本文主要是介绍Tensorflow实现基于Bidirectional LSTM Classifier (双向LSTM),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.双向递归神经网络简介
双向递归神经网络(Bidirectional Recurrent Neural Networks, Bi-RNN),是由Schuster和Paliwal于1997年首次提出的,和LSTM是在同一年被提出的。Bi-RNN的主要目标是增加RNN可利用的信息。RNN无法利用某个历史输入的未来信息,Bi-RNN则正好相反,它可以同时使用时序数据中某个输入的历史及未来数据。
Bi-RNN网络结构的核心是把一个普通的单项的RNN拆成两个方向,一个随时序正向的,一个逆着时序的反向的
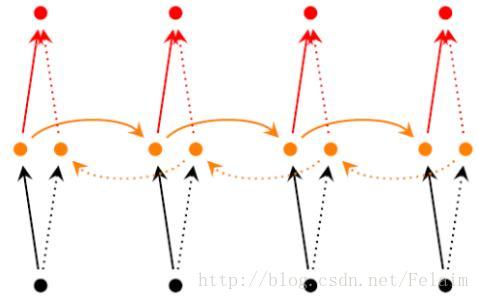
感觉上面的图就很直观了,看箭头就可以很容易的发现有正向的箭头和反向的箭头,也就代表时序的不同。注意一点就是,我们发现正向节点和反向节点是不共用的,作为输出的时候是两个节点输出一个结果。
Bi-RNN中的每个RNN单元既可以是传统的RNN,也可以是LSTM单元或者GRU单元,同样也可以叠加多层Bi-RNN,进一步抽象的提炼出特征。如果最后使用作分类任务,我们可以将Bi-RNN的输出序列连接一个全连接层,或者连接全局平均池化Global Average Pooling,最后再接Softmax层,这部分和使用卷积神经网络部分一致,如果有不理解Softmax这些概念的建议看下cs231n系列的课程,里面的概念还是讲解的非常清晰的。
2.Bidirectional LSTM Classifier的代码实现
#coding:utf-8
#代码主要是使用Bidirectional LSTM Classifier对MNIST数据集上进行测试
#导入常用的数据库,并下载对应的数据集
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("E:/Anaconda/DATA/sp504", one_hot = True)
learning_rate = 0.01
max_samples = 400000
batch_size = 128
display_step = 10
n_steps = 28
n_hidden = 256
n_classes = 10
x = tf.placeholder("float", [None, n_steps, n_input])
y = tf.placeholder("float", [None, n_classes])
biases = tf.Variable(tf.random_normal([n_classes]))
def BiRNN(x, weights, biases):
x = tf.reshape(x, [-1, n_input])
x = tf.split(x, n_steps)
lstm_bw_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden, forget_bias = 1.0)
lstm_bw_cell, x,
dtype = tf.float32)
return tf.matmul(outputs[-1], weights) + biases
pred = BiRNN(x, weights, biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = pred, labels = y))
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
with tf.Session() as sess:
sess.run(init)
step = 1
while step * batch_size < max_samples:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
sess.run(optimizer, feed_dict = {x: batch_x, y: batch_y})
if step % display_step == 0:
acc = sess.run(accuracy, feed_dict = {x: batch_x, y: batch_y})
loss = sess.run(cost, feed_dict = {x: batch_x, y: batch_y})
print("Iter" + str(step * batch_size) + ", Minibatch Loss = " + \
"{:.6f}".format(loss) + ", Training Accuracy = " + \
"{:.5f}".format(acc))
step += 1
print("Optimization Finished!")
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", sess.run(accuracy, feed_dict = {x: test_data, y: test_label}))
这篇关于Tensorflow实现基于Bidirectional LSTM Classifier (双向LSTM)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




