本文主要是介绍百度UIE:Unified Structure Generation for Universal Information Extraction paper详细解读和相关资料,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- Prompt
learning系列之信息抽取模型UIE:https://mp.weixin.qq.com/s/0lNUlUF_x95mED5B9iBpGg - 作者解读:https://www.bilibili.com/video/BV19g411Z7rZ/?spm_id_from=autoNext
- bilibili解读:https://www.bilibili.com/video/BV1LW4y1U7ch?spm_id_from=333.337.search-card.all.click
- 官方代码:https://github.com/universal-ie/UIE
- 代码:https://github.com/heiheiyoyo/uie_pytorch paddle
- paddle使用介绍:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/model_zoo/taskflow.md#%E4%BF%A1%E6%81%AF%E6%8A%BD%E5%8F%96
- 其他NER模型:https://github.com/z814081807/DeepNER
一、概述

二、相关问题
问题一:UIE三种语义单元到底是什么意思?

问题二、UIE中三种语义单元和prompt的关系?

问题三、loss函数是啥?
生成模型,交叉熵
问题四、预训练如何做?
Dpair: text-to-structure变换能力,Drecord: 解码能力,Dtext:语义encoding能力



问题四、实验效果
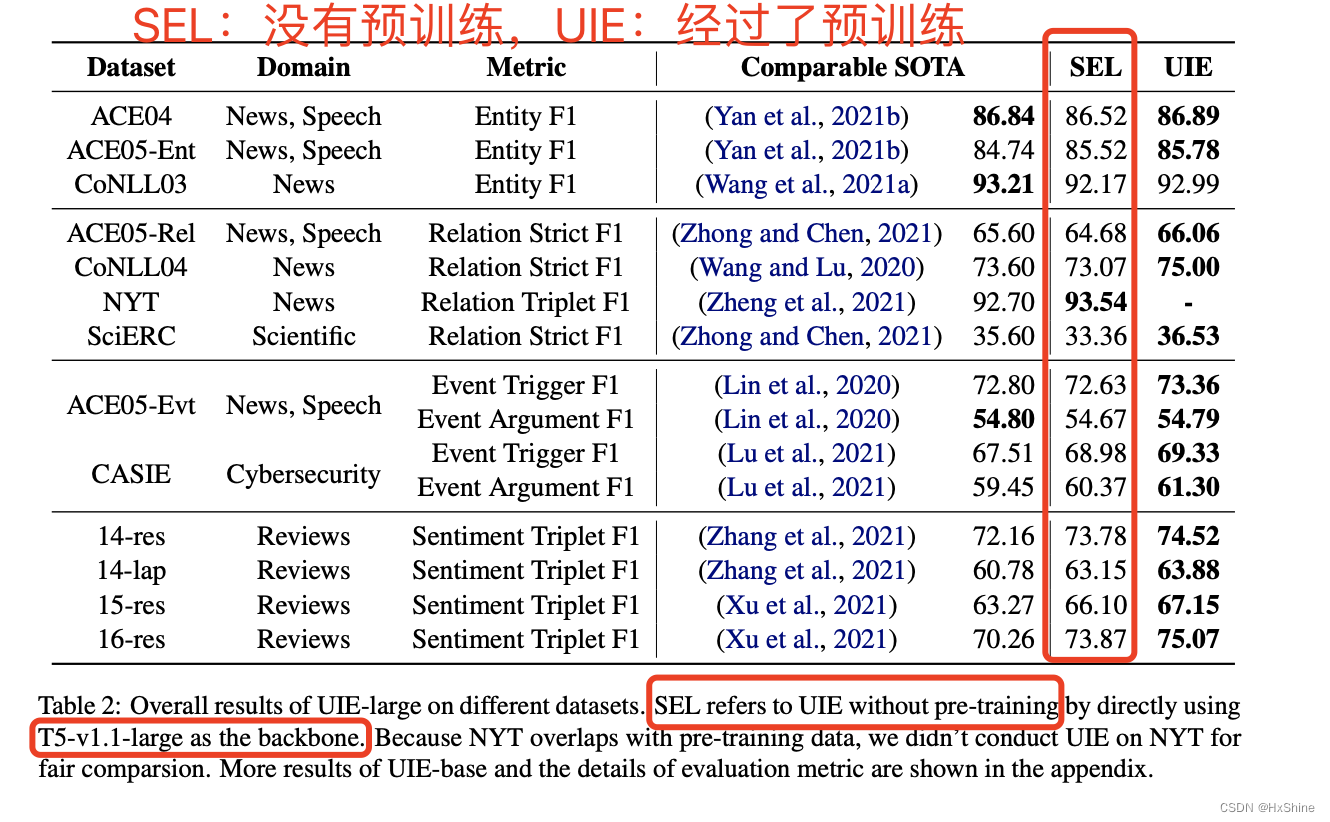
4.2监督学习:没有预训练效果都不错,加上预训练效果更好了。
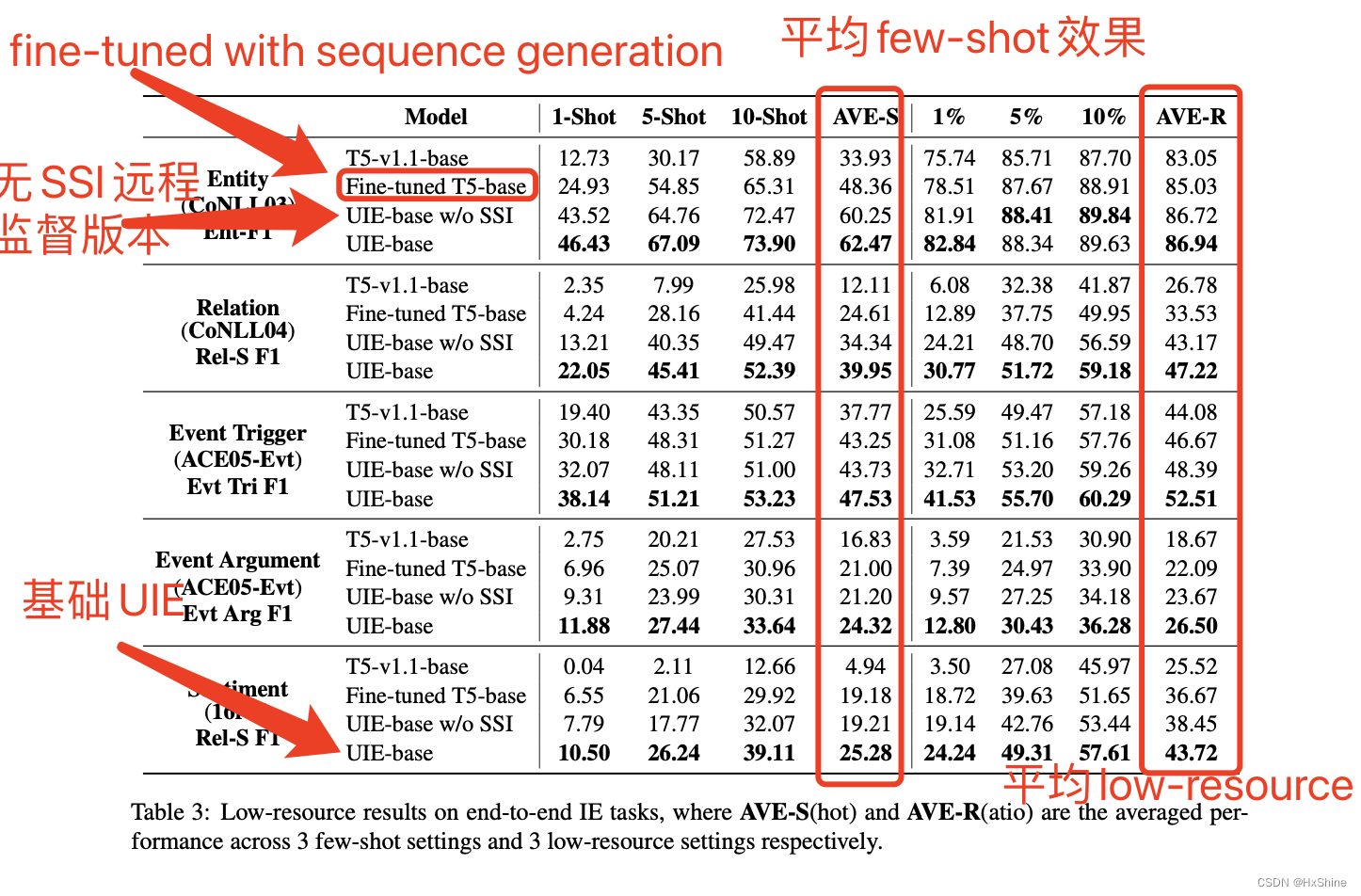
4.3 few-shot和low-resource效果:证明UIE强大的通用的信息抽取的能力
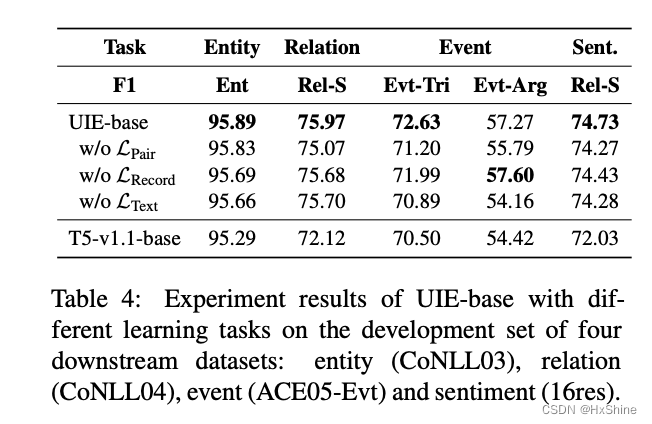
4.4 消融实验
不同的预训练任务的作用
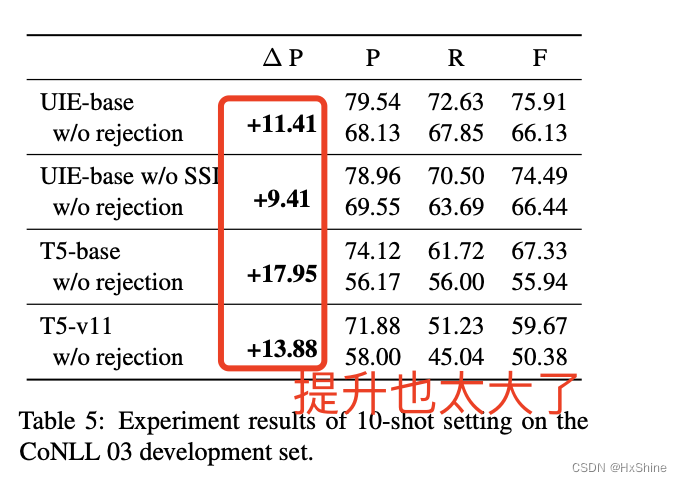
曝光偏差优化带来的提升(10-shot)
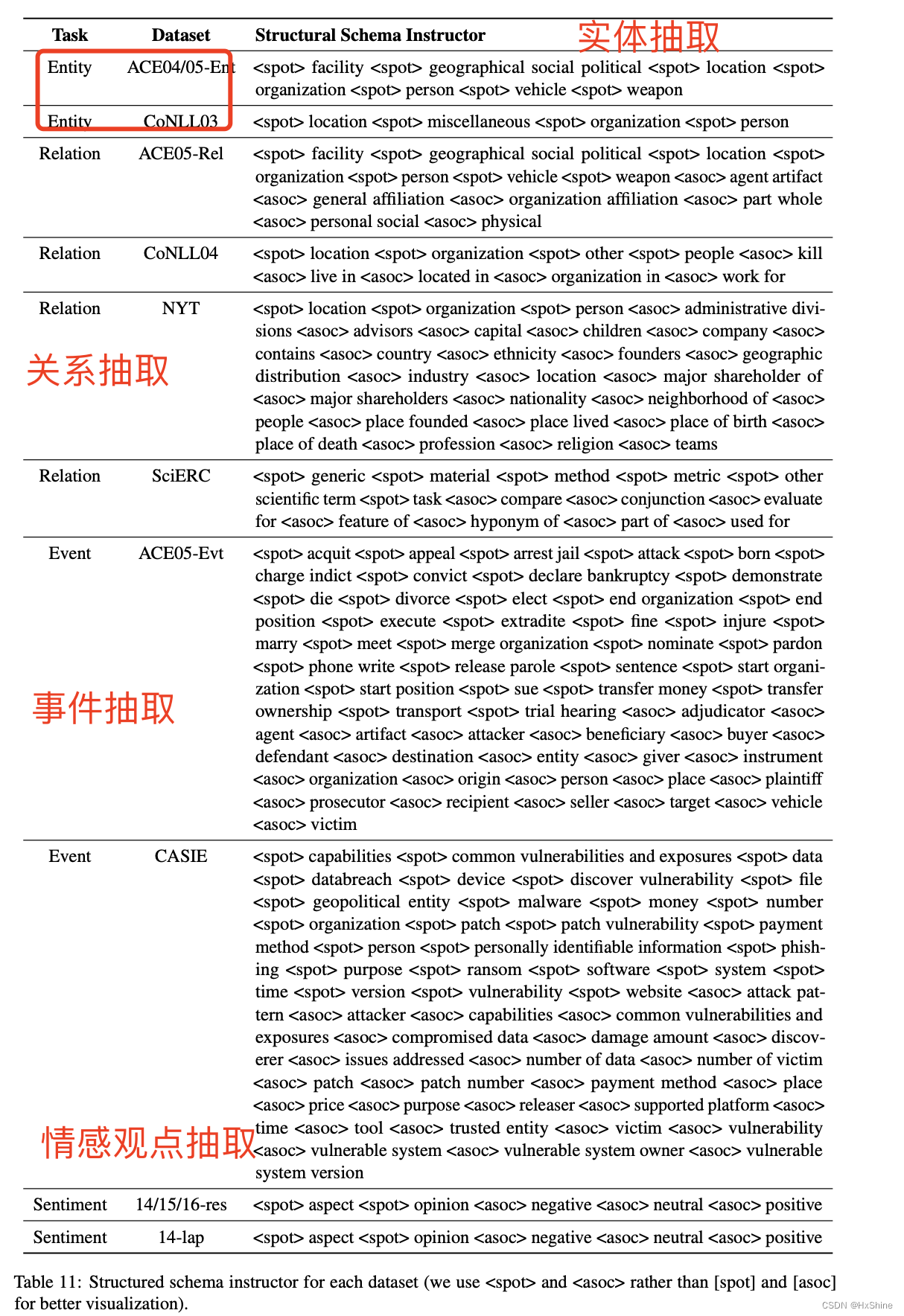
问题5:structural Schema Instructor如何设置?
不应该是一个模板抽取一个关系吗?咋感觉好像打平全都放进去了
问题六、finetune如何做?
三、原文详细内容
Abstract
信息抽取对不同的抽取目标,有不同的schema
unified text-to-structure generation的方法贡献统一了信息抽取的架构
可同时学习不同源的知识
实现:
prompt,structural schema instructor
大规模的text-to-structure的预训练模型,来学习通用的IE抽取能力实验
成果:
4个IEtask,12种datasets监督学习,low-resource,few-shot数据实体,关系,事件,情感抽取都取得了state-of-the-art的performance
1 introduction
1.1 通用方法缺点:
varying targets:(entity,relation,event,sentiment,etc)
heterogeneous structrues:(spans,triplets,records,etc)
demand-specific schemas现在大多数模型都是task-specialized,不利于学习交叉领域的IE能力
构建specialized任务对于不同的IE task,非常耗时间
1.2 IE是什么
IE:text-to-structure transformations
entity:span structrue
event:schema-defined recordatomic eperations
1.3 如果转化成通用的模型:
spotting:想要抽取的实体词的类型desirable spans,例如人,情感实体等
associating:schemas中的关系类型,例如work forentity extraction:
spotting mention spans of entity typesevent detection:
spotting triggers spans with event typesspotting abilities can be shared between these two tasks
UIE extraction language (SEL) :将不同的抽取任务统一成同一种生成的方式来做。
structural schema instructor (SSI):schema-based prompt mechanism:控制抽取什么实体,什么关系,以及生成什么(what to spot,what to associate,what to generate)
1.4 如何提升通用抽取能力
如何学习通用的抽取能力:在大量的,各式各样的数据集上进行预训练->通用抽取能力更好的适应supervised,
效果:
low-resource,few-shot的任务supervised:提升1.42%,
few-shot或者low-resource setting:带来了巨大的提升。
1.5 contributions:
UIE:同义抽取框架适应不同IE任务,可以联合学习通用的抽取能力设置了unified structure generation network:
通过structural extraction language控制what to spot,which to associate and which to generatea
large-scale text-to-structure pre-trained extraction model
2 UIE Unified Structure Generation for Universal Information Extraction
指导期:structural schema instructor (SSI):schema-based prompt机制
结构化抽取语言:extraction language (SEL): to uniformly encode heterogeneous extraction structures
2.1 atomic operationsspotting(目标信息片段):
实体,事件触发词:Spotting indicates locating target information pieces from the sentence, e.g., the entity and the trigger word in the event.
associating:relation的目标实体,或者事件中的role和argumentAssociating indicates connecting different information pieces based on the desirable associations, e.g., the relation between entity pair or the role between event and its argument(论点).
优点
- 统一了IE的encodes方式
- 有效表达了抽取的结果,自然可以用于联合抽取
- 降低了解码的复杂度
example实体抽取:(SpotName: InfoSpan)关系抽取&事件抽取:(SpotName: In- foSpan (AssoName: InfoSpan), …)
2.2.1 SSIstructural schema instructor (SSI):s
chema-based prompt机制y = UIE(s + x)s = [s1, …, s|s|] is the structural schema instructor, and y = [y1, …, y|y|] is a SEL sequence that can be easily converted into the extracted information record
example: [spot] person [spot] com- pany [asso] work for [text]作用有效的指导UIE中SEL的生成可以控制which to spot,which to associate,which to generate
2.2.2 Structure Generation with UIE
(s+x) => linearized SELauto-regressive style.
结束位置:eos
yi , hdi = Decoder([H; hd1 , …, hdi−1 ])
可以用BART或者T5等模型
3 pre-training and fine-tuning for UIE
- how to pre-train a large-scale UIE model which captures common IE abilities for different IE tasks;
- how to adapt UIE to different IE tasks in different settings via quick fine-tuning.
- 如何预训练获得通用的抽取能力
- 如何进行finetune先大量预料预训练 -> 然后特殊下游人物finetune
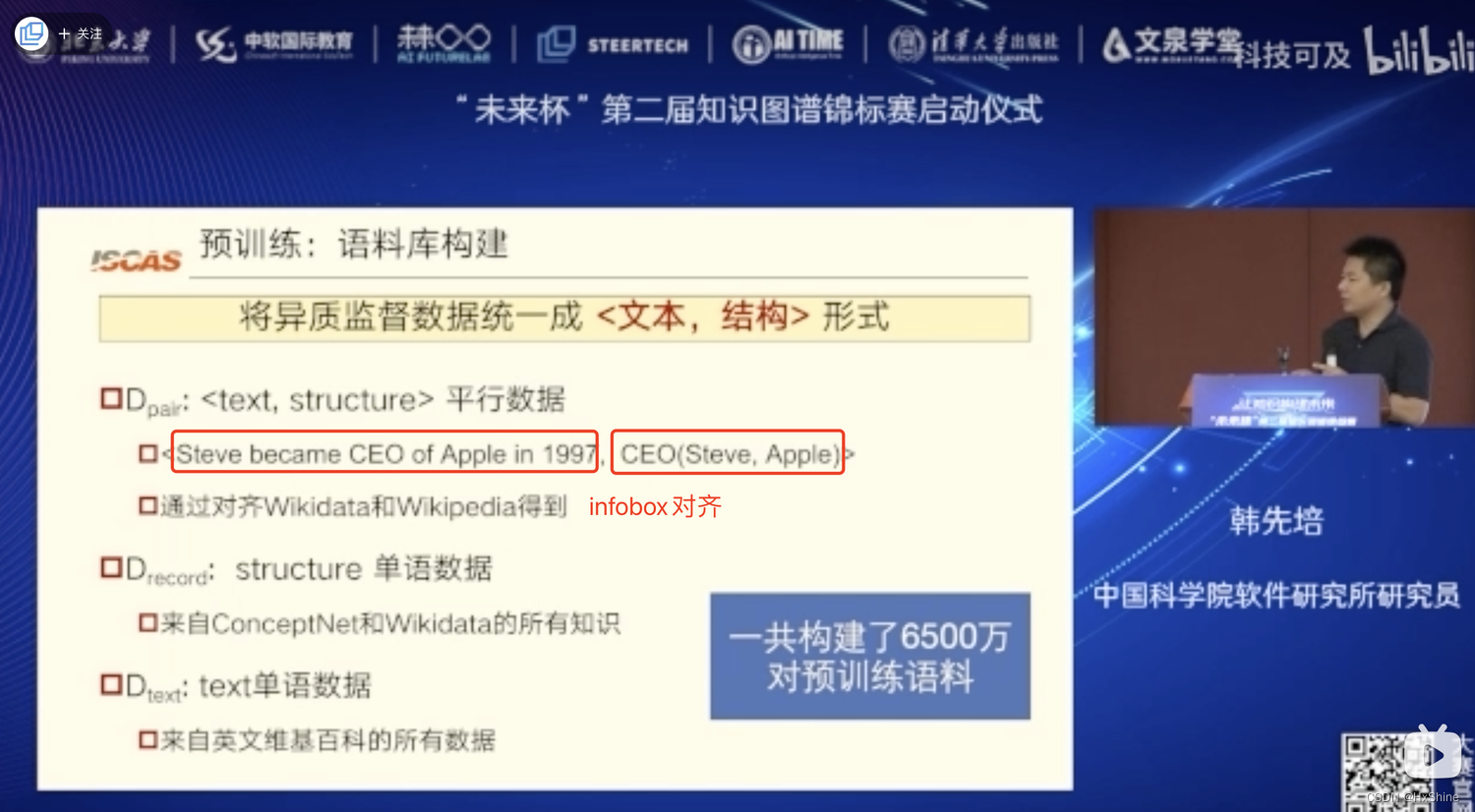
3.1 pre-training corpus construction
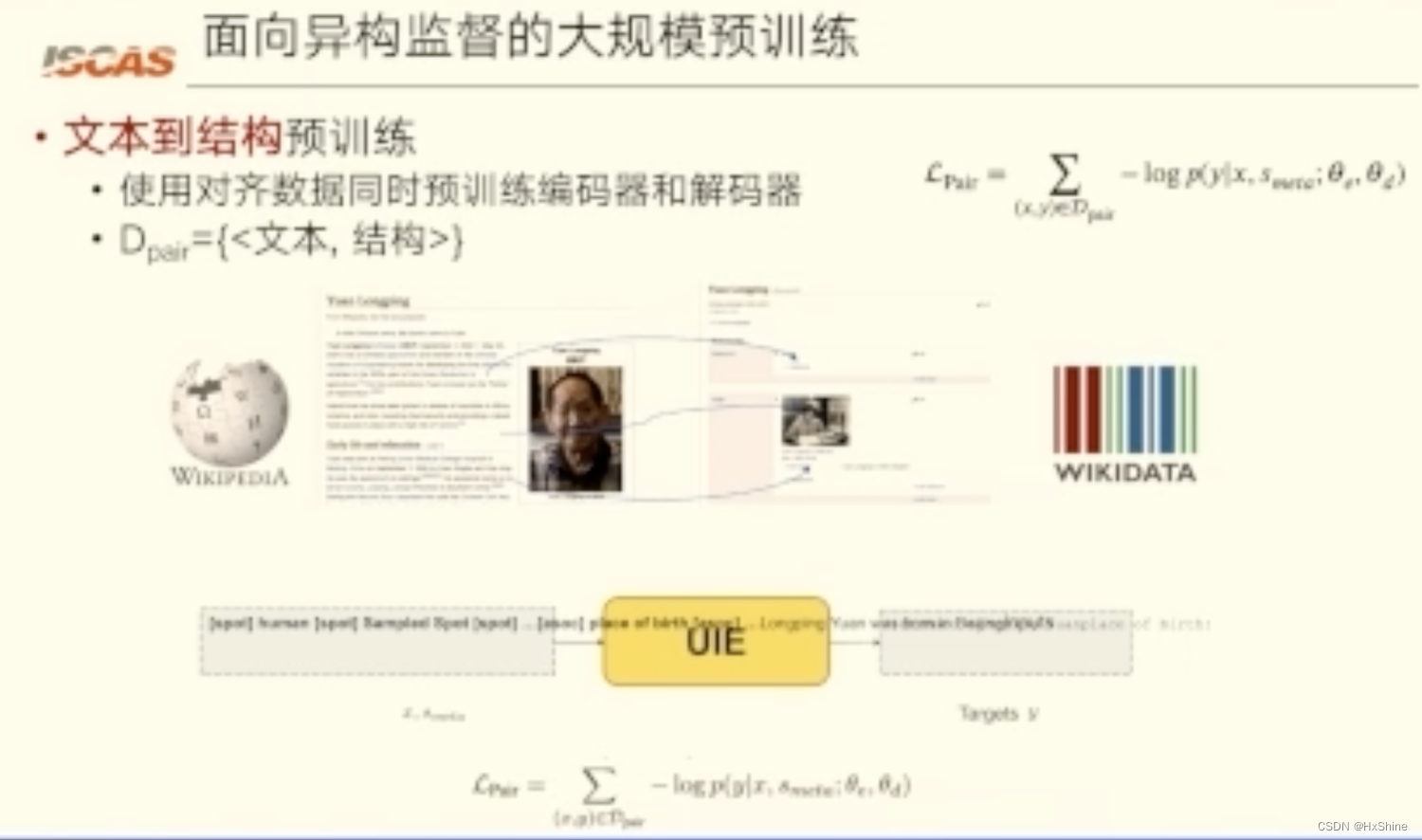
Dpair = {token sequence x, structured record y}我们通过将 Wikidata 与英语 Wikipedia 对齐来收集大规模的并行文本结构对。 Dpair 用于预训练 UIE 的文本到结构的转换能力。
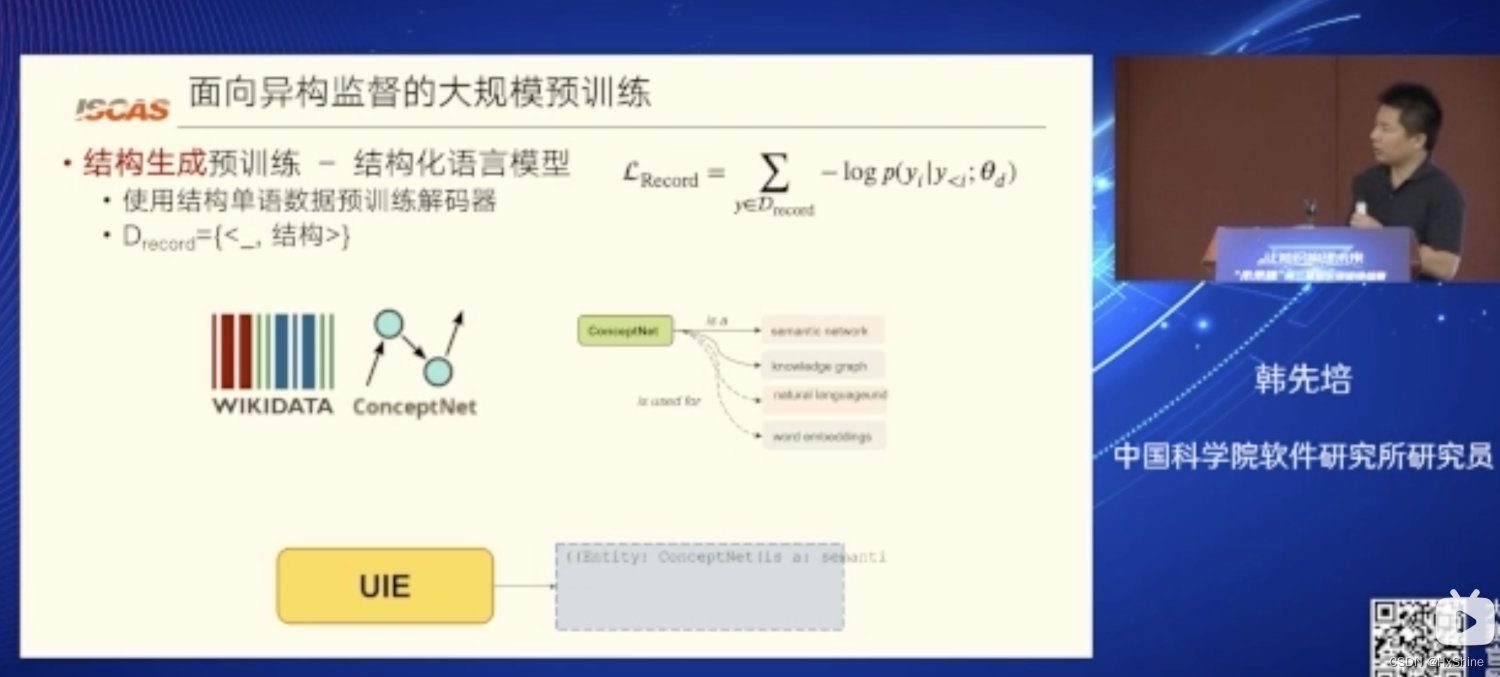
Drecord is the structure dataset where each in- stance is structured record y. We collect structured records from ConceptNet (Speer et al., 2017) and Wikidata. Drecord is used to pre-train the structure decoding ability of UIE.
Drecord 是结构数据集,其中每个实例都是结构化记录 y。 我们从 ConceptNet (Speer et al., 2017) 和 Wikidata 收集结构化记录。 Drecord用于预训练UIE的结构解码能力。
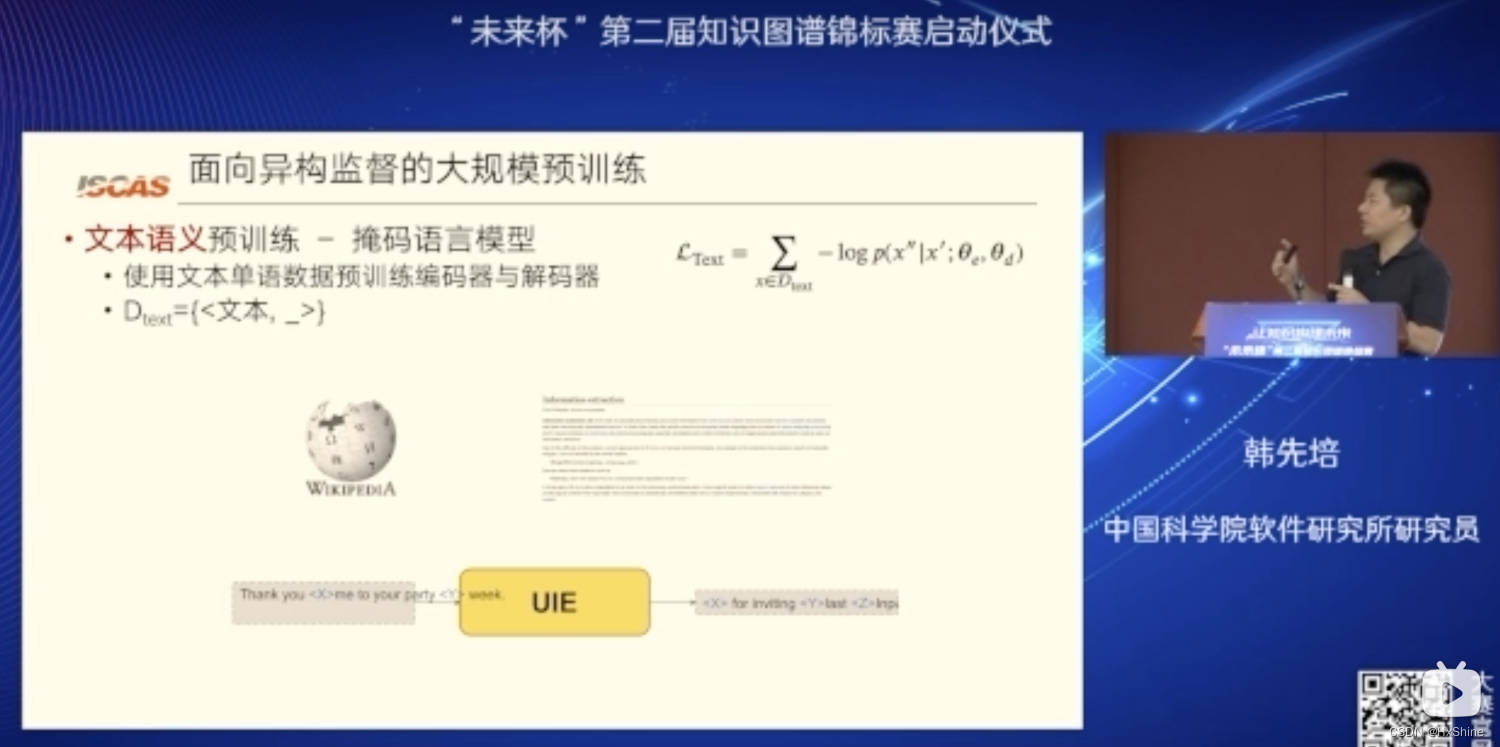
Dtext is the unstructured text dataset, and we use all plain texts in English Wikipedia. Dtext is used to pre-train the semantic encoding ability of UIE.
Dtext 是非结构化文本数据集,我们使用英文维基百科中的所有纯文本。 Dtext用于预训练UIE的语义编码能力。Dpair: text-to-structure变换能力,
Drecord: 解码能力,Dtext:语义encoding能力3.2 pre-training
- Text-to-Structure Pre-training using DpairFor example, person and work for is the positive schema in the record “((person: Steve (work for: Apple)))”, and we sample vehicle and located in as the negative schema to construct meta- schema.这个是在干啥?让他具有啥能力?
- Structure Generation Pre-training with Drecord(解码能力).
- MLM + span corruption (这个提升比较大)=> 减轻spotname和assoname的灾难性遗忘: catastrophic forgetting of token semantics especially on SPOTNAME and ASSONAME tokens.L = LPair + LRecord + LText
3.3 On-Demand Fine-tuningDtask = {(s,x,y)} -> 交叉熵Rejection Mechanism => 减轻曝光偏差问题exposure biasRM:注入噪音通过RM,UIE能学会拒绝错误生成的NULL的结果
4 Experiments
4.1 dataset
13 IE benchmarks(ACE,CoNLL), 4 well-representative IE tasks
entity extraction, relation extraction, event extraction, structured sentiment extraction
UIE only generates text spans -> finding the first matched offsets -> offsets
4.2 supervised settings
SEL+不加预训练:基本都state-of-the-art了
UIE(带预训练):效果都state-of-the-art了improves 1.42% F1 on average
4.3 Low-resource settingslow-resource:1/5/10-shot, 1/5/10% ratiofew-shot: sample 1/5/10 sentences ofr each entity/relation/event/sentiment type
这篇关于百度UIE:Unified Structure Generation for Universal Information Extraction paper详细解读和相关资料的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





