wise专题

【深度学习】Position Wise 到底是什么,有什么用
1. 遇到的问题 今天在看 Transformers 的前生今世 的时候,又一次看到了 Position Wise ,经常看到但老是一知半解,故索性查了一下,发现网上的都没怎么细讲其缘由,有点差强人意,于是我又用咱们最喜欢的 GPT-4o 查了一下,感觉给的答案较为全面,故分享给大家。 2. 关于 Position Wise “Position Wise”在神经网络和深度学习领域通常指的是一

【论文笔记】Layer-Wise Weight Decay for Deep Neural Networks
Abstract 本文为了提高深度神经网络的训练效率,提出了逐层权重衰减(layer-wise weight decay)。 本文方法通过逐层设置权重衰减稀疏的不同值,使反向传播梯度的尺度与权重衰减的尺度之比在整个网络中保持恒定。这种设置可以避免过拟合或欠拟合,适当地训练所有层,无需逐层调整系数。 该方法可在不改变网络模型的情况下提升现有DNN的性能。 1 Introduction 很多机器

Wise Registry Cleaner 7全新体验技巧教程
Wise Registry Cleaner 7全新体验技巧教程 软件的使用、卸载都会留下一些无用的残留注册表项,日积月累这些注册表垃圾文件会变得越来越多,会对系统的运行速度以及稳定性造成影响,这时我们就需要借助工具来对这些文件进行清理。Wise Registry Cleaner就是这样一款免费的专业注册表优化工具,它可以快速清理注册表中的垃圾文件,对注册表进行整理加快系统运行速度;另外它还可

管易云与金蝶K3-WISE对接集成发货单查询2.0打通新增销售出库(红蓝字)
管易云与金蝶K3-WISE对接集成发货单查询2.0打通新增销售出库(红蓝字) 源系统:管易云 金蝶管易云是金蝶集团旗下以电商和新零售为核心业务的子公司,公司于2008年成立,拥有从事电商及新零售业务相关专业知识工作者超过1000人。为伊利、网易有道、东阿阿胶、金龙鱼、海康、科大讯飞等超过110000家企业客户提供专业服务,用户数超过100万人。金蝶管易云与淘宝、天猫、京东、拼多多、抖音等
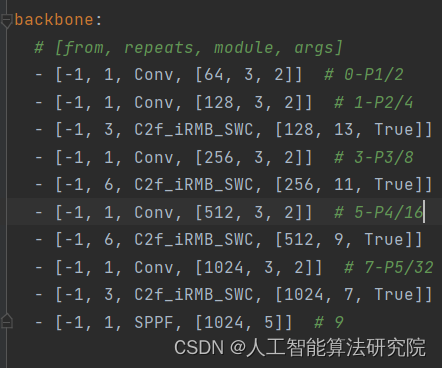
YOLOv8算法改进【NO.111】利用shift-wise conv对顶会提出EMO中的iRMB进行二次创新
前 言 YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通: 首推,是将两种最新推出算法的模块进行融合形成最为一种新型自己提出的模块然后引入到YOLO算法中,可以起个新的名字,这种改进是最好发高水平期刊论文。后续改进将主要教大

【YOLOv5改进系列(2)】高效涨点----Wise-IoU详细解读及使用Wise-IoU(WIOU)替换CIOU
WIOU损失函数替换 🚀🚀🚀前言一、1️⃣ Wise-IoU解读---基于动态非单调聚焦机制的边界框损失1.1 🎓 介绍1.2 ✨WIOU解决的问题1.3 ⭐️论文实验结果1.4 🎯论文方法1.4.1☀️Wise-IoU v11.4.2☀️Wise-IoU v21.4.3☀️Wise-IoU v3 二、2️⃣如何添加WIOU损失函数2.1 🎓 修改bbox_iou函数

科研训练第六周:关于《Learn from Syntax: Improving Pair-wise Aspect and Opinion Terms Extraction with Ric》的复现——
时间确实比较紧张,进度稍微有点停滞,课设结束啦,我得赶一下科研的进度~~ 服务器的内存不够用是我没想到的,大概是有别人也在跑叭 数据处理感觉还是得本地跑一下然后save,云端报错如下: 看回答说是request请求太多被拒绝了🙄 ————————————10.18———————————————————— 本周的计划: 完成数据预处理阶段的事情(大概是一直到词向量生成阶段叭)data

YOLOv8 | 有效涨点,添加GAM注意力机制,使用Wise-IoU有效提升目标检测效果(附报错解决技巧,全网独家)
目录 摘要 基本原理 通道注意力机制 空间注意力机制 GAM代码实现 Wise-IoU WIoU代码实现 yaml文件编写 完整代码分享(含多种注意力机制) 摘要 人们已经研究了各种注意力机制来提高各种计算机视觉任务的性能。然而,现有方法忽视了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,我们提出了一种全局注意力机制,通过减少信息减少和放大全局交互表示
YOLOv8有效涨点,添加GAM注意力机制,使用Wise-IoU有效提升目标检测效果
目录 摘要 基本原理 通道注意力机制 空间注意力机制 GAM代码实现 Wise-IoU WIoU代码实现 yaml文件编写 完整代码分享(含多种注意力机制) 摘要 人们已经研究了各种注意力机制来提高各种计算机视觉任务的性能。然而,现有方法忽视了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,我们提出了一种全局注意力机制,通过减少信息减少和放大全局交互表示来
![[planet] Rudiger Ehlers - Formal Verification of Piece-Wise Linear Feed-Forward Neural Networks](https://img-blog.csdnimg.cn/20210409170045615.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3N3YWxsb3dibGFuaw==,size_16,color_FFFFFF,t_70)
[planet] Rudiger Ehlers - Formal Verification of Piece-Wise Linear Feed-Forward Neural Networks
Title: Formal Verification of Piece-Wise Linear Feed-Forward Neural NetworksAuthor: Rudiger Ehlers 1 Introduction 2 Preliminaries Satisfiability solvers: 可满足性(SAT)求解器检查布尔公式是否具有可满足的赋值。 该公式通常要求是连词形

Wise Installation使用中注意问题 总结
最近在用Wise Installation 9.02打包工具制作一个软件的安装程序,这里面遇到了一些问题,经过网上查找资料研究,最后还是搞出来了。 每次要被安装的文件有更新时,都要用wise重新打包,点击下“编译”就会重新生产 *.exe安装程序。因为之前生成的安装包.exe里包含的文件是以前的,而不是最新的 1、对话框变量radio或复选框的值为ABCDE…..其中之一,可以添加一个radi
(1)金蝶wise二次开发--环境准备
1.安装金蝶wise 13.1安装下载地址:链接:https://pan.baidu.com/s/1fgBOOe8Og2T2BbViryNSrg 提取码:je5d 13.1特别工具下载:传不上去 2.安装vb6.0 用于中间层及客户端插件开发,由于金蝶是使用vb开发的,金蝶有一个vb的插件可以方便开发,(期实使用其它开发工具也能行,有时我用Qt) vb安装包及常用文档下载:链接:https://p

微众税银入选36氪「2019 WISE 新商业企业榜单」!
是的,我们又上榜了! 36氪「2019 WISE 新商业企业榜单」榜单评选出”100 家新商业引领者“和 ”100 家新商业开创者“企业,作为大数据征信和大数据风控的先行者——微众税银实力入选 “100 家新商业开创者”企业榜单 ! 榜单发布方阐释: 入选者在商业模式、产品能力、技术创新和融资历程上都有着极为突出的表现。 36氪新商业榜单聚焦的是具备真正投资价值的破局者。评委认为,他们能够经

Wise Install打包问题
问题: 在用Wise Install给vc程序打包后,在别的电脑上安装。 在安装的过程中提示“没有找到kmpapi32.dll,因此这个应用程序未能启动。重新安装应用程序可能会修复此问题。” 另外还有一个oraemmas10.dll的文件。 点确定后,继续安装,等安装完成后,程序也可以正常运行,没什么问题。 我在我的电脑和网上搜了,没见到有这2个动态链接库下载的,请问这是什么问题导致的呢?该怎样
Point-wise、Pair-wise、List-wise区别
在Information Retrieval领域一般按照相关度进行排序。比较典型的是搜索引擎中一条查询query,将返回一个相关的文档document,然后根据(query,document)之间的相关度进行排序,再返回给用户。而随着影响相关度的因素变多,使用传统排序方法变得困难,人们就想到通过机器学习来解决这一问题,这就导致了LRT的诞生。 Ranking模型可以粗略分为基于相关度和机遇重要性

(超详细)10-YOLOV5改进-替换CIou为Wise-IoU
yolov5中box_iou其默认用的是CIoU,其中代码还带有GIoU,DIoU,文件路径:utils/metrics.py,函数名为:bbox_iou 将下面代码放到metrics.py文件里面,原来的bbox_iou函数删掉 class WIoU_Scale:''' monotonous: {None: origin v1True: monotonic FM v2False: non-m
【阅读笔记】Layer-wise relevance propagation for neural networks with local renormalization layers
Binder, Alexander, et al. “Layer-wise relevance propagation for neural networks with local renormalization layers.” International Conference on Artificial Neural Networks. Springer, Cham, 2016. 本文是探究

商越荣获二等奖,WISE 2020杭州湾创新大赛采购数字化引关注
2020年,采购数字化作为产业互联网的重要一脉备受社会关注,人工智能、RPA、数字技术作为行业“关键词”,推动着新一轮行业变革。 6月23日,由“创新杭州湾”、36氪和西湖天使会联合举办的「WISE杭州湾创新大赛」决赛在湾区数字公园举行。大赛聚焦于产业互联网赛道,包含大数据、人工智能、工业互联网、5G、新材料等领域,来自全国的创业者、企业家和投资人们齐聚一堂,共同见证最终奖项的归属。 经过40
优化改进YOLOv5算法之Dilation-wise Residual(DWR)可扩张残差注意力模块,增强多尺度感受野特征,助力小目标检测
目录 1 Dilation-wise Residual模块原理 1.1 设计动机 1.2 Dilation-wise Residual模块 1.2.1 Design idea and structure 1.2.2 Parameter design

GRN: Generative Rerank Network for Context-wise Recommendation
总结 generator: GRU,policy gradient优化,self reward + differential reward,从粗排到精排 evaluator: bi-lstm+self-attention,交叉熵损失,对final list做rank 细节 generator 把gru当作一个policy,reward有2部分:self reward + different

知识蒸馏:channel wise知识蒸馏CWD
论文:https://arxiv.org/pdf/2011.13256.pdf 1. 摘要 知识蒸馏用于训练紧凑型(轻量)模型被证明是一种简单、高效的方法, 轻量的学生网络通过教师网络的知识迁移来实现监督学习。大部分的KD方法都是通过algin学生网络和教师网络的归一化的feature map, 最小化feature map上的激活值的差异。与以往的方法不同,本文提出了将每个通道的特征图归

36氪WISE风向大会:无论顺风还是逆风,把握风向你就是强者
互联网飞速发展,从追赶风口便能赚的盆丰钵满,到资本红利渐行渐远,直到资本寒冬的今天,能够准确的再次找准行业风向,显然是各行各业迫切需要的答案。 互联网,重塑了各行各业的商业逻辑,在新的产业生态中不断创新,云计算、大数据、物联网、人工智能等新兴技术,成为各企业在布局生态的重中之重,同时也成为各行业寻找下一个蓝海的关键所在。众所周知,企业要生存与发展,市场、技术、竞争力是其核心要素。那么究竟该如何找

Kyligence 荣登 36 氪「2019 WISE 新商业企业榜单」
7 月 9 日,在 36 氪主办的「2019 WISE 超级进化者大会」上,Kyligence 凭借自身快速发展及其在全球市场上的影响力,荣登36氪 “WISE 2019 新商业开创者 100 榜” 榜单。 36 氪 「2019 WISE 超级进化者大会」旨在聚焦新商业进化过程中的破局者们,而 “开创者 100 榜单” 是指企业估值在 5 亿人民币以上,业务极具创新性,近期主营业务快速增长的
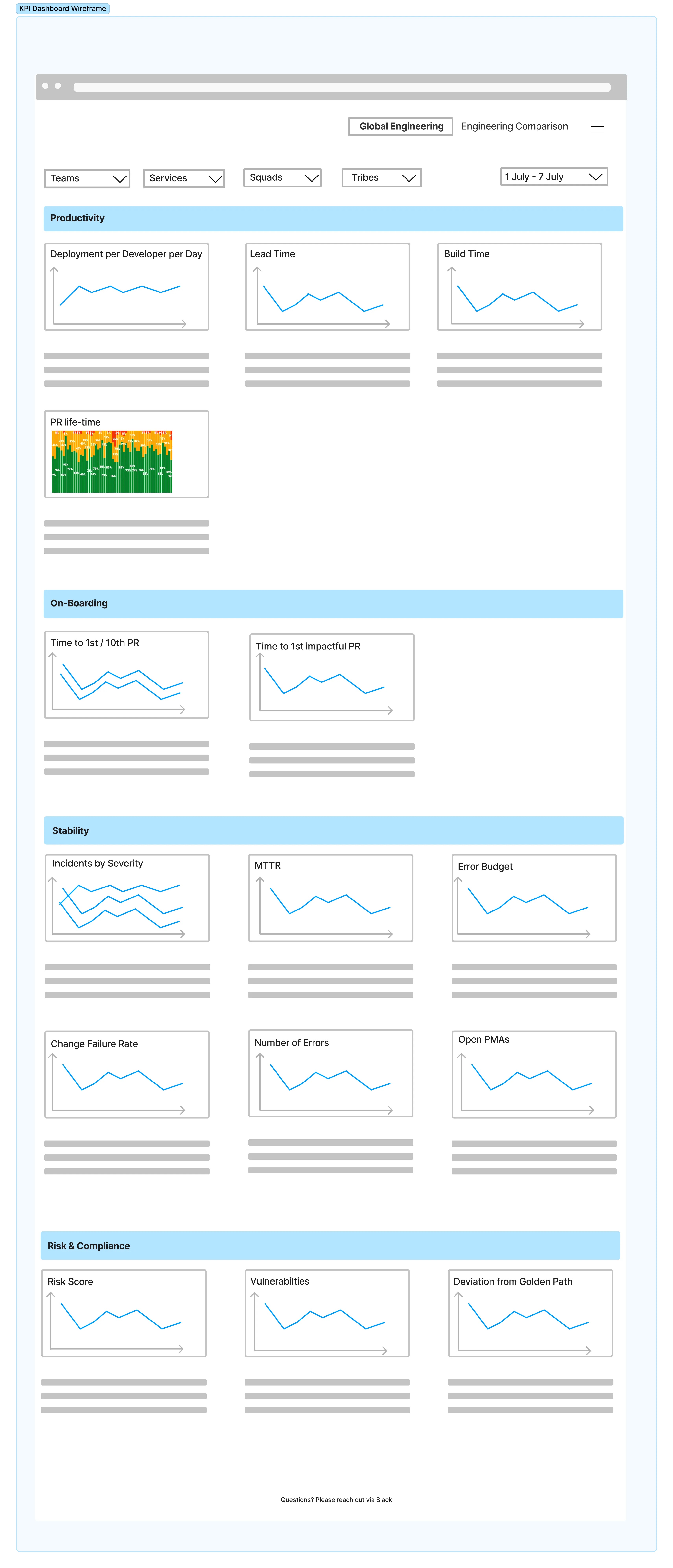
Wise 的平台工程 KPI 探索之旅
平台即产品(PaaP)已经成为软件企业构建内部平台的一种流行方式。在众多软件公司争夺市场份额的同时,还有另一种更为微妙的竞争正在兴起,例如怎样让软件工程师以最快的速度发布新功能?是否拥有最有效的内部平台? 在这篇文章中,我将分享 Wise 的平台工程团队构建 KPI 树的方法。从产品开发过程开始,是如何塑造平台愿景,从而产生一组可操作的 KPI,以及如何使用这些 KPI 来识别平台最大的问题

【BBuf的CUDA笔记】一,解析OneFlow Element-Wise 算子实现
0x0. 前言 由于CUDA水平太菜,所以一直没写过这方面的笔记。现在日常的工作中已经不能离开写CUDA代码,所以准备学习ZZK随缘做一做CUDA的笔记记录一下学习到的知识和技巧。这篇文章记录的是阅读OneFlow的Element-Wise系列CUDA算子实现方案学习到的技巧,希望可以帮助到一起入门CUDA的小伙伴们。Elemet-Wise算子指的是针对输入Tensor进行逐元素操作,比如ReL

Layer-Wise Data-Free CNN Compression
Layer-Wise Data-Free CNN Compression 我们的无数据网络压缩方法从一个训练好的网络开始,创建一个具有相同体系结构的压缩网络。这种方法在概念上类似于知识蒸馏[23],即使用预先训练好的“教师”网络来训练“学生”网络。但是知识蒸馏需要训练数据。以前的方法都是通过生成数据来解决这个问题,比如Adversarial Knowledge Distillation(AKD)