extraction专题
![[论文解读]Genre Separation Network with Adversarial Training for Cross-genre Relation Extraction](https://i-blog.csdnimg.cn/blog_migrate/a81ef8f36f1400d5367d93036bc14ef7.png)
[论文解读]Genre Separation Network with Adversarial Training for Cross-genre Relation Extraction
论文地址:https://www.aclweb.org/anthology/D18-1125.pdf发表会议:EMNLP2019 本论文的主要任务是跨领域的关系抽取,具体来说,利用某个领域的数据训练好的关系抽取模型,很难去直接抽取另一个领域中的关系,比如我们拿某个领域训练好的模型,把另一个领域的数据直接输入整个模型,很难抽取出来正确的实体关系。这主要是因为源领域和目标领域特征表达的不同,在源

构建LangChain应用程序的示例代码:24、使用OpenAI工具进行文本提取教程(Extraction with OpenAI Tools)
使用OpenAI工具进行文本提取教程 执行提取任务从未如此简单!OpenAI的工具调用功能是完美的选择,因为它允许从文本中提取多种不同类型的元素。 使用支持工具的模型 1106版本之后的模型使用工具,并支持“并行函数调用”,这使得任务变得非常容易。 from typing import List, Optionalfrom langchain.chains.openai_tools imp
Dynamic Extraction of Subdialogues for Dialogue Emotion Recognition
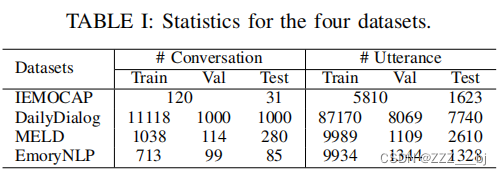
对话情感识别的子对话动态提取 摘要1. 介绍2 相关工作2.1 对话上下文建模2.2 常识知识 3 方法3.1 问题定义3.2 模型概述3.3 特征提取模块3.4 依赖性建模3.5 交互式子对话提取模块3.6 重要性增强的多头自注意力模块3.7 子对话框主题提取模块3.8. 分类模块 四、实验4.1 数据集4.1 实验细节4.2 基线4.3. 结果与分析 摘要 对话中的情绪识别
特征提取(Feature Extraction)应用场景笔记(二)
让我们以一个交通管理系统为例,说明如何基于统计特征、频域特征和时域特征设计数据表示。 假设我们有大量的交通流量数据,包括车辆的速度、密度、道路拥堵情况等指标。我们的任务是让强化学习代理学习交通流量模式,并根据数据做出智能的交通信号灯控制决策,以优化交通流畅度。 基于统计特征: 对于交通流量数据,我们可以从统计角度出发提取特征。例如,我们可以统计每个路段的平均车
2013_CVPR_BoF meets HOG Feature Extraction based on Histograms of Oriented p.d.f Gradients for Imag
最近看到一篇较新的基于BOF的改进的特征提取算法,来自cvpr'2013,从大的方面来讲,这篇paper的算法改进主要包括以下几个方面: 1.BOF算法采用把特征映射到word上达到降维的目的,然后统计图像的word直方图,这篇文献采用计算特征的pdf(概率密度函数)的方法获得特征的表达,其中计算pdf采用KDE(核密度估计)的算法。一幅图像用一个pdf来表示。 2.求pdf的梯度:对p
[译]sklearn.feature_extraction.text.TfidfVectorizer
class TfidfVectorizer 官方文档 class sklearn.feature_extraction.text.TfidfVectorizer(input=’content’, encoding=’utf-8’, decode_error=’strict’, strip_accents=None, lowercase=True, preprocessor=None, token
【NLP文章阅读】Zero-Shot Information Extraction via Chatting with ChatGPT
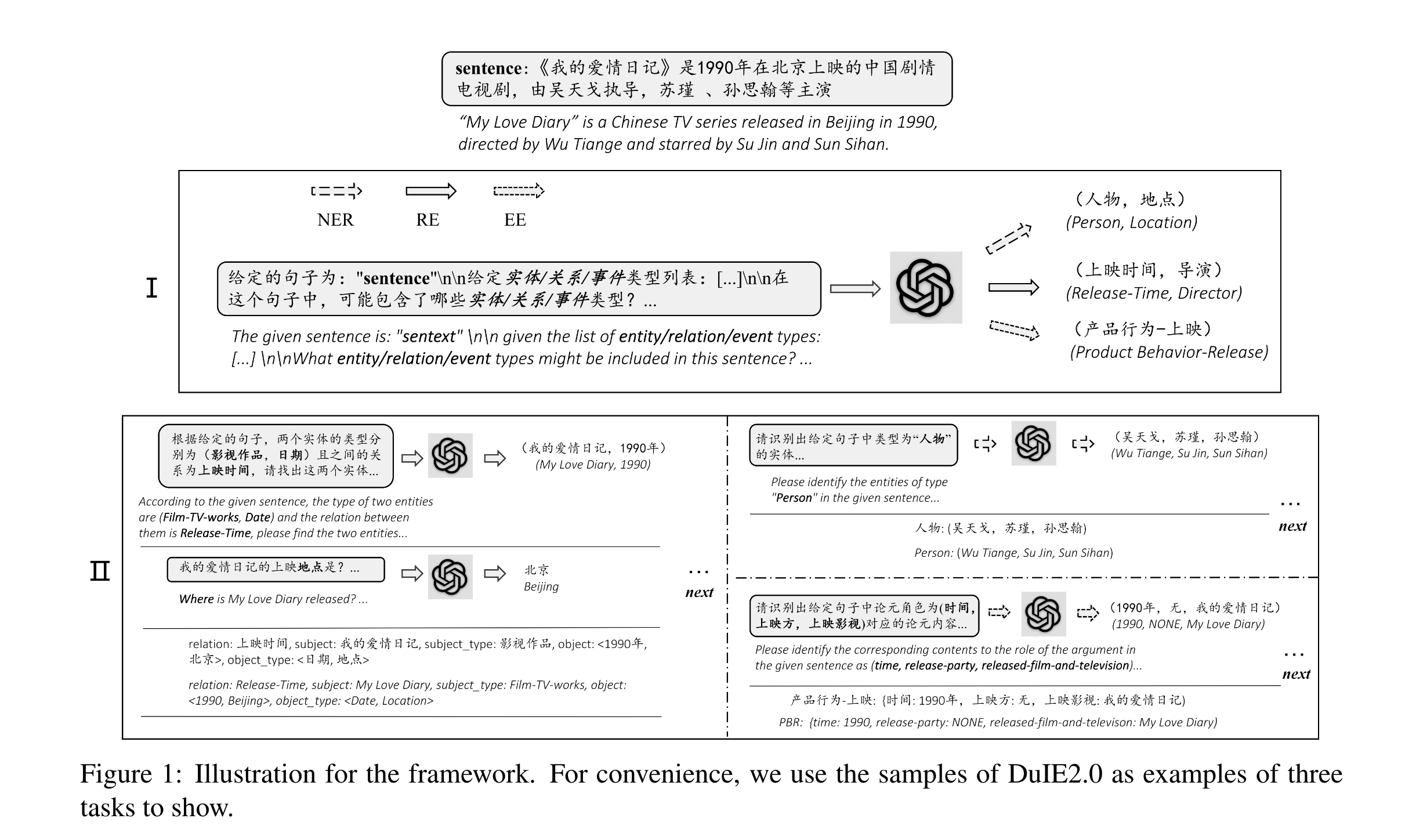
【NLP文章阅读】Zero-Shot Information Extraction via Chatting with ChatGPT 1 模型创新2 前期调研2.1 难以解决的问题 3 Method3.1 方法3.2 数据集3.2.1 RE3.2.2 NER3.2.3 EE 3.3 评价指标3.3.1 RE3.3.2 NER3.3.3 EE 4 效果 转载和使用规则:更多论文解读
![[论文笔记] Dual-Channel Span for Aspect Sentiment Triplet Extraction](https://img-blog.csdnimg.cn/img_convert/b9f1b3a80a11baf04f6d2162abd203c8.png)
[论文笔记] Dual-Channel Span for Aspect Sentiment Triplet Extraction
一种利用句法依赖和词性相关性信息来过滤噪声(无关跨度)的基于span方法。 会议EMNLP 2023作者Pan Li, Ping Li, Kai Zhang团队Southwest Petroleum University论文地址https://aclanthology.org/2023.emnlp-main.17/代码地址https://github.com/bert-ply/Dual_S

科研训练第六周:关于《Learn from Syntax: Improving Pair-wise Aspect and Opinion Terms Extraction with Ric》的复现——
时间确实比较紧张,进度稍微有点停滞,课设结束啦,我得赶一下科研的进度~~ 服务器的内存不够用是我没想到的,大概是有别人也在跑叭 数据处理感觉还是得本地跑一下然后save,云端报错如下: 看回答说是request请求太多被拒绝了🙄 ————————————10.18———————————————————— 本周的计划: 完成数据预处理阶段的事情(大概是一直到词向量生成阶段叭)data

《Large Language Models for Generative Information Extraction: A Survey》阅读笔录
论文地址:Large Language Models for Generative Information Extraction: A Survey 前言 映像中,比较早地使用“大模型“”进行信息抽取的一篇论文是2022年发表的《Unified Structure Generation for Universal Information Extraction》,也是我们常说的UIE模型,

【ChatIE】论文解读:Zero-Shot Information Extraction via Chatting with ChatGPT
文章目录 介绍ChatIEEntity-Relation Triple Extration (RE)Named Entity Recognition (NER)Event Extraction (EE) 实验结果结论 论文:Zero-Shot Information Extraction via Chatting with ChatGPT 作者:Xiang Wei, Xingy

12.Coupling Global and Local Context for Unsupervised Aspect Extraction阅读笔记
Coupling Global and Local Context for Unsupervised Aspect Extraction 19EMNLP CUHK :香港中文大学 3.1 Input and Output 在接触细节以揭示本文的模型如何工作之前,首先描述本文的输入和输出。 输入 给定一个有|C|个句子的数据集C,{X1,X2,……,X|c|}。将每一个句子X表示成
Bit Extraction and Bootstrapping for BGV/BFV
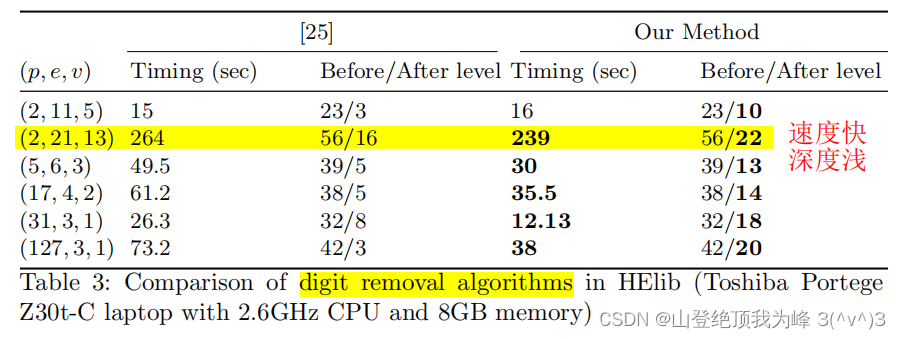
参考文献: [GHS12] Gentry C, Halevi S, Smart N P. Better bootstrapping in fully homomorphic encryption[C]//International Workshop on Public Key Cryptography. Berlin, Heidelberg: Springer Berlin Heidelberg

与分类器无关的显着图提取:Classifier-agnostic saliency map extraction
我的笔记 摘要 当前用于提取显着性图的方法可识别输入的某些部分,这些部分对于特定的固定分类器而言最为重要。我们表明,这种对给定分类器的强烈依赖会阻碍其性能。为了解决这个问题,我们提出了与分类器无关的显着性图提取,该方法可以找到任何分类器都可以使用的图像的所有部分,而不仅仅是预先指定的部分。我们观察到,所提出的方法比以前的工作提取了更高质量的显着性图,同时在概念上简单且易于实现。
Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy
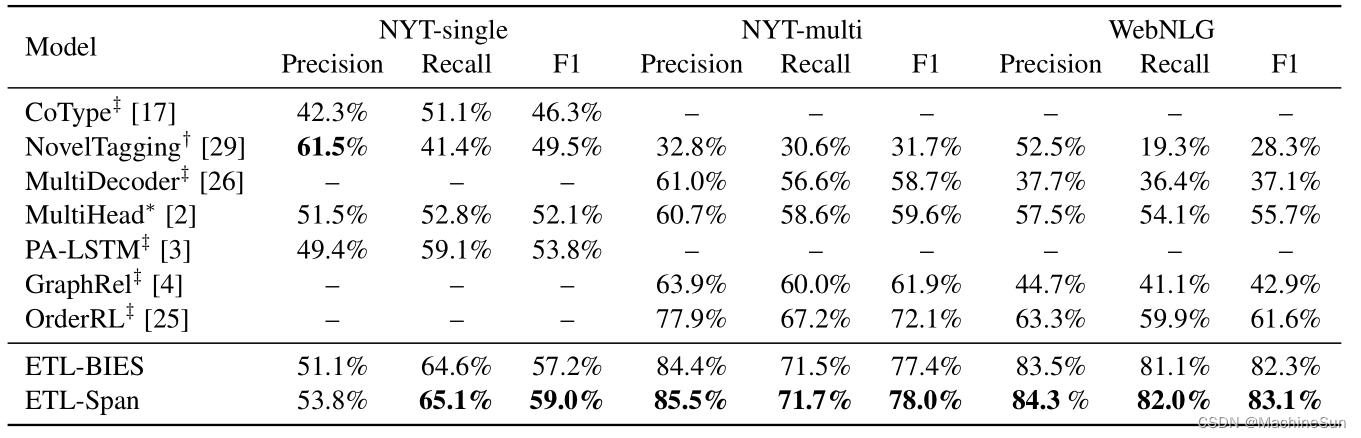
Abstract 本文将关系抽取任务转换为两个任务,HE抽取(头实体抽取)和TER抽取(尾实体和关系) 前一个子任务是区分所有可能涉及到object关系的头实体,后一个任务是识别每个提取的头实体对应的尾实体和关系,然后基于本文提出的基于span的标记方法将两个子任务进一步分解为多个序列标记任务,采用分层边界标记HBT和多跨度解码算法解决这些问题。本文的第一步不是提取所有实体,而是识别可能参与

图像特征提取feature extraction
特征提取是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域。 特征的定义 至今为止特征没有万能和精确的定义。特征的精确定义往往由问题或者应用类型决定。特征是一个数字图像中“有趣”的部分,它是许多计算机图像分析算法的起点。因此
信息抽取(Information Extraction:NER(命名实体识别),关系抽取)
信息/数据抽取是指从非结构化或半结构化文档中提取结构化信息的技术。信息抽取有两部分:命名实体识别(目标是识别和分类真实世界里的知名实体)和关系提取(目标是提取实体之间的语义关系)。概率模型/分类器可以帮助实现这些任务。 信息抽取的定义为:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术 信息抽取是从文本数据中抽取特定信息的一种技术。文本数据是由

Extraction(ET)
Extraction(ET)应用构建平台是一个前沿的集成化的Web应用软件开发平台和运行支撑平台,ET平台涵盖软件的设计,开发,测试,运行,维护,更新和发布等整个生命周期;> ET是极具创新的前沿软件产品,ET彻底改变传统的软件开发模式,以完全图形化的方式,通过组件拼装的模式实现软件系统;基于ET的软件开发,无需应用编程语言,无需进行架构设计,完全图形化构建;> ET的定位> ET平台是典
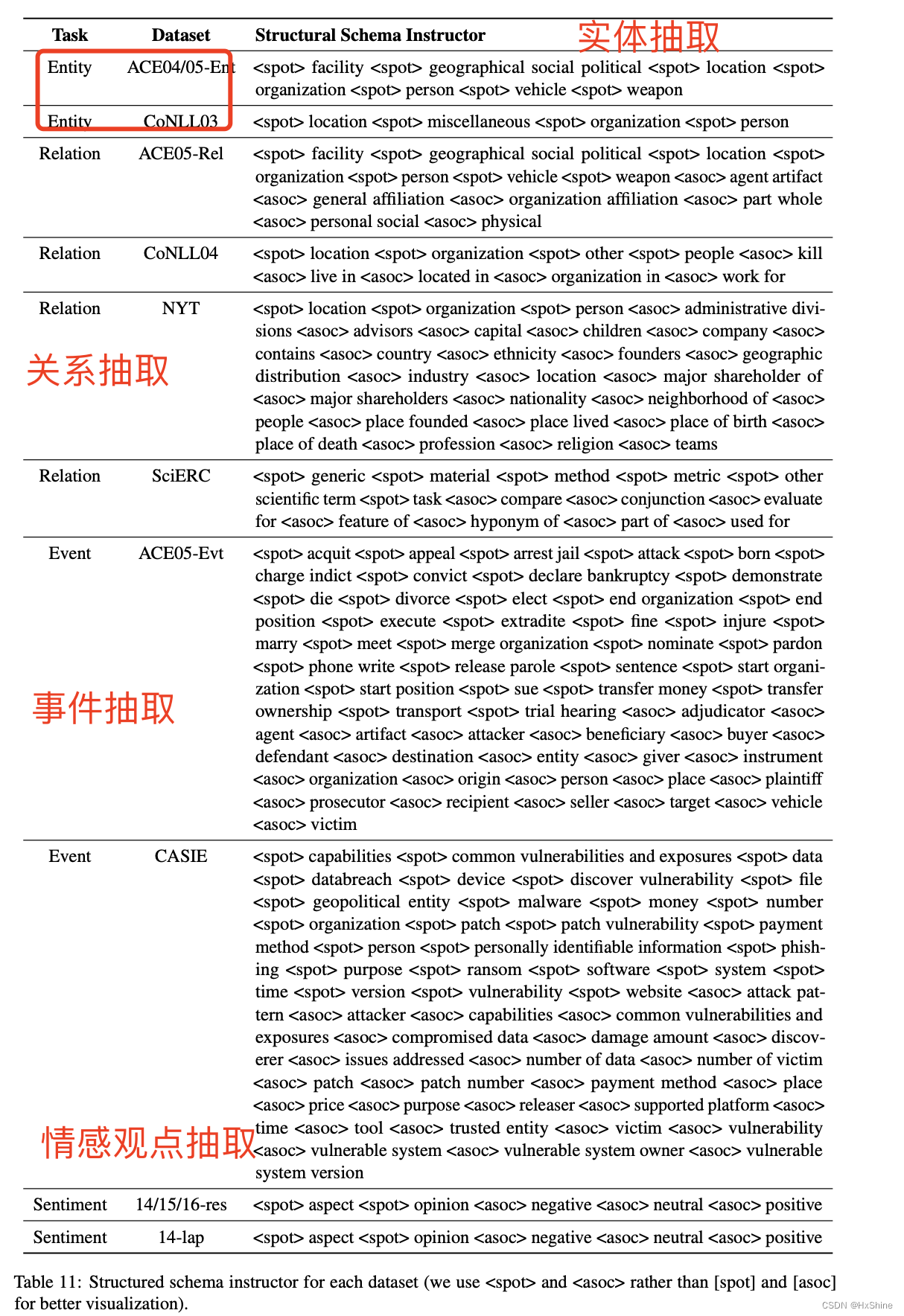
百度UIE:Unified Structure Generation for Universal Information Extraction paper详细解读和相关资料
Prompt learning系列之信息抽取模型UIE:https://mp.weixin.qq.com/s/0lNUlUF_x95mED5B9iBpGg作者解读:https://www.bilibili.com/video/BV19g411Z7rZ/?spm_id_from=autoNextbilibili解读:https://www.bilibili.com/video/BV1LW4y1U7c

LangChain的函数,工具和代理(四):使用 OpenAI 函数进行标记(Tagging) 提取(Extraction)
在上一篇博客LangChain中轻松实现OpenAI函数调用 中我们学习了如何使用Pydantic来生成openai的函数描述对象,并且通过在langchain中调用Pydantic生成的函数描述变量来轻松实现openai的函数调用功能,在此基础上今天我们再介绍两个非常实用的功能:标记(Tagging)和提取(Extraction)。 一、标记(Tagging) 所谓“标记(Tagging

附录C:Standard Parasitic Extraction Format(SPEF)
文章目录 C.1 基础(Basics)C.2 格式(Format)C.3 完整语法知乎翻译圣经 本附录将介绍标准寄生参数提取格式( S P E F SPEF SPEF),它是 I E E E S t d 1481 IEEE\ Std\ 1481 IEEE Std 1481标准的一部分。 C.1 基础(Basics) S P E F SPEF SPEF允许以 A S
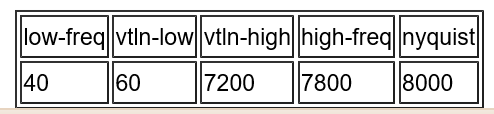
Feature extraction (kaldi 翻译+个人理解)
kaldi原文地址:http://www.kaldi-asr.org/doc/feat.html Introduction: 我们的特征抽取和读波形的代码旨在创建标准的MFCC和PLP特征,在程序中已经设置好合理的默认值并且还留下了可选择项使用户可以适度调整,比如mel bins的数目,频率截断值得最大值和最小值。这个代码值读包含pcm数据的wav文件。这些文件普遍都有wav和pcm的后缀(尽

论文笔记 ACL 2020|Cross-media Structured Common Space for Multimedia Event Extraction
文章目录 1 简介1.1 动机1.2 创新 2 背景知识3 方法3.1 文本事件抽取3.2 图像事件抽取3.3 跨媒体联合训练3.4 跨媒体联合推断 4 实验5 总结 1 简介 论文题目:Cross-media Structured Common Space for Multimedia Event Extraction 论文来源:ACL 2020 论文链接:https://a

Graph based feature extraction and hybrid classification approach for facial expression recognition
基于图的特征提取和混合分类方法的面部表情识别 Author G. G. Lakshmi Priya e-mail:lakshmipriya.gg@vit.ac.in L. B. Krithika e-mail:krithika.lb@vit.ac.in School of Information Technology and Engineering, Vellore Institute of

Fusion-Extraction Networkfor Multimodal Sentiment Analysis(CCF C类)
本篇文章发表在2020年的Pacific-Asia conference on knowledge discovery and data mining会议,是关于图像和文本情感分类。使用的数据集是来自twitter的MVSA-Single和MVSA-Multiple。本文所提出方法的实验效果达到了当时的SOTA。 目录 一、文章动机 二、本篇文章的贡献 三、本文所提出的模型
必读!信息抽取(Information Extraction)【事件抽取】
来源: AINLPer 微信公众号(每日更新…) 编辑: ShuYini 校稿: ShuYini 时间: 2020-08-12 本文参考文献批量下载:关注 AINLPer 回复 EE001 引言 信息抽取(information extraction),简称IE,即从自然语言文本中,抽取出特定的事件或事实信息,帮助我们将海量内容自动分类、提取和重构。这些信息通常包括实体(entity