clustering专题

Spark MLlib模型训练—聚类算法 PIC(Power Iteration Clustering)
Spark MLlib模型训练—聚类算法 PIC(Power Iteration Clustering) Power Iteration Clustering (PIC) 是一种基于图的聚类算法,用于在大规模数据集上进行高效的社区检测。PIC 算法的核心思想是通过迭代图的幂运算来发现数据中的潜在簇。该算法适用于处理大规模图数据,特别是在社交网络分析、推荐系统和生物信息学等领域具有广泛应用。Spa

基于Python的机器学习系列(19):K均值聚类(K-Means Clustering)
简介 K均值聚类(K-Means Clustering)是一种常用的无监督学习算法,用于将数据样本划分为若干个“簇”,使得同一簇内的数据点彼此相似,而不同簇的数据点之间差异较大。由于K均值不依赖于标签,因此它是一种无监督学习方法。常见的应用包括客户细分、图像分割和数据可视化等。 K均值算法 K均值算法的基本步骤如下: 定义簇的数量 k(需手动设定)。初始化簇的质心,这些质心

Clustering-Guided Class Activation for WeaklySupervised Semantic Segmentation
pdf:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10381698 code:https://github.com/DCVL-WSSS/ClusterCAM 摘要: 基于transformer的弱监督语义分割(WSSS)方法利用其捕获全局上下文的强大能力得到了积极的研究。然而,由于激活函数在transformer的自注意

density based clustering algorithm,
1. 首先看到这个webSite讲的比较清楚,可以看下,https://blog.dominodatalab.com/topology-and-density-based-clustering/ We're hiring! BLOG HOME LEARN MORE ABOUT DOMINO Density-Based Clustering dat

Datacamp 笔记代码 Unsupervised Learning in Python 第二章 Visualization with hierarchical clustering t-SNE
更多原始数据文档和JupyterNotebook Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python Datacamp track: Data Scientist with Python - Course 23 (2) Exercise Hierarchical clustering of the grain
Datacamp 笔记代码 Unsupervised Learning in Python 第一章 Clustering for dataset exploration
更多原始数据文档和JupyterNotebook Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python Datacamp track: Data Scientist with Python - Course 23 (1) Exercise Clustering 2D points From the scatte

TNNLS:Fast Self-Supervised Clustering With Anchor Graph论文阅读
1 Abstract 由于避免了使用通常在现实世界中不足的标记样本,无监督学习被视为在聚类任务中的快速和强大策略。然而,直接从原始数据集进行聚类会导致高计算成本,这限制了其在大规模和高维问题上的应用。最近,基于锚点的理论被提出来部分缓解这个问题,并自然地稀疏化了亲和力矩阵,但仍然存在挑战,即在保持高效性的同时获得出色的性能。为了解决这个问题,我们首先提出了一个快速的半监督框架(FSSF),结合了

####好好好#####3【论文阅读】Deep Adversarial Subspace Clustering
导读: 本文为CVPR2018论文《Deep Adversarial Subspace Clustering》的阅读总结。目的是做聚类,方法是DASC=DSC(Deep Subspace Clustering)+GAN(Generative Adversarial Networks)。本文从以下四个方面来对论文做个简要整理: 背景:简要介绍与本文密切相关的基础原理,DSC,GAN。
text-clustering
The Text Clustering repository contains tools to easily embed and cluster texts as well as label clusters semantically example 我们的目标是在随机的网络样本中找到主题和他们的教育分数。这些主题用于创建合成数据生成的提示,并帮助我们理解所涵盖的领域范围。最初,我们对100
机器学习之模糊聚类(Fuzzy Clustering)附代码
概念 模糊聚类(Fuzzy Clustering)是一种聚类分析方法,与传统的硬聚类(Hard Clustering)不同,它允许样本属于多个聚类的成员关系程度不同。在模糊聚类中,每个数据点都被赋予属于每个聚类的隶属度(Membership Degree),而不是严格地归属于某一个聚类。这使得模糊聚类对于那些难以明确划分到某个特定聚类的数据更具有鲁棒性。 模糊聚类最常用的方法之一是模糊C均值(
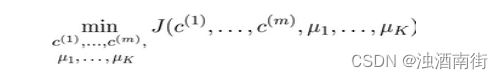
吴恩达机器学习笔记:第 8 周-13 聚类(Clustering)13.3-13.5
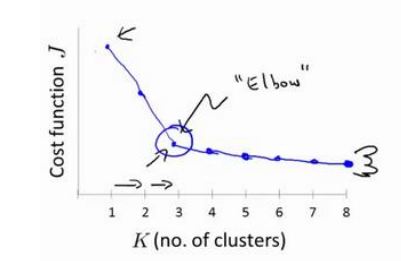
目录 第 8 周 13、 聚类(Clustering)13.3 优化目标 第 8 周 13、 聚类(Clustering) 13.3 优化目标 K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此 K-均值的代价函数(又称畸变函数 Distortion function)为: J ( c ( 1 ) , . . . , c ( m ) , u
吴恩达机器学习笔记:第 8 周-13 聚类(Clustering)13.1-13.2
目录 第 8 周 13、 聚类(Clustering)13.1 无监督学习:简介 第 8 周 13、 聚类(Clustering) 13.1 无监督学习:简介 在这个视频中,我将开始介绍聚类算法。这将是一个激动人心的时刻,因为这是我们学习的第一个非监督学习算法。我们将要让计算机学习无标签数据,而不是此前的标签数据。 那么,什么是非监督学习呢?在课程的一开始,我曾简单地介绍过

Windows Server 2003 Clustering Load Balancing
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Learn to implement clustering and load balancing solutions with Windows 2000 and Windows Server 2003, and
Data Clustering: Theory, Algorithms, and Applications
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Cluster analysis is an unsupervised process that divides a set of objects into homogeneous groups. This b
![[文献翻译] Space-variant blur kernel estimation and image deblurring through kernel clustering](https://gitee.com/Sweetmile/imagehost/raw/master/1580634917_20200202164546749_325.png)
[文献翻译] Space-variant blur kernel estimation and image deblurring through kernel clustering
目录 写在前面基于核聚类的空变模糊核估计以及图像去模糊摘要关键字 1. 介绍2.相关工作3.模糊核估计和去模糊框架3.1 图像块模糊核估计3.2 使用核聚类以优化模糊核3.3 通过图像融合进行空变去模糊 4. 实验结果5. 讨论6. 结论参考文献 写在前面 文章:Space-variant blur kernel estimation and image deblurring t
VMware vSphere 5.1 Clustering Deepdive
VMware vSphere 5.1 Clustering Deepdive HA.DRS.Storage DRS.Stretched Clusters Duncan Epping &Frank Denneman Translate By Tim2009 / 翻译:Tim2009 目录 版权 关于作者 知识点 前言 第一部分 vSphe
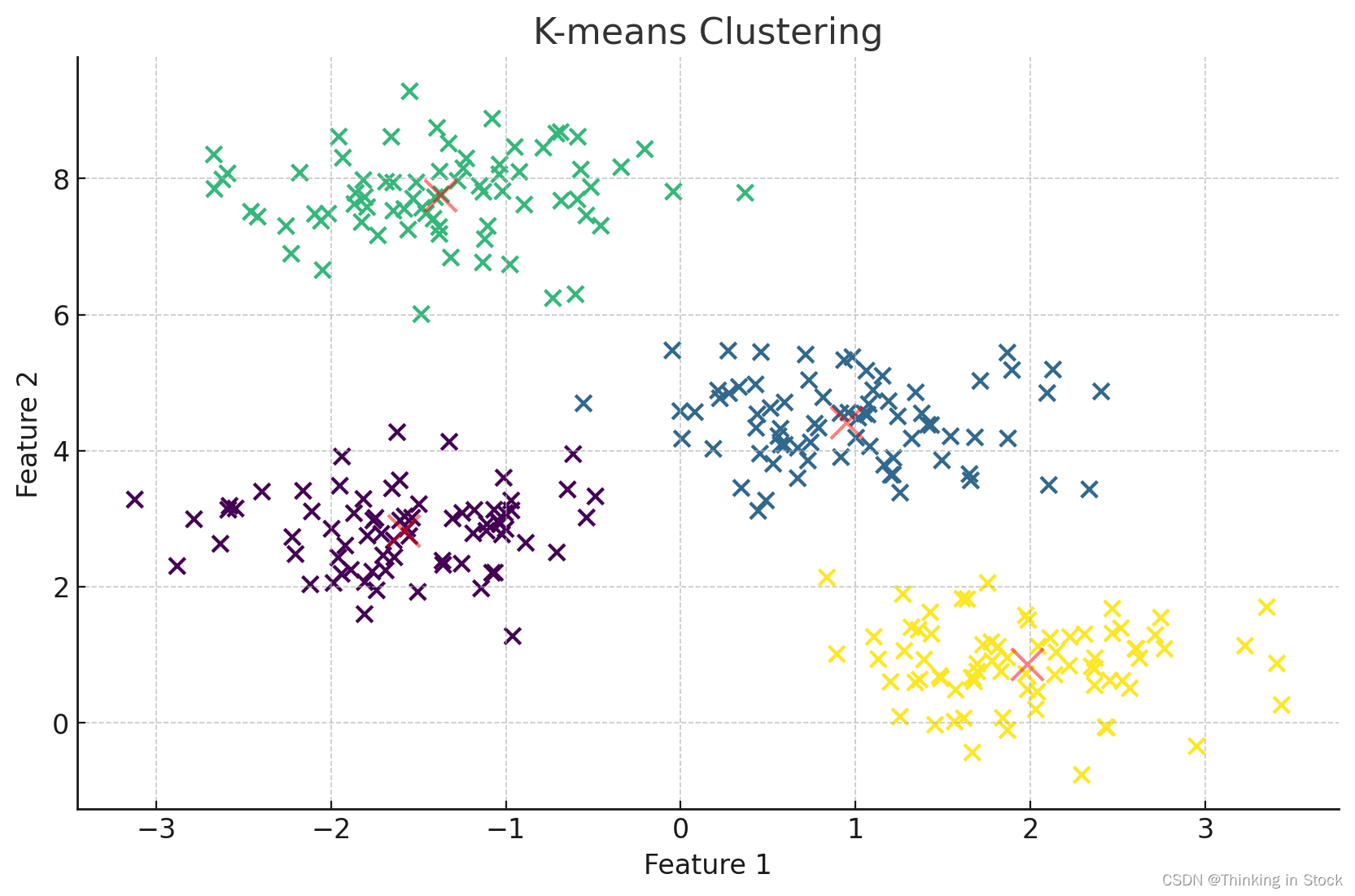
【理解机器学习算法】之Clustering算法(K-Means)
实现 K-means 聚类从零开始涉及几个关键步骤:初始化质心、将点分配给最近的质心、根据分配更新质心,以及重复这个过程直到收敛。这里是一个基本的 Python 实现: K-means 算法步骤: 初始化质心:从数据点中随机选择 `k` 个初始质心。将点分配给最近的质心:对于数据集中的每个点,找到最近的质心并将该点分配到那个簇中。更新质心:重新计算作为每个簇中所有点的平均值的质心。重复:重复步
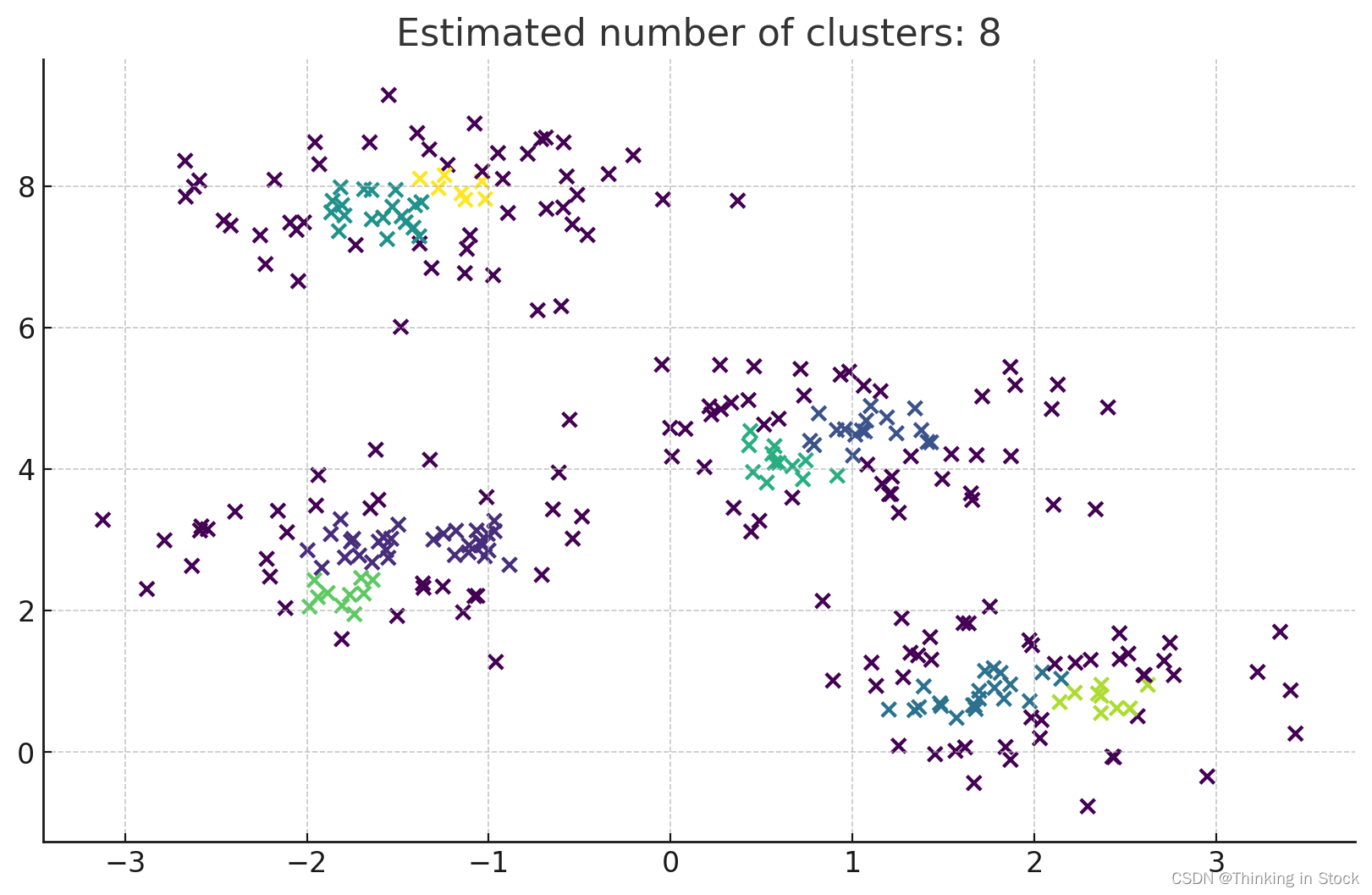
【理解机器学习算法】之Clustering算法(DBSCAN)
DBSCAN(基于密度的空间聚类应用噪声)是数据挖掘和机器学习中一个流行的聚类算法。与K-Means这样的划分方法不同,DBSCAN特别擅长于识别数据集中各种形状和大小的聚类,包括存在噪声和离群点的情况。 以下是DBSCAN工作原理的概述: 1. 核心概念: - Epsilon (ε):距离参数,指定点周围邻域的半径。 - 最小点数 (MinPts):形成密集区域所需的最小点数,这
机器学习_聚类(Clustering)
文章目录 简介K-均值算法(K_Means) 简介 你经常跟哪些人联系,而这些人又经常给哪些人发邮件,由此找到关系密切的人群。因此,这可能需要另一个聚类算法,你希望用它发现社交网络中关系密切的朋友。 K-均值算法(K_Means) K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。K-均值是一个迭代算法,假设我们想要将数据聚类成 n 个组,其
《Coupled Term-Term Relation Analysis for Document Clustering》文献笔记(上)
相关工作 这部分主要阐述了两点,一是介绍Document Clustering领域的背景知识,其实质内容只是介绍了Document Representation——Document Clustering领域的一小部分,以词包表示法为例,给出了文本表示的数学模型;二是相关工作,列举了研究词之间关系强度计算方法,以广义向量空间模型(BVSM)为分析重点。 文本
(七步走写摘要): UserInformation bottleneck fusion for deep multi-view clustering
原摘要: Multi-view clustering aims to employ semantic information from multiple perspectives to accomplish the clustering task. However, a crucial concern in this domain is the selection of distinctive f

微服务架构师封神之路13-RabbitMQ集群与高可用|RabbitMQ clustering and HA
目录 几个关键技术点 节点间相互验证,.erlang.cookie nodename的唯一性 port冲突与配置 Management UI plugin安装 Queue(message)replicas Queue leader strategy 配置文件详细 Node 1 Installation path .erlang.cookie rabbitmq-env.con
oracle行预取(raw prefecting)和聚簇因子(clustering_factor)
oracle行预取(raw prefecting)和聚簇因子(clustering_factor) 转自:行预取(raw prefecting)和聚簇因子(clustering_factor) 背景介绍 行预取: 每次应用程序请求驱动从数据库返回1条记录的时候,会预取多条记录并将它们存储在客户端的内存中。这样,多个连续的请求就不需要执行数据库的调用来读取数据。可以直接从客户端内存中得到他们

An Attention-driven Two-stage Clustering Method for Unsupervised Person Re-Identification论文解读
ECCV 2020 论文地址:http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123730018.pdf 动机 采用聚类方法容易让同一个相机得到的行人图像聚到一个类别中。因为它们的背景具有很大的相似性。 第二行没有采用attention,第三行用了attention 思路 attention-driven two-stag
![[python] 层次聚类 Agglomerative Clustering](https://img-blog.csdnimg.cn/20190408155241445.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3N0YUh1cmk=,size_16,color_FFFFFF,t_70)
[python] 层次聚类 Agglomerative Clustering
层次聚类 下图中动物 就是一种层次分类 主要函数 cls = AgglomerativeClustering(n_clusters=group_size,linkage='ward') linkage 参数说明: ward (默认值):每一个类簇的方差最小化average:每一个类簇之间的距离的平均值最小complete:每一个类簇之间的距离最大single:每一个类簇之间的距离最小

转:Spectral Embedding/Clustering
转:Spectral Embedding/Clustering(http://blog.sina.com.cn/s/blog_4a1853330100zzrx.html) (2012-02-25 22:03:50) 转载▼ 标签: it 分类: AboutResearch 广义上来说,任何在算法中用到SVD/特征值分解的,都叫Spectral Algorithm。从很老很