classifier专题

Softmax classifier
Softmax classifier原文链接 SVM是两个常见的分类器之一。另一个比较常见的是Softmax分类器,它具有不同的损失函数。如果你听说过二分类的Logistic回归分类器,那么Softmax分类器就是将其推广到多个类。不同于SVM将 f(xi,W) 的输出结果 (为校准,可能难以解释)作为每个分类的评判标准,Softmax分类器给出了一个稍直观的输出(归一化的类概率),并且

特征选择错误:The classifier does not expose coef_ or feature_importances_ attributes
在利用RFE进行特征筛选的时候出现问题,源代码如下: from sklearn.svm import SVRmodel_SVR = SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='auto',kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verb

Spark MLlib模型训练—分类算法 Decision tree classifier
Spark MLlib模型训练—分类算法 Decision tree classifier 决策树(Decision Tree)是一种经典的机器学习算法,广泛应用于分类和回归问题。决策树模型通过一系列的决策节点将数据划分成不同的类别,从而形成一棵树结构。每个节点表示一个特征的分裂,叶子节点代表最终的类别标签。 在大数据场景下,Spark MLlib 提供了对决策树的高效实现,能够处理大规模数据

maven使用install打包时,程序包xxx不存在,pom中添加classifier分类标签解决
1.程序可以正常运行,但是打包时报错如下:** ** 2.解决办法:在引入的工程打包时pom中的打包插件修改如下: <build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-jar-plugin</artifactId><executions><execution><goals><g

Python机器学习分类算法(一)-- 朴素贝叶斯分类(Naive Bayes Classifier)
简要描述 朴素贝叶斯分类器(Naive Bayes Classifier)是一种基于贝叶斯定理与特征条件独立假设的分类方法。它之所以被称为“朴素”,是因为它假设输入特征(在特征向量中)是独立的,即一个特征的出现不依赖于其他特征的出现。这个假设在实际应用中通常不成立,但在很多情况下,朴素贝叶斯分类器仍然可以取得很好的效果。 工作原理 贝叶斯定理: 给定一个类别
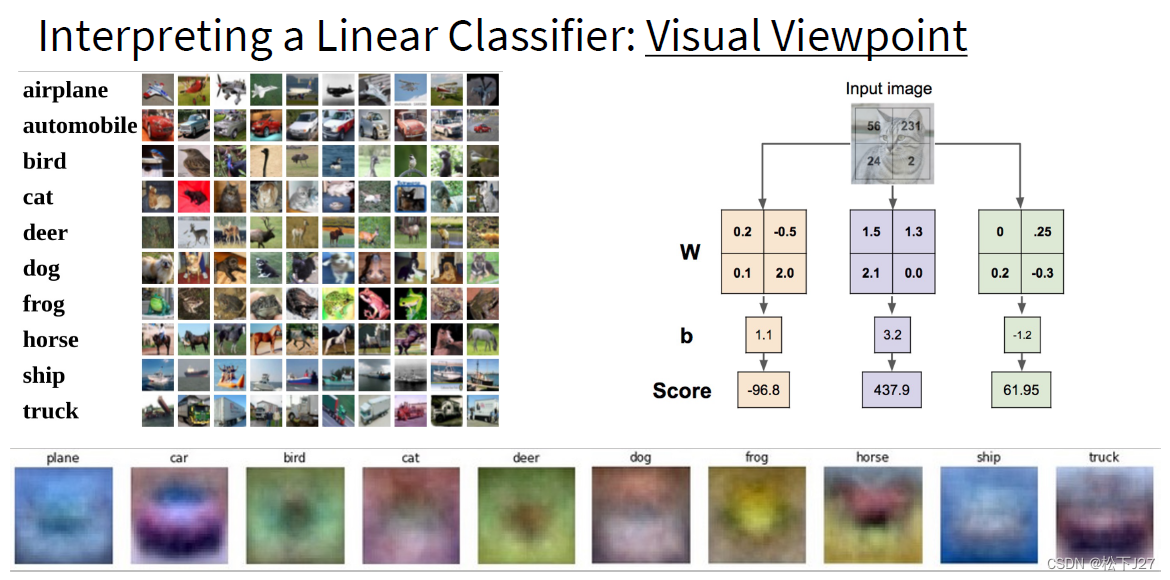
深度学习 --- stanford cs231 编程作业(assignment1,Q3: softmax classifier)
stanford cs231 编程作业(assignment1,Q3: softmax classifier softmax classifier和svm classifier的assignment绝大多部分都是重复的,这里只捡几个重点。 1,softmax_loss_naive函数,尤其是dW部分 1,1 正向传递 第i张图的在所有分类下的得分

扩散模型条件生成——Classifier Guidance和Classifier-free Guidance原理解析
1、前言 从讲扩散模型到现在。我们很少讲过条件生成(Stable DIffusion曾提到过一点),所以本篇内容。我们就来具体讲一下条件生成。这一部分的内容我就不给原论文了,因为那些论文并不只讲了条件生成,还有一些调参什么的。并且推导过程也相对复杂。我们从一个比较简单的角度出发。 参考论文:Understanding Diffusion Models: A Unified Perspectiv

解决maven无法获取${os.detected.classifier}的问题
解决maven无法获取${os.detected.classifier}的问题 mvn package报错信息解决方式 1、windows系统2、Linux系统未验证的问题 mvn package报错信息 Could not transfer artifact io.netty:netty-tcnative-boringssl-static:jar:${os.detecte
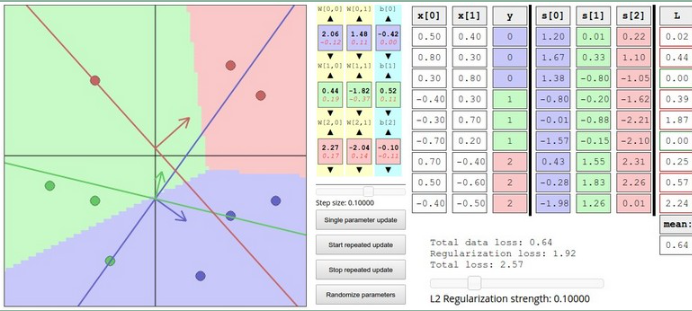
神经网络 part2 :Softmax classifier
转载自皓月如我的CSDN博客,原始链接地址。 http://blog.csdn.net/fm0517/article/details/52051198 *此系列为斯坦福李飞飞团队的系列公开课“cs231n convolutional neural network for visual recognition ”的学习笔记。本文主要是对module 1 的part2 Linear classi
![[Classifier-Guided] Diffusion Models Beat GANs on Image Synthesis](https://img-blog.csdnimg.cn/direct/f1a1051fbfb7497890b2f36e6e3ec2e9.png)
[Classifier-Guided] Diffusion Models Beat GANs on Image Synthesis
1、介绍 针对diffusion models不如GAN的原因进行改进: 1)充分探索网络结构 2)在diversity和fidelity之间进行trade off 2、改进 1)在采样步数更少的情况下,方差设置为固定值并非最优。需要将表示为网络预测的v

【Arthas案例】某应用依赖两个GAV-classifier不同的snakeyaml.jar,引起NoSuchMethodError
多个不同的GAV-classifier依赖冲突,引起NoSuchMethodError Maven依赖的三坐标体系GAV(G-groupId,A-artifactId,V-version) classifier通常用于区分从同一POM构建的具有不同内容的构件物(artifact)。它是可选的,它可以是任意的字符串,附加在版本号之后。 【案例1】某应用依赖两个GAV-classifier

softVoting Classifier
还是加载上一节的数据 #%% soft voting classifiervoting_clf2 = VotingClassifier(estimators=[('log_clf',LogisticRegression()),('svm_clf',SVC(probability=True)),('dt_clf',DecisionTreeClassifier())],voting='soft')
Faster RCNN 推理 从头写 java (四) Classifier 网络预测
1. 图片预处理2. RPN网络预测3. RPN to ROIs4. Classifier 网络预测5. Classifier网络输出对 ROIs过滤与修正6. NMS (非最大值抑制)7. 坐标转换为原始图片维度 一: 输入输出 输入: ROIs: RPN to ROI 后 没32个为一组的ROIs, shape为 [1, 32, 4]feature: RPN 层的输出, 也就是VGG16

《Decoupling Representation and Classifier for Long-Tailed Recognition》阅读笔记
论文标题 《Decoupling Representation and Classifier for Long-Tailed Recognition》 用于长尾识别的解耦表示和分类器 作者 Bingyi Kang、Saining Xie、Marcus Rohrbach、Zhicheng Yan、 Albert Gordo、Jiashi Feng 和 Yannis Kalantidis 来

Mark 一下 detector ------之 Random Fern Classifier
与之前的几个tracker(19-The ALIEN tracker applied to faces 22-Self-paced learning forlong-term tracking 12--Occlusion and motionreasoning for long-term tracking这些在每一帧上作检测)不同,当尺度最大得分Ys<Tr时,我们用Tr激活检测模块,为

与分类器无关的显着图提取:Classifier-agnostic saliency map extraction
我的笔记 摘要 当前用于提取显着性图的方法可识别输入的某些部分,这些部分对于特定的固定分类器而言最为重要。我们表明,这种对给定分类器的强烈依赖会阻碍其性能。为了解决这个问题,我们提出了与分类器无关的显着性图提取,该方法可以找到任何分类器都可以使用的图像的所有部分,而不仅仅是预先指定的部分。我们观察到,所提出的方法比以前的工作提取了更高质量的显着性图,同时在概念上简单且易于实现。
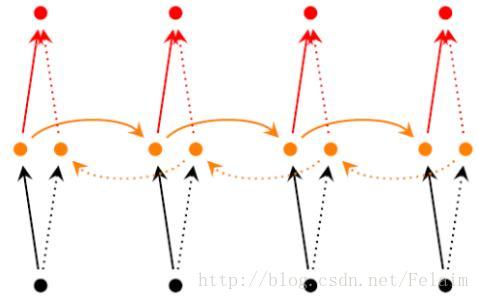
Tensorflow实现基于Bidirectional LSTM Classifier (双向LSTM)
1.双向递归神经网络简介 双向递归神经网络(Bidirectional Recurrent Neural Networks, Bi-RNN),是由Schuster和Paliwal于1997年首次提出的,和LSTM是在同一年被提出的。Bi-RNN的主要目标是增加RNN可利用的信息。RNN无法利用某个历史输入的未来信息,Bi-RNN则正好相反,它可以同时使用时序数据中某个输入的历史及未来数据。
Classifier Guidance 与 Classifier-Free Guidance
Classifier Guidance 与 Classifier-Free Guidance DDPM 终于把 diffusion 模型做 work 了,但无条件的生成在现实中应用场景不多,我们终归还是要可控的图像生成。本文简要介绍两篇关于 diffusion 模型可控生成的工作。其中 Classifier-Free Guidance 的方法还是现在多数条件生成 diffusion 模型的主流思
贝叶斯分类器(Bayesian Classifier)
贝叶斯分类器(Bayesian Classifier)详解 贝叶斯分类器是基于贝叶斯定理的一类统计分类方法。它们在给定数据的条件下,通过计算不同类别的概率来进行分类。 贝叶斯定理 贝叶斯定理是贝叶斯分类器的核心,它提供了在已知某些信息的情况下,预测的一种方式。数学公式如下: P ( A ∣ B ) = P ( B ∣ A ) × P ( A ) P ( B ) P(A|B) = \fra
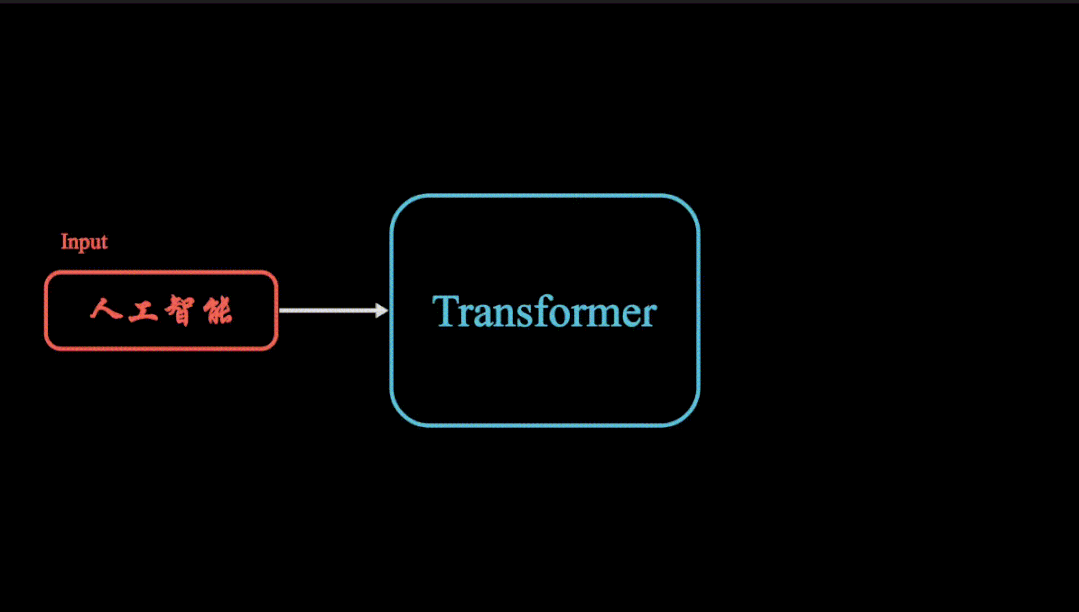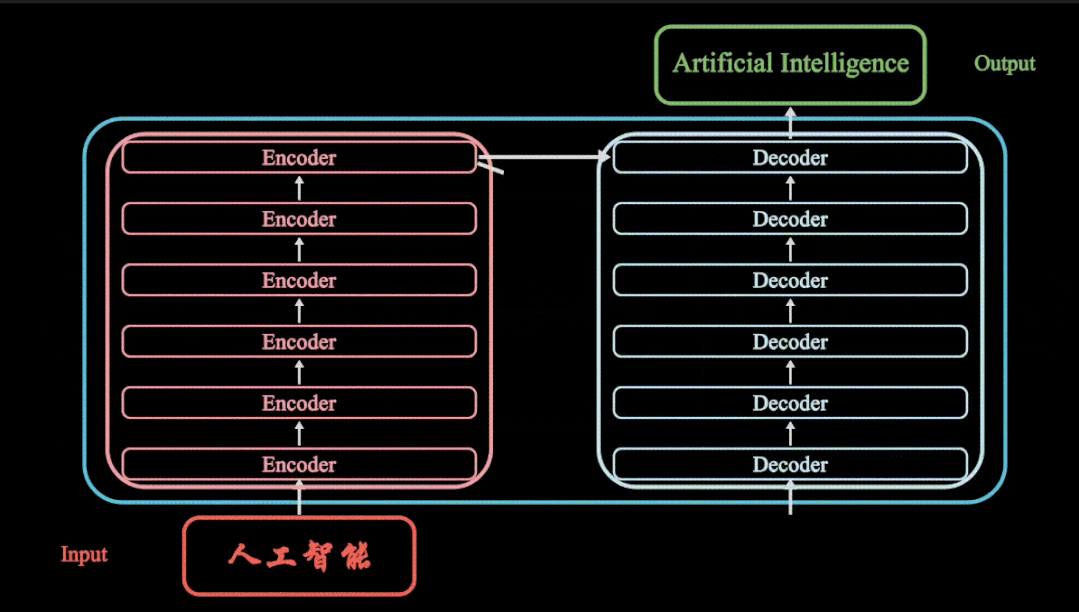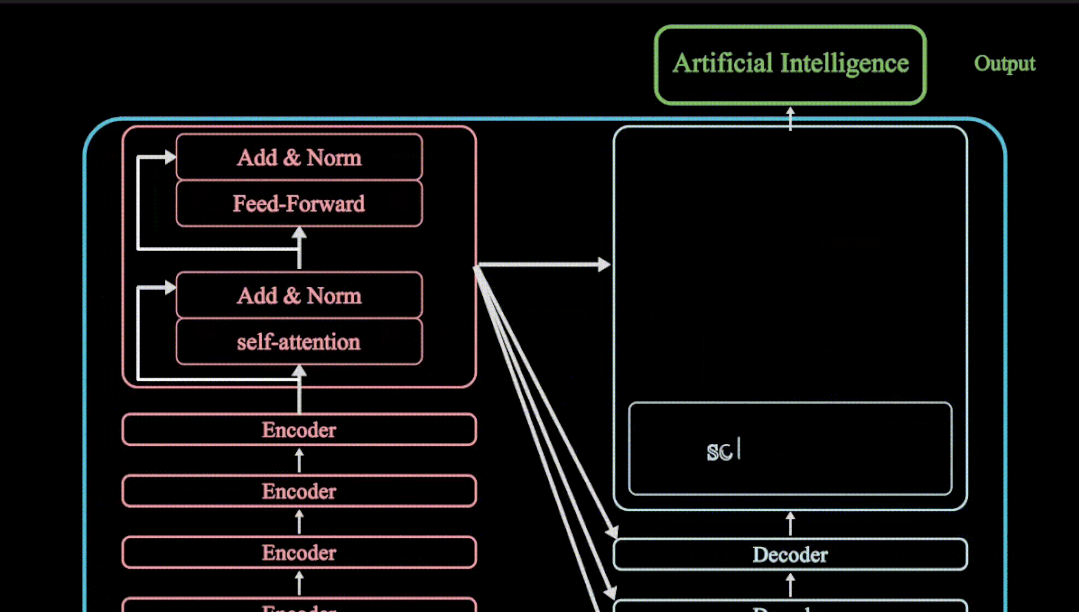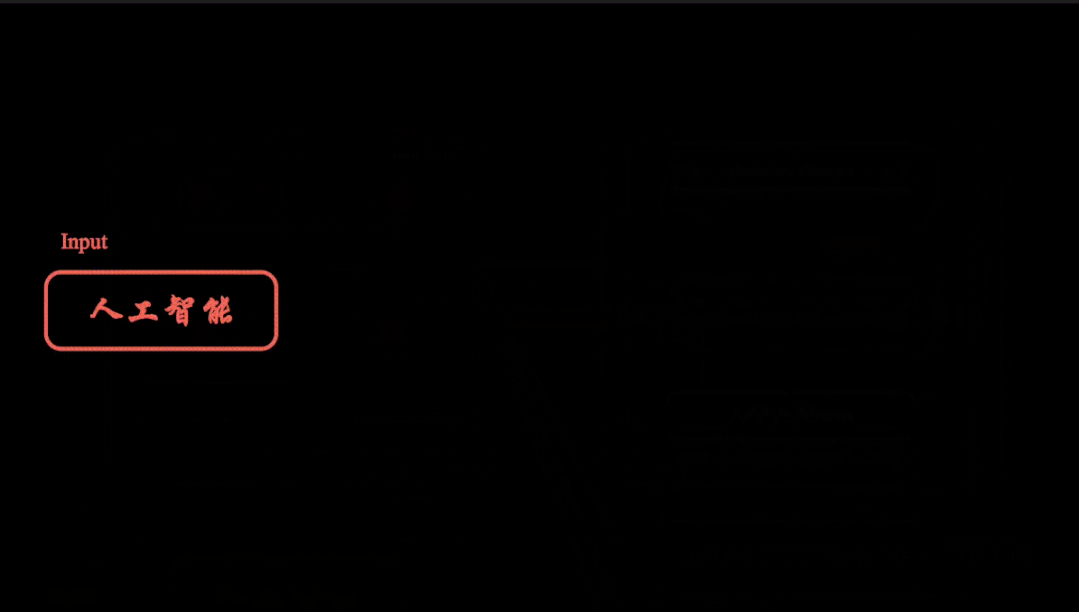
Keras人工智能神经网络 Classifier 分类 神经网络搭建
前期我们分享tensorflow以及pytorch时,分享过tensorflow以及pytorch的分类神经网络的搭建步骤,在哪里我们使用的训练集是mnist,同样Keras分类神经网络的搭建,我们同样使用mnist数据集来进行分类神经网络的搭建(有关mnist数据集,大家可以参考往期文章) 数据预处理 Keras 以及集成MNIST 数据包,再分成训练集和测试集。x 是一张图片,y 是每张图

Deep neural network and extreme gradient boosting based hybrid classifier for improved prediction 梳理
作者:Satyajit Mahapatra等 期刊:IEEE TCBB 时间:2021.05 0 写在前面的疑惑 1 动机 了解生命的行为过程和致病机制,了解蛋白质-蛋白质相互作用至关重要。 2 贡献 1.)本文采用深度神经网络(DNN)和极端梯度boosting分类器(XGB)相结合的混合方法预测PPI。 2)采用ACC+CT+LD的方式 3)实验丰富,既包括种内,又包括种间。

iCaRL Incremental Classifier and Representation Learning 翻译
摘要 在通往人工智能的道路上,一个主要的开放问题是逐步学习系统的开发,该系统可以随着时间的推移从数据流中学习越来越多的概念。 在这项工作中,我们引入了一种新的培训策略,iCaRL,它允许以这样一种类增量的方式学习:只有少量类的培训数据必须同时出现,并且可以逐步添加新的类 iCaRL同时学习强分类器和数据表示。 这与早期的工作不同,早期的工作从根本上局限于固定的数据表示,因此与深度学习架构不兼容

机器学习3:K近邻法K-Nearest-Neighbor Classifier/KNN(基于R languagePython)
k k k 近邻法是一种基本分类与回归问题。 k k k 近邻法的输入为实例的特征向量,对应于特征空间中的点;输出为实例的类别,可以取很多类。 k k k 近邻法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其 k k k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此, k k k 近邻法不具有显式的学习过程。 k k k 近邻法实际上利用训练数据集对特
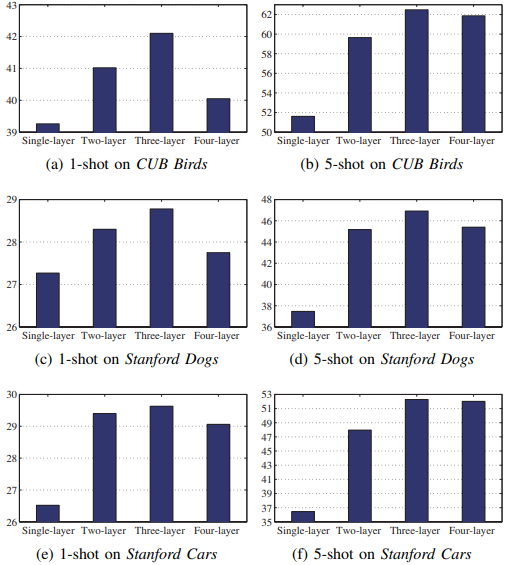
论文笔记:Piecewise classifier mappings: Learning FG learners for novel categories with few examples
Piecewise classifier mappings: Learning fine-grained learners for novel categories with few examples 文章目录 Piecewise classifier mappings: Learning fine-grained learners for novel categories with fe

diffusion model(四)文生图diffusion model(classifier-free guided)
文章目录 系列阅读 文生图diffusion model(classifier-free guided)背景方法大意模型如何融入类别信息(或语义信息)采用交叉注意力机制融入基于channel-wise attention融入 如何训练 ϵ θ ( x t , y , t ) \epsilon_{\theta}(x_t, y,t) ϵθ(xt,y,t)与 ϵ θ ( x t , y = ∅
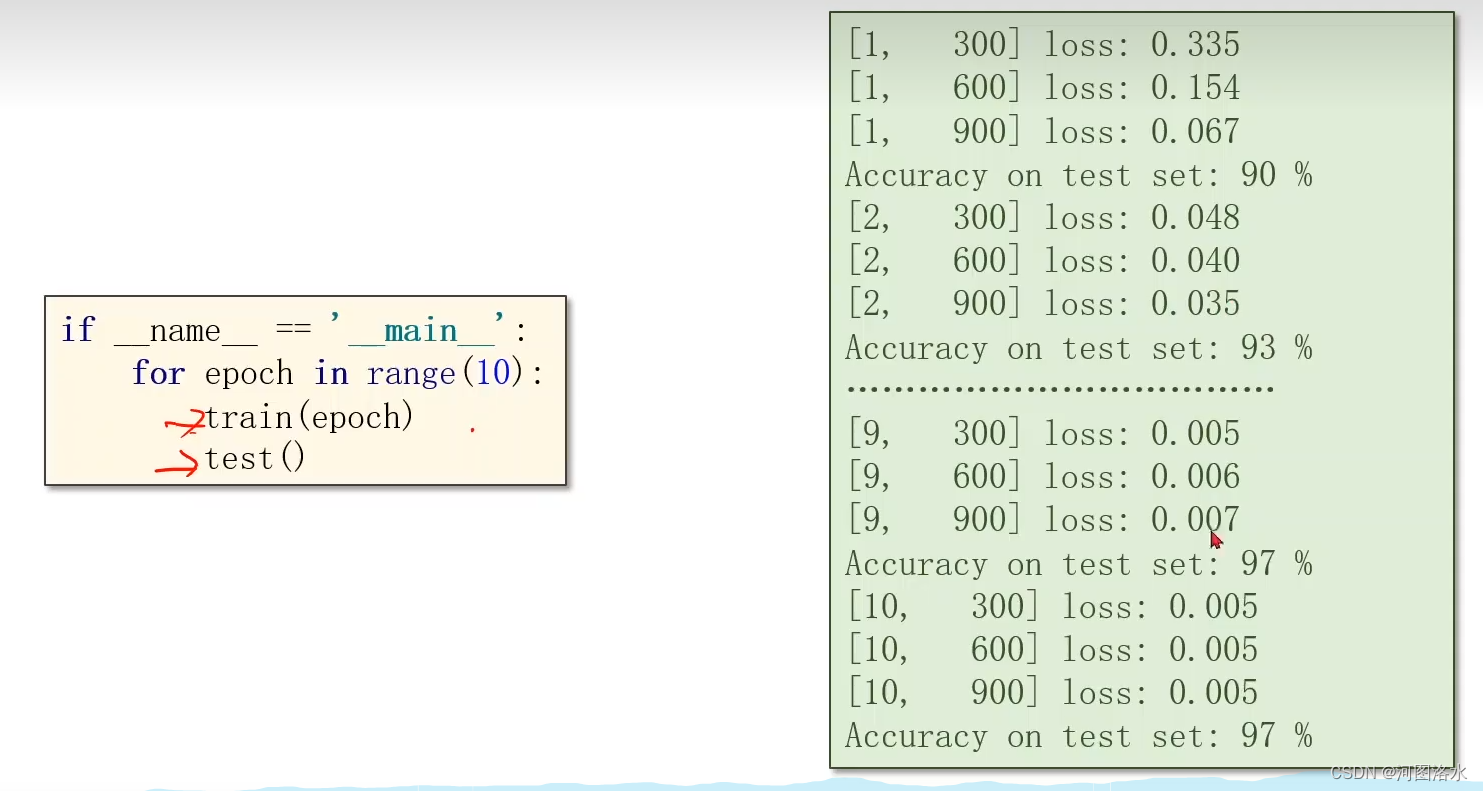
PyTorch 深度学习之多分类问题Softmax Classifier(八)
1. Revision: Diabetes dataset 2. Design 10 outputs using Sigmoid? 2.1 Output a Distribution of prediction with Softmax 2.2 Softmax Layer Example, 2.3 Loss Function-Cross Entropy Cros