本文主要是介绍LangChain的函数,工具和代理(四):使用 OpenAI 函数进行标记(Tagging) 提取(Extraction),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在上一篇博客LangChain中轻松实现OpenAI函数调用 中我们学习了如何使用Pydantic来生成openai的函数描述对象,并且通过在langchain中调用Pydantic生成的函数描述变量来轻松实现openai的函数调用功能,在此基础上今天我们再介绍两个非常实用的功能:标记(Tagging)和提取(Extraction)。
一、标记(Tagging)
所谓“标记(Tagging)”是指有时候我们希望llm能够对用户提交的文本信息做出某些方面的评估,比如情感评估(positive, negative, neutral),语言评估(chinese,english,japanese等),并给出一个结构化的输出结果(如json格式)。

接下来在“抠腚”😀之前,先让我们做一些初始化的工作,如设置opai的api_key,这里我们需要说明一下,在我们项目的文件夹里会存放一个 .env的配置文件,我们将api_key放置在该文件中,我们在程序中会使用dotenv包来读取api_key,这样可以避免将api_key直接暴露在程序中:
#pip install -U python-dotenvimport os
import openaifrom dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']要实现“Tagging”功能,我们需要定义一个Pydantic类,然后让langchain将其转换成openai的函数描述变量,如何还不熟悉Pydantic的同学可以看一下我先前写的LangChain中轻松实现OpenAI函数调用这篇博客。
from typing import List,Optional
from pydantic import BaseModel, Field
from langchain.utils.openai_functions import convert_pydantic_to_openai_function
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI#定义pydantic类用以生成openai的函数描述变量
class Tagging(BaseModel):"""Tag the piece of text with particular info."""sentiment: str = Field(description="sentiment of text, should be `pos`, `neg`, or `neutral`")language: str = Field(description="language of text (should be ISO 639-1 code)")这里我们定义了一个“Tagging”它继承自pydantic的BaseModel类,因此Tagging类也具备了严格的数据类型校验功能,Tagging类包含了2给成员变量:sentiment和language,其中sentiment用来判断用户信息的情感包括pos(正面),neg(负面),neutral(中立),language用来判断用户使用的是哪国的语言,并且要符合ISO 639-1 编码规范。
接下来我们要将Tagging类转换成一个openai能识别的函数描述对象:
tagging_functions = [convert_pydantic_to_openai_function(Tagging)]
tagging_functions
有了函数描述变量,接下来我们需要使用熟悉的langchian的LCEL语法来创建一个chain,不过在这之前我们需要创建prompt, model,然后绑定函数描述变量最后创建chain并调用chain:
#根据模板创建prompt
prompt = ChatPromptTemplate.from_messages([("system", "Think carefully, and then tag the text as instructed"),("user", "{input}")
])#创建llm
model = ChatOpenAI(temperature=0)
#绑定函数描述变量,指定函数名(意味着强制调用)
model_with_functions = model.bind(functions=tagging_functions,function_call={"name": "Tagging"}
)
#创建chain
tagging_chain = prompt | model_with_functions
#调用chain
tagging_chain.invoke({"input": "I love shanghai"})
这里我们看到对于用户信息:“I love shanghai”,llm返回的结果中sentiment为pos, language为en, 下面我们用中文信息测试一下:
tagging_chain.invoke({"input": "这家饭店的菜真难吃"})
同样这里我们也看到llm给出了正确的判断。不过这里llm给出的AIMessage格式的结果,要从中提取出我们需要的内容看上去有点麻烦,不过我们可以利用langchain的LCEL语法,在创建chain的时候附加一个json的输出解析器就可以解决这个问题:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParsertagging_chain = prompt | model_with_functions | JsonOutputFunctionsParser()
tagging_chain.invoke({"input": "这家饭店的菜真难吃"}) 
二、提取(Extraction)
“提取(Extraction)”与“标记(Tagging)”有点类似,只不过提取不是对用户信息的评估,而是从中抽取出指定的信息。
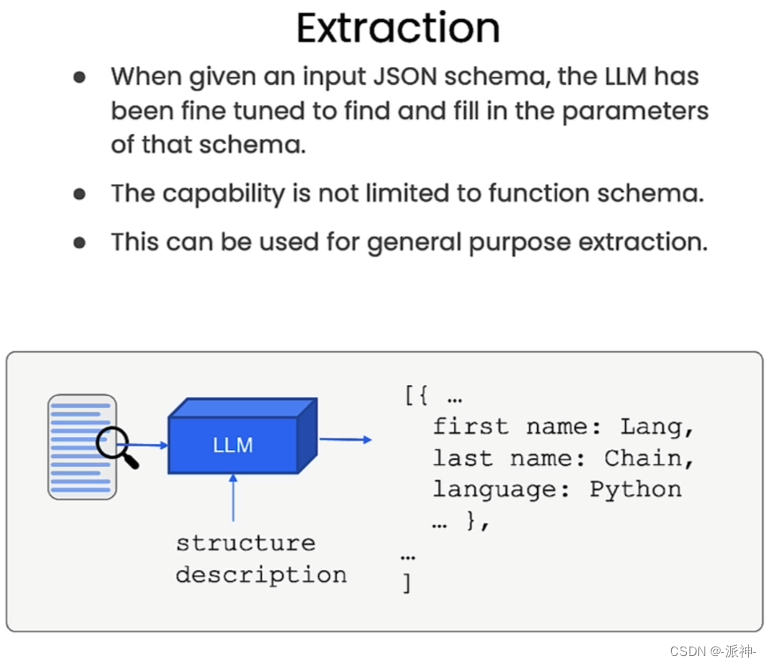
要实现“Extraction”功能,我们任然需要定义一个Pydantic类,然后让langchain将其转换成openai的函数描述变量:
class Person(BaseModel):"""Information about a person."""name: str = Field(description="person's name")age: Optional[int] = Field(description="person's age")class Information(BaseModel):"""Information to extract."""people: List[Person] = Field(description="List of info about people")这里我们定义了Person和Information两个类,其中person类包含了2个成员,name和age,其中age是可选的(Optional)即age不是必须的。Information类包含了一个people成员,它一个person的集合(List)。后面我们要利用这个Information类来提取用户信息中的个人信息:姓名,年龄。
下面我们要将Information类转换成一个openai能识别的函数描述对象:
convert_pydantic_to_openai_function(Information)
接下来我们来创建一个函数描述对象,并将其绑定在llm上,然后调用llm时输入文本:“小明今年15岁,他的妈妈是张丽丽”,我们看看llm会返回什么样的结果:
#创建函数描述变量
extraction_functions = [convert_pydantic_to_openai_function(Information)]#绑定函数描述变量
extraction_model = model.bind(functions=extraction_functions, function_call={"name": "Information"})#llm调用
extraction_model.invoke("小明今年15岁,他的妈妈是张丽丽")
这里从llm的返回信息中我们看到llm提取了 小明和他的年龄,以及 张丽丽和她的年龄,这里有个问题是用户的信息是:“小明今年15岁,他的妈妈是张丽丽”,此信息中并没有包含张丽丽的年龄,但是llm返回的信息中张丽丽的年龄是0岁,这明显是有问题的,如果信息中没有包含年龄,那就不应该提取,因为在定义Person类时age是可选的,那我们如何来解决这个问题呢?
要解决这个问题,我们需要创建一个prompt和chain,并在prompt中提醒llm不要提取不存在的信息:
prompt = ChatPromptTemplate.from_messages([("system", "Extract the relevant information, if not explicitly provided do not guess. Extract partial info"),("human", "{input}")
])#创建函数描述变量
extraction_functions = [convert_pydantic_to_openai_function(Information)]#绑定函数描述变量
extraction_model = model.bind(functions=extraction_functions, function_call={"name": "Information"})
#创建chain
extraction_chain = prompt | extraction_model
#调用chain
extraction_chain.invoke({"input": "小明今年15岁,他的妈妈是张丽丽"})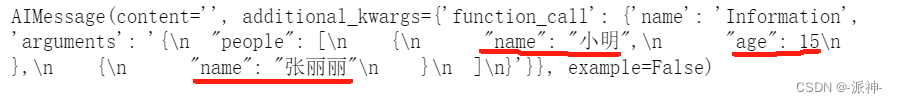
这里我们看到当我们在prompt中提醒llm: "if not explicitly provided do not guess. Extract partial info",意思是在没有明确提供的信息的情况下,不要猜测,抽取部分信息即可,这样做有效的避免了llm产生“幻觉”而给出错误的答案。下面我们再创建一个json的键值解析器,这样可以更方便的从llm的返回信息中过滤出我们需要的内容:
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser#创建chain
extraction_chain = prompt | extraction_model | JsonKeyOutputFunctionsParser(key_name="people")#调用chain
extraction_chain.invoke({"input": "小明今年15岁,他的妈妈是张丽丽"})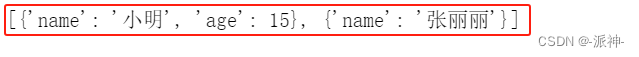
这里需要说明的是先前我们在做Tagging的时候使用了一个JsonOutputFunctionsParser输出解析器,该解析器能从llm返回的AIMessage中提取其中的arguments的内容,而这里我们使用的是JsonKeyOutputFunctionsParser输出解析器,它可以从arguments中根据key来提取内容,这里我们设置了key为“people”即提取arguments中key为“people”的内容。
三、真实场景的应用
在某些真实的应用场景中我们可能需要对某些长文本如论文,博客,新闻等内容进行总结,并提取其中的一些关键词,现在我们就可以用过langchain的Tagging和Extraction功能来实现这样的功能需求,下面我们要对凤凰网上的一篇科技文章:对话阿里云CTO周靖人:开源是唯一出路,通义千问和ChatGPT互有胜负_凤凰网 来实现打标签(tagging)的功能,我们要让llm对这篇文章内容进行总结,并识别文章用的语言,以及从文章中提取关键词,不过首先我们需要创建一个网页加载器以便从网页上拉取文章内容:

from langchain.document_loaders import WebBaseLoader#创建loader,获取网页数据
loader = WebBaseLoader("https://tech.ifeng.com/c/8VEctgVlwbk")
documents = loader.load()#查看网页内容
doc = documents[0]
page_content = doc.page_content[:3000]
print(page_content)
下面我们定义一个Pydantic类“Overview”,它包含了三个成员:summary,language,keywords,其中summary表示对文章内容的总结,language表示文章所使用的语言,keyword表示文章中的关键词:
class Overview(BaseModel):"""Overview of a section of text."""summary: str = Field(description="Provide a concise summary of the content.")language: str = Field(description="Provide the language that the content is written in.")keywords: str = Field(description="Provide keywords related to the content.")接下来我们需要创建函数描述变量,并将其和llm绑定在一起,然后再使用langchain的LCEL语法将prompt,llm,输出解析器组合在一起生成一个chain, 最后我们再调用这个chain:
#创建openai函数描述变量
overview_tagging_function = [convert_pydantic_to_openai_function(Overview)
]
#创建llm
tagging_model = model.bind(functions=overview_tagging_function,function_call={"name":"Overview"}
)
#创建prompt
prompt = ChatPromptTemplate.from_messages([("system", "Extract the relevant information, if not explicitly provided do not guess. Extract partial info"),("human", "{input}")
])
#创建chain
tagging_chain = prompt | tagging_model | JsonOutputFunctionsParser()
#调用chain
tagging_chain.invoke({"input": page_content})
从上面的结果中我们看到llm轻松的完成了我们给它布置的任务,完美的对文章内容进行的总结,并且还给出了language和keywords。
接下来我们来实现提取(Extraction)功能, 我们要提取文章中的标题和作者,不过首先我们需要创建两个Pydantic类News,Info,这两个类用来创建函数描述变量:
class News(BaseModel):"""Information about news mentioned."""title: strauthor: Optional[str]class Info(BaseModel):"""Information to extract"""news: List[News]接下来我们重复之前创建tagging_chain 的步骤来创建一个extraction_chain:
#创建函数描述变量
news_extraction_function = [convert_pydantic_to_openai_function(Info)
]#创建llm
model = ChatOpenAI(temperature=0)
#绑定函数描述变量
extraction_model = model.bind(functions=news_extraction_function, function_call={"name":"Info"}
)
#创建chain
extraction_chain = prompt | extraction_model | JsonKeyOutputFunctionsParser(key_name="news")
#调用chain
extraction_chain.invoke({"input": page_content}) ![]()
这里我们使用了JsonKeyOutputFunctionsParser解析器,因此我们可以从llm的返回消息中根据key来提取内容。
接下来我们再深入介绍一个实用的例子,我们需要从一篇论文:LLM Powered Autonomous Agents | Lil'Log ,如下图所示:

我们要从这篇论文中提取title,和author,这里要说明的是之前我们提取的是当前文章的title,和author, 而这里我们要提取不是这篇论文的title和author,而是要提取这篇论文中提及的其他论文的title和author。下面我们首先加载这篇在线论文:
#加载论文
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
documents = loader.load()
doc = documents[0]
page_content = doc.page_content[:10000]
page_content

这里由于这篇论文内容太长,这里我们只截取了前10000个字符(page_content[:10000]),下面我们要创建两个Pydantic类:Paper和Info。然后我们再创建一个函数描述变量并将它与llm进行绑定:
#创建paper类
class Paper(BaseModel):"""Information about papers mentioned."""title: strauthor: Optional[str]#创建Info类
class Info(BaseModel):"""Information to extract"""papers: List[Paper]#创建函数描述变量
paper_extraction_function = [convert_pydantic_to_openai_function(Info)
]
#将函数描述变量绑定llm
extraction_model = model.bind(functions=paper_extraction_function, function_call={"name":"Info"}
)
因为这回我们需要从该篇论文中提取所有的title和author,那么我们要将要求明确的告知LLM,所以我们需要创建prompt模板,并在这个模板中我们告知llm我们的要求是什么,然后从该模板来创建一个prompt:
template = """A article will be passed to you. Extract from it all papers that are mentioned by this article. Do not extract the name of the article itself. If no papers are mentioned that's fine - you don't need to extract any! Just return an empty list.Do not make up or guess ANY extra information. Only extract what exactly is in the text."""prompt = ChatPromptTemplate.from_messages([("system", template),("human", "{input}")
])这里我们将prompt模板的内容翻译成中文,这样便于大家理解其意思:

最后我们使用langchain的LCEL语法将prompt,llm,输出解析器组合在一起生成一个chain, 最后我们再调用这个chain:
extraction_chain = prompt | extraction_model | JsonKeyOutputFunctionsParser(key_name="papers")extraction_chain.invoke({"input": page_content})
这里我们发现LLM返回了部分我们所需要的title和author,只不过由于我只从这篇论文中截取了前10000个字符,导致LLM返回的结果并不完整,之所以只截取了论文前10000个字符是因为openai的模型对输入的上下文长度有一定的限制,如果超过限制将会导致异常,为了解决这个问题,我们可以考虑使用langchain的文本分割技术将长文本分割成多个文档块,然后逐一将文档块喂给LLM,这样就不会因为上下文长度超过限制而产生异常。下面我们就利用langchain的文档分割组件RecursiveCharacterTextSplitter来创建一个文档分割器,并在此基础上创建一RunnableLambda,它的作用是将分割器分割好的文档存储在一个list中以备后续是使用:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema.runnable import RunnableLambdatext_splitter = RecursiveCharacterTextSplitter(chunk_overlap=0)prep = RunnableLambda(lambda x: [{"input": doc} for doc in text_splitter.split_text(x)]
)response = prep.invoke(doc.page_content)
response
这里我们看到论文被分割成了多个文档块,下面我们统计一下文档块的数量:
len(response)![]()
这里我们看到该篇论文被分割成了14个文档块,接下来我们还需要定义一个矩阵的展开函数,该函数用于最终对输出结果的整理:
#定义矩阵展开函数
def flatten(matrix):flat_list = []for row in matrix:flat_list += rowreturn flat_list#测试展开函数
flatten([[1, 2], [3, 4]])
这里的flatten函数的作用是将多行的矩阵展开为一个只有1行数据的矩阵,最后我们使用langchain的LCEL语法将prep,extraction_chain,flatten组合在一起生成一个新的chain, 最后我们再调用这个chain,需要注意的是这里在创建chain时使用的是前面的extraction_chain,而不是的先前例子中的model:
#创建chain
chain = prep | extraction_chain.map() | flatten#调用chain
chain.invoke(doc.page_content)
这里我们看到llm返回了论文中所有的title,和author, 但是这里需要说明一下的是在创建chain时我们使用的“prep | extraction_chain.map() | flatten”,这里的prep和之前在创建chain时使用的prompt有所不同,之前的prompt只包含一个文档的信息,而这里的prep是一个list它包含了多个文档信息(14个文档块),而prep后面的 extraction_chain.map()作用是将prep中的每个文档单独映射到extraction_chain中,最后使用flatten将输出结果进行展开,如果不使用flatten那么在输出结果中会存在多个list,且每个list中都包含了对应的文档块中的所有title和author,这会让结果看 上去比较混乱。
四、总结
今天我们学习了通过langchain和openai的函数调用来实现标记(Tagging)和提取(Extraction)功能,通过taggin我们可以让llm对用户信息进行评估,通过extration我们可以让llm从用户信息中提取有用的内容,最后我们介绍了两个真实的应用场景案例,我们介绍了如何使用langchain的长文本切割工具对长文本进行切割,从而解决了openai的llm对输入的上下文长度限制问题。希望今天的内容对大家有所帮助。
这篇关于LangChain的函数,工具和代理(四):使用 OpenAI 函数进行标记(Tagging) 提取(Extraction)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









