本文主要是介绍12.Coupling Global and Local Context for Unsupervised Aspect Extraction阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Coupling Global and Local Context for Unsupervised Aspect Extraction
19EMNLP
CUHK :香港中文大学
3.1 Input and Output
在接触细节以揭示本文的模型如何工作之前,首先描述本文的输入和输出。
输入
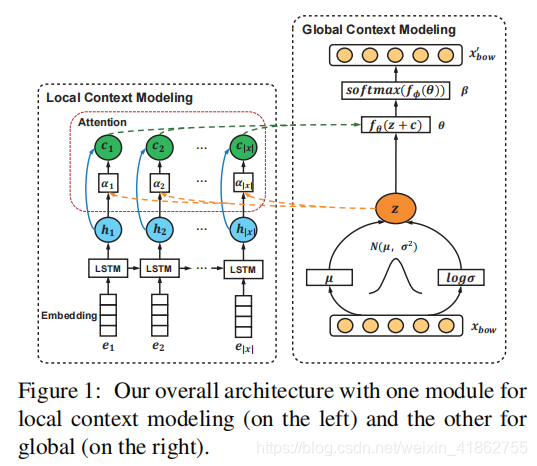
给定一个有|C|个句子的数据集C,{X1,X2,……,X|c|}。将每一个句子X表示成两种形式,词序列形式Xseq和词袋形式Xbow。将Xseq输入局部上下文模型,习得单词如何与其邻居共同出现。而将Xbow作为全局上下文模型的输入,捕获句子级的单词共现规律。
输出
本文的目标是输出属性词的分布簇。然后根据Qiu et al.(2011)的实践,从每个聚类(按似然排序)中选取前N个名词(N作为超参数)作为提取的属性词,因为大多数方面都是名词。
3.2 Local Context Modeling
正如上面提到的,局部上下文模块将词序Xseq作为其输入。在LCM模型中,首先对每个单词wn∈Xseq进行嵌入层处理,将其转换为嵌入向量en。然后采用长短时记忆(网络(Hochreiter and Schmidhuber, 1997)来探索局部上下文。单词嵌入e1, e2,…, e|x|通过循环探索左邻居的单词共现处理到隐藏状态。具体来说,对于单词wn,其隐含状态hn为:

3.2 Global Context Modeling
我们的全局上下文建模模块受到了以前使用LDA-fashion贝叶斯图形模型发现属性词的实践的启发(Lin和He, 2009)。我们假设在给定的语料c中嵌入了K个潜在属性因子。每个因子φk (K = 1,2,…(K)在词汇V上用分布词聚类表示。
同样受到神经主题模型(Miao et al., 2017)的启发,我们采用了带有编码器和解码器的可变自动编码器(VAE) ,以类似于主题模型样式的数据生成过程。在这样做的过程中,我们使潜在属性,即在全局和局部上下文中捕获单词共现,能够在神经结构中学习。主要涉及两个步骤:首先,将输入语句x (BoW形式xbow)编码为全局表示z,以z为条件,加上局部表示hn,解码器进一步生成xbow’,。在本节的其余部分中,我们首先介绍编码器如何从全局上下文学习全局表示z。然后,我们将介绍如何将全局表示和局部表示耦合在一起进行数据生成。
Global Representation Encoding
编码器被用于从xbow去学习全局表示z.假设全局条件下的词满足高斯分布,以平均µ和标准差σ为优先。其估算公式定义为:

Coupling Global and Local Context
从局部上下文模型中,我们得到了隐状态hn(n = 1,2,……,|x|),接下来描述如何将hn与全局表示z耦合。
具体来说,我们对局部表示中的隐藏状态hn采用注意机制(Bahdanau et al., 2015),该机制在感知全局信息的情况下,旨在识别x中能够有用地表示其属性因素的单词。我们设计了注意权重αn来衡量单词wn和x的全局表示z之间的相似度:

Decoding Process
给定全局表示z和全局范围局部表示c,解码器在两者上进行数据生成过程。对于每个输入句子x,我们假设每个单词wn∈Xbow是根据其属性混合, θ,反映x的属性因子组成的Kdim分布进行采样的。然后用z和c估计θ,传递x单词的全局和局部上下文。描述x生成过程的故事是:

这篇关于12.Coupling Global and Local Context for Unsupervised Aspect Extraction阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









