本文主要是介绍与分类器无关的显着图提取:Classifier-agnostic saliency map extraction,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我的笔记
摘要
当前用于提取显着性图的方法可识别输入的某些部分,这些部分对于特定的固定分类器而言最为重要。我们表明,这种对给定分类器的强烈依赖会阻碍其性能。为了解决这个问题,我们提出了与分类器无关的显着性图提取,该方法可以找到任何分类器都可以使用的图像的所有部分,而不仅仅是预先指定的部分。我们观察到,所提出的方法比以前的工作提取了更高质量的显着性图,同时在概念上简单且易于实现。该方法为ImageNet数据上的定位任务设置了最新的技术成果,尽管在推理时未使用地面真相标签,但其性能优于所有现有的弱监督定位技术。可以在以下位置获得再现结果的代码:https://github.com/kondiz/casme。
1. 介绍
卷积神经网络中,给定分类器的特定类分数的梯度可用于提取图像的显着性图。但是,1)由于特定分类器仅使用可能用于分类的要素子集。2)依赖分类器的显着性图往往很嘈杂,覆盖了许多不相关的像素而丢失了许多相关的像素。作者提出与分类器无关的显着性图提取,我们将其公式化为一种实用算法,从而实现了目标。
2. 相关工作
绝大多数基于神经网络的显着性提取器都与特定的分类器结合在一起 。最常见的方法还假设推理时掌握了标签的知识。这种方法具有一些优势,因为它允许生成基于类的显着性图。但是,如果没有给出真实标签,则必须首先使用分类模型对分类进行预测,这可能是错误的。
与对抗本地网络相同点:同时训练分类器和显着性映射,这在测试时不需要对象的类。
与对抗本地网络不同点:1)分类损失->熵损失,可获得更好的显着性图。2)结合了编码器和分类器的权重,训练过程更快,更好的性能。3)仅适用于原始像素。
3. 与分类器无关的显着性图提取
在本文中,我们解决了提取输入图像的显着区域的问题,以及提取映射的问题。 ![]() ,该映射应使有用的像素为1,否则为0。
,该映射应使有用的像素为1,否则为0。
3.1 依赖分类器的显着性图提取
依赖分类器的显著性图提取可以看成:![]() ,其中
,其中![]() ,S是对应于分类损失的得分函数,R是正则化术语,l是分类损失。
,S是对应于分类损失的得分函数,R是正则化术语,l是分类损失。
此优化过程可以解释为找到映射m最大程度地混淆给定的分类器 f。使用分类器 f 获得的映射 m 可能与使用 f'找到的映射 m'不同,即使两个分类器在原始图像和掩模图像的分类损失方面都同样出色,此属性违反了我们对映射的定义m, 任何有助于分类的像素都应通过带有以下内容的掩模(显着图)来表示。
3.2 与分类器无关显着图提取
为了解决显着性映射对单个分类器的依赖性问题,我们建议更改方程式中的目标函数。1)不仅要考虑单个固定分类器,还要考虑按其后验概率加权的所有可能分类器,![]() 。且
。且![]() (正相关)。解决此优化问题等同于搜索所有可能分类器的空间,然后查找映射m与他们所有人一起工作。当我们参数化F 作为卷积网络(参数表示为 θF),所有可能分类器的空间与其参数的空间是同构的。所提出的方法考虑了所有分类器,我们称其为与分类器无关的显着性图提取。即提取所有有用的像素点(因为每个分类器之运用了其中一部分像素点就能实现很好的分类,我们要找到每个分类器都用到的像素点集合)。
(正相关)。解决此优化问题等同于搜索所有可能分类器的空间,然后查找映射m与他们所有人一起工作。当我们参数化F 作为卷积网络(参数表示为 θF),所有可能分类器的空间与其参数的空间是同构的。所提出的方法考虑了所有分类器,我们称其为与分类器无关的显着性图提取。即提取所有有用的像素点(因为每个分类器之运用了其中一部分像素点就能实现很好的分类,我们要找到每个分类器都用到的像素点集合)。
3.3 算法

输入是:先初始化一个分类器f_0,映射m_0,给定数据集和循环次数K。
输出是:映射m_k。
过程:先将f_0加入到样本集F,再循环K次:1)通过更新分类器f的参数最小化分类损失,获得一个新的更优的分类器。2)将新获得的分类器加到样本集F。3)从样本集取样一个分类器f'。3)通过更新映射m的参数最大化分类损失得分函数,得到新的更优的映射。4)对样本集F进行某一操作,使得F中分类器更少且都是效果更优的。比如F每满一百删掉第一个。
可见,分类器f的参数和映射m的参数是同时进行的。其中4):如果一个4*4的图片,只有中间的4个像素值有用则m的结果是:

上述过程可以用下图理解:
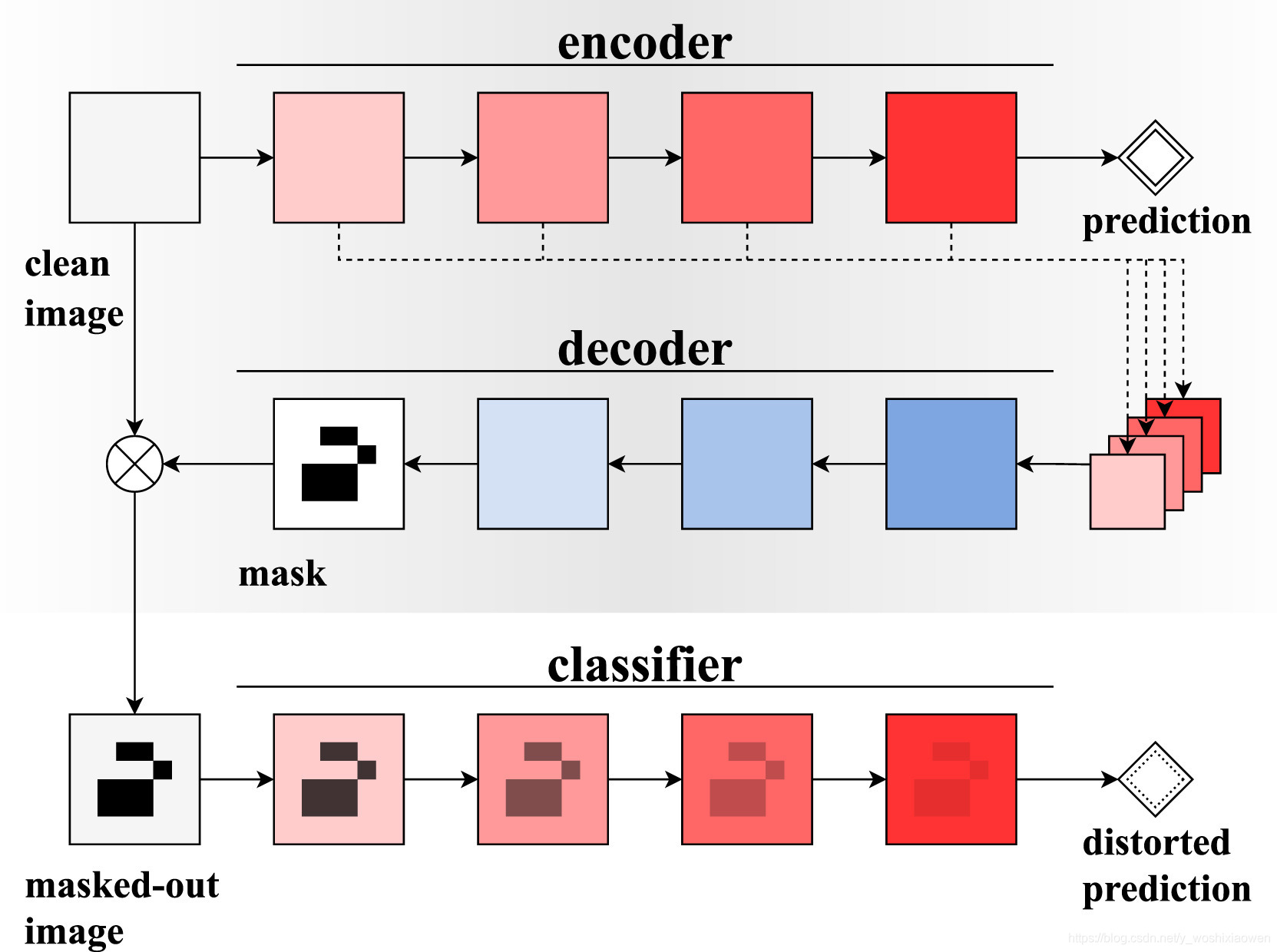
结果:

补充数学知识:
数学期望:
某城市有10万个家庭,没有孩子的家庭有1000个,有一个孩子的家庭有9万个,有两个孩子的家庭有6000个,有3个孩子的家庭有3000个。
则此城市中任一个家庭中孩子的数目是一个随机变量,记为X。它可取值0,1,2,3。
其中,X取0的概率为0.01,取1的概率为0.9,取2的概率为0.06,取3的概率为0.03。
则,它的数学期望,即此城市一个家庭平均有小孩1.11个,当然人不可能用1.11个来算,约等于2个。
后验概率:
假设一个学校里有60%男生和40%女生。女生穿裤子的人数和穿裙子的人数相等,所有男生穿裤子。一个人在远处随机看到了一个穿裤子的学生。那么这个学生是女生的概率是多少?
使用贝叶斯定理,事件A是看到女生,事件B是看到一个穿裤子的学生。我们所要计算的是P(A|B)。
P(A)是忽略其它因素,看到女生的概率,在这里是40%
P(A')是忽略其它因素,看到不是女生(即看到男生)的概率,在这里是60%
P(B|A)是女生穿裤子的概率,在这里是50%
P(B|A')是男生穿裤子的概率,在这里是100%
P(B)是忽略其它因素,学生穿裤子的概率,P(B) = P(B|A)P(A) + P(B|A')P(A'),在这里是0.5×0.4 + 1×0.6 = 0.8.
根据贝叶斯定理,我们计算出后验概率P(A|B)。
* : 元素相乘
@:逐元素乘法
这篇关于与分类器无关的显着图提取:Classifier-agnostic saliency map extraction的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






