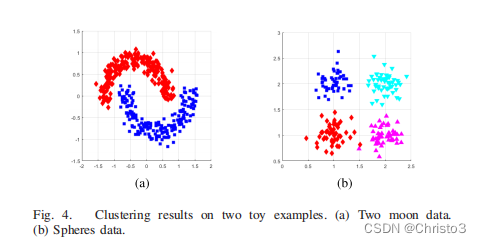
3 Performance
4 Advantages and Disadvantages
根据提供的摘要和文档内容,以下是所提出的快速自监督聚类方法(FSSC)的一些潜在优点和缺点的总结:
优点:
-
无需标记样本: FSSC作为一种无监督学习方法,避免了使用标记样本,这在现实世界中通常是稀缺的。
-
计算效率: 该方法通过使用平衡的K均值基础的层次K均值(BKHK)算法和二分图理论显著提高了计算效率,特别是在处理大规模和高维数据集时。
-
改进的聚类性能: 通过结合半监督学习和无监督方法,FSSC在聚类任务中提供了改进的性能。
-
自监督学习: 该方法利用自监督学习来提高聚类结果,这是一种新兴的学习范式,可以提高聚类的准确性。
-
代表性点选择: 通过特殊选择策略,FSSC能够从大量样本中选择最具代表性的点,这有助于提高聚类结果的质量。
缺点:
-
稳定性问题: 文档提到,由于K均值和标签传播的随机初始化,算法的稳定性可能存在问题。
-
参数选择: FSSC的性能可能受到参数选择(如锚点的数量和正则化参数)的影响,这可能需要额外的调整和验证。
-
算法复杂性: 尽管FSSC在计算效率上有优势,但算法的总体复杂性(特别是在构建二分图和计算软标签矩阵时)可能仍然是一个考虑因素。
视觉与控制前沿公众号,第一时间获取最有价值的前沿视觉与控制文章。

公众号链接视觉与控制公众号
这篇关于TNNLS:Fast Self-Supervised Clustering With Anchor Graph论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









