本文主要是介绍自定义数据 微调CLIP (结合paper),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CLIP 是 Contrastive Language-Image Pre-training 的缩写,是一个擅长理解文本和图像之间关系的模型,下面是一个简单的介绍:
优点: CLIP 在零样本学习方面特别强大,它可以(用自然语言)给出图像的描述,并在基于该描述对新图像进行分类方面表现良好,例如,您可以将图像描述为“a”。猫的黑白照片”,CLIP 可以准确地对猫的新照片进行分类,即使它以前没有见过这些特定图像。
训练: CLIP 在从互联网收集的大量文本图像对数据集上进行训练,这使得它能够学习视觉概念及其描述之间的联系。
局限性: CLIP 也有缺点,训练的计算成本可能很高,并且在需要非常具体或抽象概念的任务上,或者对于与训练所用的文本描述非常不同的数据时,可能表现不佳。训练可能会将社会偏见引入模型中。
paper:Learning Transferable Visual Models From Natural Language Supervision
本文用CLIP做一个零样本分类,
CLIP训练的时候用的是图片和文本描述对,并没有分类的标签,那如何让CLIP做零样本分类?
我们需要给出标签的文本,让图像和所有的文本标签进行匹配,得分高的就是匹配到的标签文本。
paper中提到预测哪个文本整体与哪个图像配对,而不是该文本的准确单词。

下面通过一个kaggle数据集来具体说明。
这里选用indo fashion dataset, 它有15种印度服饰。
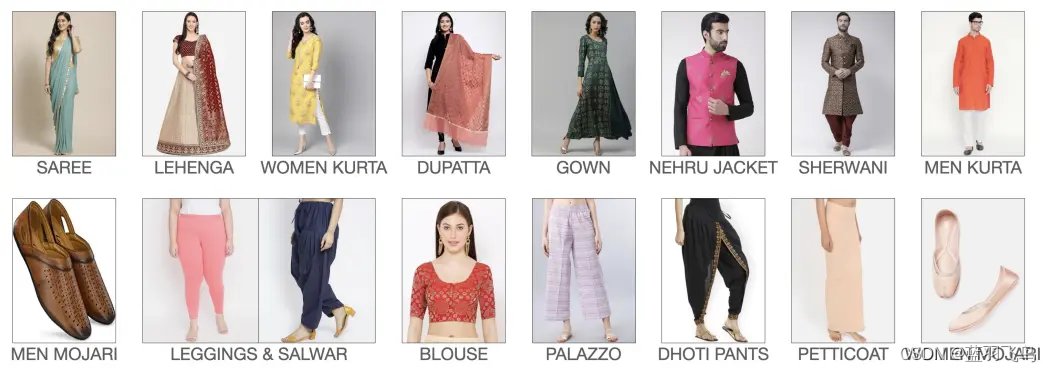
类别如下:

数据集结构:
其中images文件夹下又有train, val, test文件夹。
再看一下json文件,
image_path指的是上面images文件夹下的路径,
product_title是和图片对应的文本描述,训练的时候就是用图片和这个文本进行匹配。
class_label训练的时候不需要,最后验证分类是否正确时会用到。

import需要的库,定义数据集的文件夹,读取json数据
import json
from PIL import Image
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import clip
from transformers import CLIPProcessor,CLIPModel
from tqdm import tqdmjson_path = 'your_path/train_data.json'
image_path = 'your_path/images/train/'input_data = []
with open(json_path, 'r') as f:for line in f:obj = json.loads(line)input_data.append(obj)
CLIP模型,如果不能download, 手动下载走offline模式。
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
Setting our device to GPU (Cuda) and loading the pre-trained CLIP model.device = "cuda:0" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load("ViT-B/32", device=device, jit=False)
定义Dataloader
# Define a custom dataset
class image_title_dataset():def __init__(self, list_image_path, list_txt):self.image_path = list_image_path# Tokenize text using CLIP's tokenizerself.title = clip.tokenize(list_txt)def __len__(self):# Define the length of the datasetreturn len(self.title)def __getitem__(self, idx):image = preprocess(Image.open(self.image_path[idx]))title = self.title[idx]return image, title
这里的dataset需要传入list_image_path和list_txt,
格式是这种:
list_image_path = [‘folder/image1.jpg’,‘folder2/image2.jpg’]
list_txt = [‘description for image1.jpg’ , ‘description for image2.jpg’]
所以要把image_path和product_title都装进list里面。
注意,CLIP的最大序列长度限制在76, 而有些文本描述非常长,需要截掉一部分,
当然截到76长度也有很多种方法,这里简单粗暴就从开头取长度76.
实际代码中,indo数据集不限制长度会报错,而博主觉得这个76可能是text被tokenize之后的token的长度,而不是原文本的长度,
因为把文本截到长度>77也是可以的。
而token的长度是由tokenize的算法决定的。具体最大极限文本长度是多少没测,这里简单地截取到77.

list_image_path = []
list_txt = []
for item in input_data:img_path = image_path + item['image_path'].split('/')[-1]caption = item['product_title'][:77]list_image_path.append(img_path)list_txt.append(caption)dataset = image_title_dataset(list_image_path, list_txt)
train_dataloader = DataLoader(dataset, batch_size=100, shuffle=True) # Function to convert model's parameters to FP32 format
#转精度省内存.
def convert_models_to_fp32(model): for p in model.parameters(): p.data = p.data.float() p.grad.data = p.grad.data.float() if device == "cpu":model.float() # Convert the model's parameters to float if using CPU
optimizer用Adam,参数按paper中的设置.
不过博主的机器容纳不了这么大的batch_size, 具体batch_size设多少合适,需要自己去验证。
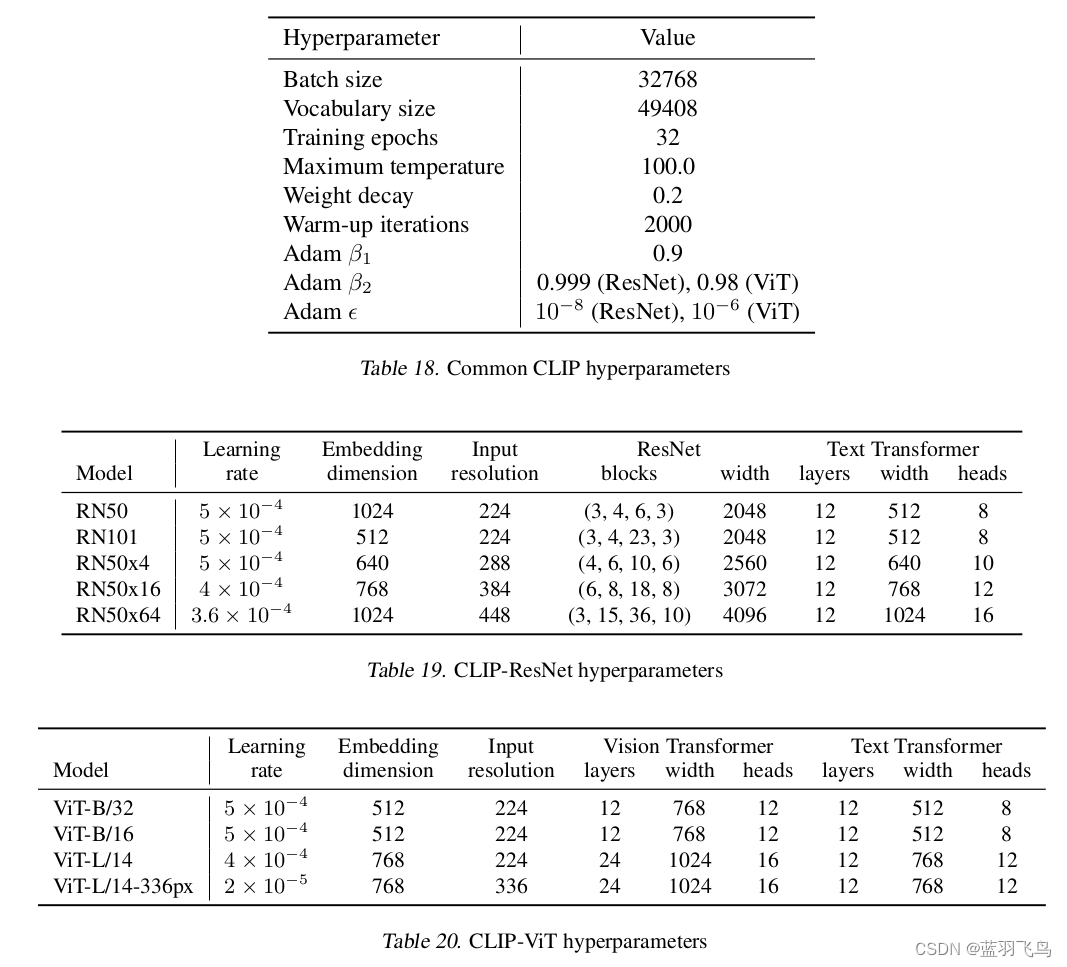
由于数据集比较小,lr设得更小一些。
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5, betas=(0.9, 0.98), eps=1e-6 ,weight_decay=0.2)
训练
paper中的训练是这样的

for epoch in range(num_epochs):pbar = tqdm(train_dataloader, total=len(train_dataloader))for batch in pbar:optimizer.zero_grad()images, texts = batchimages = images.to(device)texts = texts.to(device)logits_per_image, logits_per_text = model(images, texts)ground_truth = torch.arange(len(images), dtype=torch.long, device=device)total_loss = (loss_img(logits_per_image, ground_truth) + loss_txt(logits_per_text, ground_truth)) / 2total_loss.backward()if device == "cpu":optimizer.step()else:convert_models_to_fp32(model)optimizer.step()clip.model.convert_weights(model)pbar.set_description(f"Epoch {epoch}/{num_epochs}, Loss: {total_loss.item():.4f}")if torch.isnan(total_loss).any():print("epoch {} loss is NaN".format(epoch))epoch = num_epochsbreak
训练中,遇到了这些问题:
loss出现了NaN, 调整batch_size能解决,batch_size不要太小。
loss降不下去了,看看paper中的参数,有哪些需要调整。
训练完之后,找来一张图片测试。
这里又有一些注意事项,
请看paper.
因为训练的时候是图片和一段文本描述匹配的,而不是图片和一个单词。
所以你做零样本分类时,类别文本最好不要只写一个单词,比如只写"Saree"。
你要写"A photo of Saree", 这就成了一个句子,效果就会好一些。

model, preprocess = clip.load("ViT-B/32", device=device)checkpoint = torch.load("model.pt")
model.load_state_dict(checkpoint['model_state_dict'])clothing_items = ["Saree","Lehenga","Women Kurta","Dupatta","Gown","Nehru Jacket","Sherwani","Men Kurta","Men Mojari","Leggings and Salwar","Blouse","Palazzo","Dhoti Pants","Petticoat","Women Mojari"
]
这里你可能要问,那json文件里面的标签不是这么写的,比如"Women Kurta",json文件的标签是"women_kurta",
为什么不写成"women_kurta"。
这个博主是测试过的,写成json文件里面的标签形式准确率会降低,可能是因为"Women Kurta"更接近自然语言,更贴合训练数据吧。
把15个类别的标签都写成"A photo of {label}" 进行测试。
#你想测的第几张图片
index_ = 500
image_json = input_data[index_]
image_path = os.path.join("indo-fashion-dataset", image_json['image_path'])
image_class = image_json['class_label']
image = preprocess(Image.open(image_path)).unsqueeze(0).to(device)
text = torch.cat([clip.tokenize(f"a photo of a {c}") for c in clothing_items]).to(device)with torch.no_grad():# Encode image and textimage_features = model.encode_image(image)text_features = model.encode_text(text)# Calculate similarity scores between image and textlogits_per_image, logits_per_text = model(image, text)probs = logits_per_image.softmax(dim=-1).cpu().numpy()# Normalize image and text features
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)# Calculate similarity scores
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)# Print the top predictions
print("\nTop predictions:\n")
for value, index in zip(values, indices):print(f"{clothing_items[index]:>16s}: {100 * value.item():.2f}%")# Display the image with its class label
plt.imshow(plt.imread(image_path))
plt.title(f"Image for class: {image_class}")
plt.axis('off')
plt.show()


训练中并没有精调参数,也没有训练很多epoch. 效果如下。
统计了一下测试集中7450张图片的top1和top3准确率。
top1: 77.7%, top3: 93.57%

paper中说CLIP 模型的 Top-5 准确率明显高于其 Top-1 准确率, 本文虽测的是top3, 但也是明显高于top1的。

又试了一下这种方法,这里效果并没有变好。

参考资料1
参考资料2
这篇关于自定义数据 微调CLIP (结合paper)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




