本文主要是介绍科研训练第六周:关于《Learn from Syntax: Improving Pair-wise Aspect and Opinion Terms Extraction with Ric》的复现——,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
时间确实比较紧张,进度稍微有点停滞,课设结束啦,我得赶一下科研的进度~~
服务器的内存不够用是我没想到的,大概是有别人也在跑叭

数据处理感觉还是得本地跑一下然后save,云端报错如下:
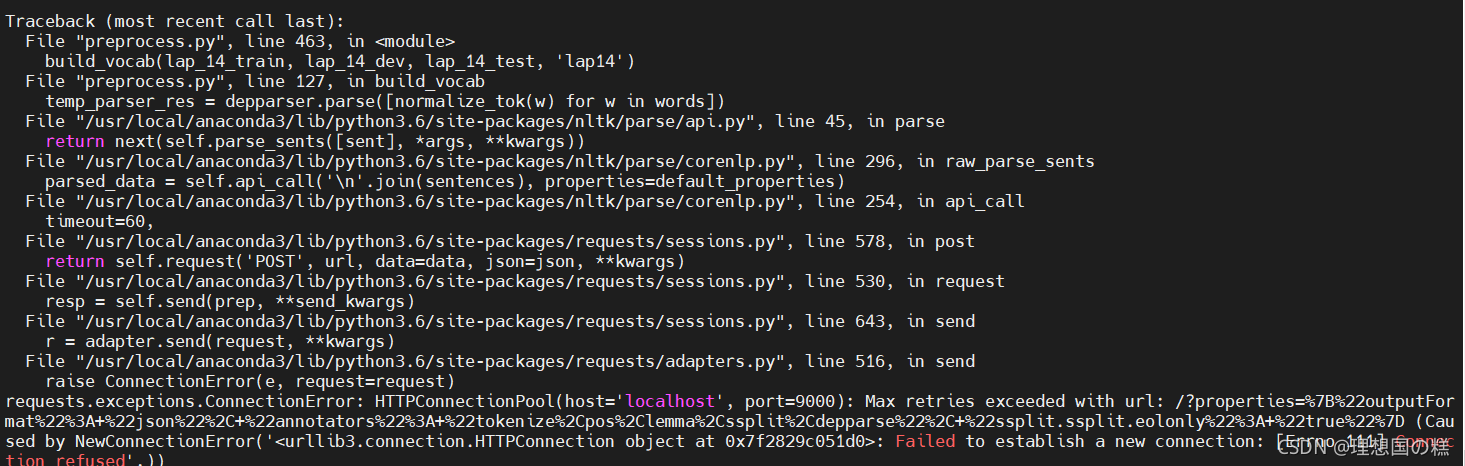
看回答说是request请求太多被拒绝了🙄
————————————10.18————————————————————
本周的计划:
- 完成数据预处理阶段的事情(大概是一直到词向量生成阶段叭)
- datasets下的文件全部看完(自己上手写一下)
- 读论文叭(感觉还是要有输入才行)
这周赶进度,不然下周又开始忙起来啦!
————————————10.19————————————————————
果然是服务器被占用的问题,下次还是乘早跑代码(哈哈,悄悄写bug然后惊吓所有人),不过预处理部分的话,其实用资源的地方还是不多。本地的遗留问题还是得解决
贴一下io_utils.py的问题:
好像服务器不同接口用的yaml的版本有区别,11021端口的话,Loader=yaml.FullLoader需要注释掉才能正常运行,11022和本地的话必须加上这个,否则报错(第22行)
def read_yaml(path, encoding='utf-8'):with open(path, 'r', encoding=encoding) as file:#input, Loader=yaml.FullLoaderreturn yaml.load(file.read(),Loader=yaml.FullLoader)
结束了数据处理,因为是原始文件生成json所以那部分的代码自己的本周的要求是跑通就好,
之前在terminal一直报错(什么远程服务器拒绝连接),但是诡异的是用pycharm直接run的时候又没有问题了,但是源码里的路径需要自己修改一下
要求是写完单词表示部分的代码,一开始觉得还好,看完才知道一堆代码要啃吖😂
关于LAGCN
import torch
import torch.nn as nn
class LAGCN(nn.Module):"""也就是说,这一层有前馈与反馈"""def __init__(self,dep_dim,in_features,out_features,pos_dim=None,bias=True):"""in_features:bert_dimout_features:bert_dim"""super(LAGCN,self).__init__()self.dep_dim=dep_dim #依赖边的维度self.pos_dim=pos_dim #pos维度self.in_features=in_features #词向量的维度self.out_features=out_features"""# 一个说明:对输入数据做线性变换:\(y = Ax + b\)# 参数: in_features - 每个输入样本的大小 out_features - 每个输出样本的大小# bias - 若设置为False,这层不会学习偏置。默认值:True 形状"""self.dep_attn=nn.Linear(dep_dim+pos_dim+in_features,out_features)self.dep_fc=nn.Linear(dep_dim,out_features)#TODO:应该是对于依赖的参数self.pos_fc=nn.Linear(pos_dim,out_features)#TODO:对于pos的参数def forward(self,text,adj,dep_embed,pos_embed=None):""":param text: [batch size, seq_len, feat_dim]:param adj: [batch size, seq_len, seq_len]--------------------------依赖边的邻接矩阵:param dep_embed: [batch size, seq_len, seq_len, dep_type_dim]:param pos_embed: [batch size, seq_len, pos_dim]:return: [batch size, seq_len, feat_dim]"""batch_size,seq_len,feed_dim=text.shapeval_us=text.unsqueeze(dim=2)# 应该是对于默认位置插入维度2val_us=val_us.repeat(1,1,seq_len,1)# 沿着指定的维度重复tensorpos_us=pos_embed.unsqueeze(dim=2).repeat(1,1,seq_len,1)# 最终得到的形状是[batch_size seq_len,seq_len,feat_dim+pos_dim+dep_dim]val_sum=torch.cat([val_us,pos_us,dep_embed],dim=-1)# 横向拼接r=self.dep_attn(val_sum)p=torch.sum(r,dim=-1)#TODO:不懂mask=(adj==0).float()*(-1e30)#TODO:是对于不存在依赖边的一种最小化他们的影响吗p=p+maskp=torch.softmax(p,dim=2)p_us=p.unsqueeze(3).repeat(1,1,1,feed_dim)output=val_us+self.pos_fc(pos_us)+self.dep_fc(dep_embed)output=torch.mul(p_us,output)output_sum=torch.sum(output,dim=2)# 输出的那个给顶层使用的return r,output_sum,p#这个输出
——————————————10.21————————————————
关于coreNlp:

命令行输入,保持cmd的窗口打开,9000窗口可以运行
java -mx4g -cp “*” edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000
————————10.24——————
节日快乐
写完bert的小DEMO啦
开心😃

这篇关于科研训练第六周:关于《Learn from Syntax: Improving Pair-wise Aspect and Opinion Terms Extraction with Ric》的复现——的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







