本文主要是介绍Feature extraction (kaldi 翻译+个人理解),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
kaldi原文地址:http://www.kaldi-asr.org/doc/feat.html
Introduction:
我们的特征抽取和读波形的代码旨在创建标准的MFCC和PLP特征,在程序中已经设置好合理的默认值并且还留下了可选择项使用户可以适度调整,比如mel bins的数目,频率截断值得最大值和最小值。这个代码值读包含pcm数据的wav文件。这些文件普遍都有wav和pcm的后缀(尽管有时pcm后缀的文件被应用在sphere files中(不明觉厉))。在这种情况下,这文件就会被转换。如果源数据不是一个wave文件,然后就取决于用户用命令行工具去转换它,但为了掩盖一个普通情况,我们为sph2pipe提供一个安装指导。这个命令行工具compute-mfcc0feats和compute-plp-feats计算这些特征,和其他kaldi工具类似,不带参数运行他们会给出一个选项列表。scripts中的例子展示了这些工具的用法。
computing MFCC features:
通过命令行工具compute-mfcc-feats,我们描述MFCC特征使如何被计算的。这个项目需要两个命令行参数:一个rspecifier(度wav数据,indexed by utterance) ,另一个是wspecifier(用来写特征,indexed by utterance)。
 kaldi把数据写成一个大的archive文件,同时也写一个scp文件方便的随机访问。这个项目不添加delta特征,kaldi也接受一个选项-channel来选择channel(如-channel=0,-channel=1),当读stereo(立体声)数据时会起作用。
kaldi把数据写成一个大的archive文件,同时也写一个scp文件方便的随机访问。这个项目不添加delta特征,kaldi也接受一个选项-channel来选择channel(如-channel=0,-channel=1),当读stereo(立体声)数据时会起作用。
MFCC特征的计算是通过Mfcc类型对象完成的,这是一个Compute()函数来计算来自waveform的特征。
1 得到文件中帧的数目(典型的是25ms帧长10ms的帧移)
2 对于每一帧:
2.1 抽取数据,做可选抖动、预相位和直流偏移消除,用窗函数对其进行相乘(如汉明窗)
2.2 算出这个点的能量(如果用log-energy,而不是C0)
2.2 做FFT变换,计算能量谱。
2.3 计算每一个mel bin的能量,例如,23个三角形重叠箱,其中心在mel频域中等距分布
2.4 计算log能量,并进行cos变换,保持指定的系数(如13)
2.5 有选择地做倒谱抬举,这只是一个系数缩放,确保其在一个合理的范围
频率低的值或者高的值都被截断了,通过选项-low-freq和-high-freq,总被设置为0和奈奎斯特频率,如(对于16kHZ采样的语音来说,-low-fre1=20,-hith-freq=7800 )。
该工具提取的特征与htk提取的特征不同,其大多因为默认的参数不同导致的,设置选项-htk=true并且正确设置参数,从理论上来讲是接近HTK特征的。一个可能重要的选项是我们不支持能量max-normalization。这是因为我们你们更偏向于可以以无状态方式应用的标准化方式。希望保留特征计算,以便原则上可以逐帧进行,并且仍然给出相同的结果。但是命令行compute-mfcc-feats有一个选项是-subtract-mean来减去特征的均值。这会在每帧上都进行,对于每个人有不同的处理方式(如cmvn,意味着谱平均和方差标准化)。
Computing PLP features
在前面阶段,计算PLP和计算MFCC是类似的,感知线性预测(Perceptual linear predictive, PLP).
Feature-level Vocal Tract Length Normalization(VTLN)
特征级声道长度标准化。
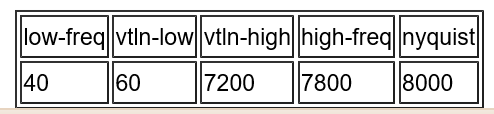
命令行compute-mfcc-feats和compute-plp-feats都接受一个VTLN变形因子选项。在当前scripts中这仅仅被当作是VTLN线性版本的一种初始化线性变换的方法。VTLN的作用是移动三角形频率箱的中心频率位置。在频率空间中,移动频率箱的翘曲函数是一个分段线性函数要理解它,请记住以下数量0 <= low-freq <= vtln-low < vtln-high < high-freq <= nyquist。
我们执行的VTLN翘曲函数是一个分段的函数,一共分为三段映射到[low-freq,high-freq],设该翘曲函数为W(f),其中f就是频率。中心段将f映射为f/scale,其中scale为VTLN的翘曲因子(通常设置在0.8-1.3之间)。X轴的下段与中间段相连的点是f点,使得min(f,W(f))=vtln-low。X轴的下段与中间段相连的点是f点,使得max(f,W(f))=vtln-high.低段和高段的斜坡于偏置由连续性决定,并且满足W(low-freq)=low-freq and W(high-freq)=high-freq,这个变形函数于HTK的不同,在HTK的版本中,“vtln-low”和“vtln-high”量被解释为X轴上不连续发生的点。这就意味着vtln-high变量需要基于已知翘曲因子的范围来认真选择(否则空mel bins这种情况会发生)。
对于16k的语音数据来说,可参考如下设置
这篇关于Feature extraction (kaldi 翻译+个人理解)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






