本文主要是介绍An Attention-driven Two-stage Clustering Method for Unsupervised Person Re-Identification论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ECCV 2020
论文地址:http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123730018.pdf
动机
采用聚类方法容易让同一个相机得到的行人图像聚到一个类别中。因为它们的背景具有很大的相似性。

第二行没有采用attention,第三行用了attention
思路
attention-driven two-stage clustering(ADTC)。两个步骤:1、用无监督注意力机制将学习到的背景特征转到前景特征;2、聚类分两步:k均值产生聚类中心;k相互杰卡德距离度量重新聚类数据。
背景
1、注意力机制在有监督方法中经常使用:用于突出行人的衣服等特征,而忽略背景;但目标i域没有Label,不能直接套用。当前有种思路:用姿态估计模型作为attention机制的硬标签,但计算复杂度更高了。
2、attention机制
attention分类:hard-attention——依赖姿态估计模型定位区域 ; soft-attention——在网络中插入一些可训练的层作为feature map的 mask;
soft-attention分类:空间注意力——专注于特征的不同空间位置 ; 通道注意力—— 对通道进行重新校准。
本文结合空间和通道注意力机制(可参考论文Harmo-nious Attention Convolutional Neural Network)
方法

voxel attention(VA)
结合了空间和通道注意力
空间注意力计算方法(无学习参数):
1、沿通道计算每个空间位置的平均激活值
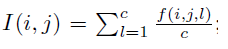
2、对 I 加一个softmax:
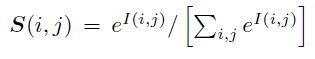
通道注意力计算方法(参考论文Squeeze-and-excitation networks):
1、对 f 用GAP 将全局信息压缩到通道上(本质上就是池化到 1x1 大小)
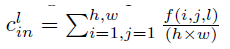
2、用**两个 FC 层(中间那层的channel数要远远小于原始的通道数)**实现通道间的信息捕获
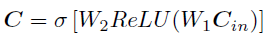
最终的feature map是两部分乘积:(理解:用 S 的每个位置和C中单独每个通道相乘)
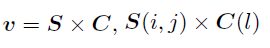
Two-stage clustering(TC)
分两步
1、用 kmeans++ 方法获得聚类中心;
2、计算其他数据与聚类中心的k互助杰卡德距离,重新分配(本质上就是先对feature re-rank,再计算杰卡德距离,和MMT的DBSCAN类似)
注意:
1、聚类用的是经过 attention 之后的 feature
2、删除了有歧义的伪标签
交替训练
1、仅采用三元损失,而不用分类损失(模型会学习失败,因为聚类效果会在每一次交替训练中都不一样。)
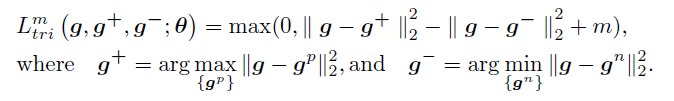

结果
做了纯无监督和跨域无监督
w/o DA 表示没有在源域训练的结果
个人理解: attention + 循环聚类 的效果还是可以的,值得尝试

下图说明VA可以将positive和query(pq)之间距离拉近,拉远negative和query(nq)
横坐标 是nq - pq

这篇关于An Attention-driven Two-stage Clustering Method for Unsupervised Person Re-Identification论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






