kaldi专题

kaldi 中run_ivector_common
kaldi 中run_ivector_common.sh 在使用GMM-HMM对音频和文本进行对齐之后,在使用DNN网络的时候,kaldi中会加入说话人信息,一般用ivector特征,kaldi中run_ivector_common.sh 对特征做了进一步的处理: 对特征进行速度上的扰动处理 # perturb the normal data to get the alignment _sp
【kaldi】Kaldi+CUDA安装向问题(含libtool is not installed.的解决方法)
现在汇总一下出现的问题。 (1)Ubuntu 16.04 更新Nvidia驱动后,图形登录界面无限循环 H:目前(请右上看眼发文时间),最新版本的Ubuntu 16.04不兼容Nvidia驱动。14.04或者14.10版本是安全的。这里,提供一个站点:厦门大学的信息与网络中心。里面有很多linux版本。有Deepin/CenOS/ubuntu等。 (2)虚拟机是(几乎)无法调用G
【kaldi】Kaldi tutorial翻译之Prerequisites(前提条件)-kaldi学习前必备梳理
本翻译仅供自己学习使用,不承担任何其他责任。水平有限拒绝转载。欢迎大家指出错误,共同学习。 我们假设本页的读者了解使用HMM-GMM进行语音识别的基础知识。在这里我们需要在线简明介绍的是:M. Gales and S. Young (2007).``The Application of Hidden Markov Models in Speech Recognition."

【kaldi】VMware12+Ubuntu16.04+kaldi安装遇到的问题
日本时间已经2点了,记录一下就要睡觉了,周五有进度报告。晚点来更新。 —————————————————————————————— 说到最前面,首先我觉得任何一个学语音识别的得有个耐X的电脑,没有赶紧换。【就不吐槽导师跟我说计算用サーバ,给我的电脑就用来发发邮件写写文档 VMware 12 Pro + Ubuntu :这个部分下载带安装大概花了1个小时。

手把手教学!新一代 Kaldi: TTS Runtime ASR 实时本地语音识别 语音合成来啦
简介 本文向大家介绍如何在新一代 Kaldi的部署框架 **sherpa-onnx**中使用 TTS。 注:sherpa-onnx 提供的是一个TTS runtime, 即部署环境。它并不支持模型训练。 本文使用的测试模型,都是来源于网上开源的 VITS 预训练模型。 我们提供了 ONNX 导出的支持。如果你也有 VITS 预训练模型,欢迎尝试使用 sherpa-onnx 进行部署。

Kaldi-Timit 训练
Kaldi-Timit 训练 背景 这篇博客主要记录使用Kaldi和Timit数据集训练模型的过程以及遇到的问题及解决方法。 Timit数据介绍 制作方 Timit是几个研究机构联合收集的,文本材料由Massachusetts Institude of Technology(MIT)、Stanford Research Institude(SRI)和Texas Instruments(TI

语音识别之kaldi
最近一直在折腾kaldi,在这个庞大的系统面前,自己是那么的微小。由于数据库的原因,我只能运行kaldi所给例子的一部分。下面就来说说最近的进展吧。 第一个例子就是yesno这个例子。由于提供数据,而且数据比较小,可以非常容易的去实现这个例子。具体的可以见我之前的博客:语音识别工具箱之kaldi介绍。 第二个例子是rm里面的s4。具体的步骤也很简单,首先运行./getdat
如何利用kaldi提自己想要的特征(mfcc plp pitch)
群里的@卡丁王一直想用kaldi提自己想要的特征,但是他老是出现错误。我自己试验下,下面是具体流程,希望你有所收获。 首先,确保你的s5文件夹有conf local step utils文件夹。然后你把你的数据保存为test文件夹,比如test文件夹里有test1.wav test2.wav test3.wav。 然后,新建个data文件夹,data文件夹新建个test文件夹,这个test
kaldi中的数据准备
数据准备 译者:V (shiwei@sz.pku.edu.cn) 水平有限,如有错误请多包涵。 @wbglearn校对。 介绍 在运行完示例脚本后(见Kaldi tutorial),你可能会想用自己的数据在Kaldi上跑一下。本节主要讲述如何准备相关数据。我们假设本页的读者使用的是最新版本的示例脚本(即在脚本目录下被命名为s5的那些,例如egs/rm/s5)。另外,除了阅读本页所述内容
kaldi中的特征提取
本翻译原文http://kaldi.sourceforge.net/feat.html,由@煮八戒翻译,@wbglearn校对和修改。 特征提取 简介 我们做特征提取和波形读取的这部分代码,其目的是为了得到标准的MFCC(译注:梅尔倒谱系数)和PLP(译注:感知线性预测系数)特征,设置合理的默认值但留了一部分用户最有可能想调整的选项(如梅尔滤波器的个数,最小和最大截止频率等等)。这部分
kaldi学习的过程
最近太忙,群里大家讨论的不够积极,而且翻译的事情似乎大家还在进行中……但是总是有新人进入这个kaldi的学习,在这里作为统一的阐述。 首先,说下kaldi。kaldi是一个语音识别平台,里面含有很多语音识别所需要的模型,比如:gmm,sgmm,dnn和hmm。你可以通过自己的数据在这平台上训练得到自己的模型,然后用于识别。你需要做的也就是改些脚本,适合自己的语音库。跟htk这个平台差不多

kaldi中的在线识别----Online Recognizers
本文是kaldi学习联盟中@冒顿翻译的,下面是@冒顿的翻译结果,在这里感谢@冒顿的辛勤劳动,希望更多的人加入到这个翻译上来,为更多的人学习…… 因为我们翻译的文档都有url,csdn不支持我们的直接发表,所以只能用图片,最后的翻译会集成pdf版,后面会公开的。 最后,如果你发现有任何问题,欢迎留言讨论。我会在最快的时间回复大家,希望大家共同学习……

kaldi中深度学习的主要实现---------Karel's DNN training implementation
说明:本文是翻译kaldi主页里的Karel的深度学习模型的实现。 2014.5.3改。 如果您有任何问题,欢迎留言讨论,谢谢……
关于语音识别系统kaldi及qq群的一些想法
自从建议kaldi学习 语音深度学习的qq群以来,群成员在不断的壮大,kaldi语音识别系统是povey大神开源的,我们算是站在巨人的肩膀上进行我们自己的语音识别系统搭建。自从发这么多博客以来,总是很多人加我qq,后来我直接把我qq去掉了。主要原因有如下:第一,我个人的时间有限,我自己需要学习和科研;第二,个人能力有限,我自己再kaldi上做的实验很少;第三,大家的实验平台都不一样,比如:
kaldi主页上的翻译的事情(更新)
2014.8.22 新的翻译任务: Kaldi的第一阶段翻译基本完成,我们大概翻译了kaldi主页的十几篇,现在接下来做第二阶段,内容如下: Kaldi剩余部分的翻译: 1. Lattices in Kaldi http://kaldi.sourceforge.net/lattices.html 2. Kaldi I/O mechanisms htt
kaldi群和kaldi新手群
从2014年2月27日开始建立kaldi学习群(群号:367623211),经过一段时间的努力,今天终于群达到1000人了,后期将逐步清理一些人,腾出一些位置。 此外,如果你是新手,欢迎加入kaldi学习新手群(群号:279295537),这里也许有跟你一样的新手,这样你们遇到的问题也就一样。
Kaldi sherpa-ncnn 端侧语音识别
本文介绍一款基于新一代 Kaldi 的、超级容易安装的、实时语音识别 Python 包:sherpa-ncnn。 小编注: 它有可能是目前为止,最容易 安装的实时语音识 别 Python 包(谁试谁知道)。 它的使用方法也是极简单的。 安装 pip install sherpa-ncnn 对的,就是这一句,所有的依赖都从源码安装。 其实目前 sherpa-ncnn 只有下面 3
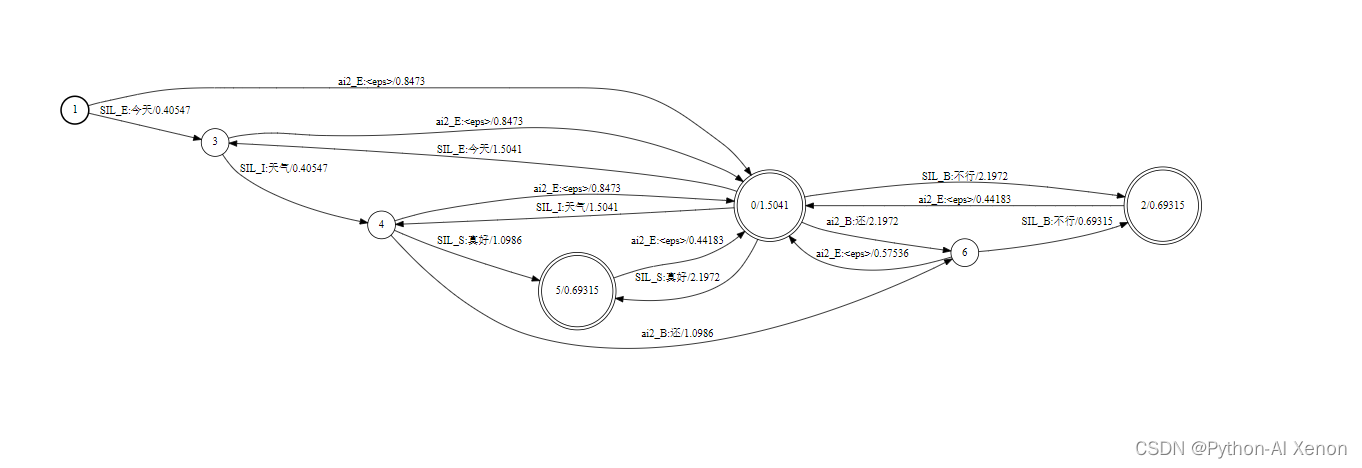
Kaldi语音识别技术(四) ----- 完成G.fst的生成
Kaldi语音识别技术(四) ----- 完成G.fst的生成 文章目录 Kaldi语音识别技术(四) ----- 完成G.fst的生成一、N-Gram 语言模型简介二、环境准备srilm工具的安装 三、文件准备(一) 准备语料1. 使用Python生成语料2. 使用awk 快速生成语料 (二) 语言模型1. 统计词频2. 生成语言模型3. 计算困惑度 四、G.fst的生成及查看1. 使

在树莓派上搭建kaldi离线语音识别系统(交叉编译)
在树莓派上搭建kaldi离线语音识别系统(交叉编译) 一、系统功能和环境概述1.1、实现功能1.2、开发环境 二、kaldi语音识别工具箱三、树莓派的相关配置四、kaldi交叉编译过程4.1、配置Ubuntu中的交叉编译环境4.2、kaldi相关依赖工具的交叉编译4.2.1 openFST的交叉编译过程4.2.2 OpenBlas的交叉编译过程4.2.3 clapack的交叉编译过程4.2.
kaldi数据准备(二)
local/prepare_data.sh 创建data/train, data/test, (data/dev可选),每个文件里面必须包含text, wav.scp, utt2spk, spk2utt for x in train_yesno test_yesno; docat data/$x/text | awk '{printf("%s global\n", $1);}' > data/

第六篇【传奇开心果系列】Python文本和语音相互转换库技术点案例示例:深度解读Kaldi库个性化定制语音搜索引擎
传奇开心果短博文系列 系列短博文目录Python文本和语音相互转换库技术点案例示例系列 短博文目录前言一、雏形示例代码二、扩展思路介绍三、数据准备示例代码四、特征提取示例代码五、声学模型训练示例代码六、语言模型训练示例代码七、解码示例代码八、评估和调优示例代码九、扩展功能示例代码十、深入研究Kaldi的相关文档、论文和示例,以了解更多细节和技术细节十一、与Kaldi的社区和其他用户进行交流和

服务器和虚拟机怎么安装Kaldi?
文章目录 前言克隆kaldi到本地tools/INSTALL安装检查依赖extras/check_dependencies.sh把四个依赖包放在tools/目录下修改Makefile文件检查g++是否安装安装irstlm(非必须) Src/INSTALL安装./configure --sharedmake depend和make测试egs/yesno/s5/的案例 前言 安装k

Kaldi知识点汇集
我的书: 淘宝购买链接 当当购买链接 京东购买链接 ##特征提取 ###MFCC compute-mfcc-feats.cc Create MFCC feature files.Usage: compute-mfcc-feats [options...] <wav-rspecifier> <feats-wspecifier> 其中参数rspecifier用于读取.wav文件,wspe

Ubuntu18.04构建语音识别工具Kaldi并跑通整个TIMIT数据集(包含使用GPU的DNN)
语音识别工具应用最广泛的当属Kaldi了。 文章目录 1. Kaldi简介2. Ubuntu18.04构建Kaldi2.1. 准备工作2.2. 编译Kaldi2.3. 测试Kaldi 3. 重要更新4. 再次更新 1. Kaldi简介 Kaldi是一个语音识别工具,在语音识别研究领域大量使用。以下摘录自博客: Kaldi是一个C++实现的语音识别工具,它使用Apache
Kaldi学习笔记(五)——使用CVTE训练好的SR模型做中文在线识别
关于Kaldi的下载与编译请参考:http://blog.csdn.net/snowdroptulip/article/details/78896915 CVTE公司开源其训练好的TDNN模型,我们可以使用该模型来进行在线识别。 一、下载 首先从http://kaldi-asr.org/models.html下载模型; 二、解压 把下载好的模型解压到egs