定义数据专题

HTML5 data-*自定义数据属性的示例代码
《HTML5data-*自定义数据属性的示例代码》HTML5的自定义数据属性(data-*)提供了一种标准化的方法在HTML元素上存储额外信息,可以通过JavaScript访问、修改和在CSS中使用... 目录引言基本概念使用自定义数据属性1. 在 html 中定义2. 通过 JavaScript 访问3.
react笔记 8-16 JSX语法 定义数据 数据绑定
1、jsx语法 和vue一样 只能有一个根标签 一行代码写法 return <div>hello world</div> 多行代码返回必须加括号 return (<div><div>hello world</div><div>aaaaaaa</div></div>) 2、定义数据 数据绑定 constructor(){super()this.state={na

使用YOLOv10训练自定义数据集之二(数据集准备)
0x00 前言 经过上一篇环境部署的介绍【传送门】,我们已经得到了一个基本可用的YOLOv10的运行环境,还需要我们再准备一些数据,用于模型训练。 0x01 准备数据集 1. 图像标注工具 数据集是训练模型基础素材。 对于小白来说,一般推荐从一些开放网站中下载直接使用,官方推荐了一个名为Roboflow的数据集网站。Roboflow是一个免费开源数据集管理平台,它不仅提供免费的数据集,还

PyTorch数据加载:自定义数据集【Dataset:处理每个原始样本】【DataLoader:每次生成batch_size个样本】【collate_fn:重新设置一个Batch中所有样本的加载格式】
一、自定义Dataset Dataset是一个包装类: 用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。可以通过继承Dataset来将数据集的源文件、规模和其他非必要的功能打包,从而供DataLoader使用。 1、“文本分类”任务下使用自定义Dataset class.txt:所有类别 finance

【综合小项目】—— 爬取数据、数据处理、建立模型训练、自定义数据进行测试
文章目录 一、项目内容二、各步骤的代码实现1、爬取数据2、数据处理3、建立模型训练4、自定义数据进行预测 一、项目内容 1、爬取数据 本次项目的数据是某购物平台中某个产品的优质评价内容和差评内容采用爬虫的 selenium 方法进行爬取数据内容,并将爬取的内容分别存放在两个文本文件中 2、数据处理 分别读取存放数据的两个文本文件分别对优质评价和差评的内容进行分词导入停用词库,对
gaussian grouping训练自定义数据集
gaussian grouping是一个语义分割3DGS的方法。 它在每个3DGS点云中加入一个叫Identity Encoding的特征向量, 在渲染时把特征向量渲染到2D图像,每个像素位置为一个特征向量,使用额外的线性分类层对每个2D位置的特征向量分类。得到mask。 这个mask和gt mask计算2D损失,同时3D正则化损失利用3D空间一致性,强制执行Identity Encoding在特
TypeScript:择使用 interface 还是 class 来定义数据模型
在 TypeScript 中,选择使用 interface 还是 class 来定义数据模型通常取决于你的需求和设计考虑。以下是一些关于为什么你可能会选择使用 interface 而不是 class 的原因: 1. 仅定义数据结构 interface: 用于定义数据的结构和形状,但不包含实现逻辑。它主要用于描述对象的类型和结构。例如,你可能只关心 id、title 和 icon 这三个属

Go自定义数据的序列化流程
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」👈,持续学习,不断总结,共同进步,为了踏实,做好当下事儿~ 专栏导航 Python系列: Python面试题合集,剑指大厂Git系列: Git操作技巧GO系列: 记录博主学习GO语言的笔
如何通过理解数据在自定义数据集上逐步提升物体检测模型效果
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Tushar Kolhe 编译:ronghuaiyang 导读 以监控摄像头数据集的人体检测模型为例,说明了如何通过对数据的理解来逐步提升模型的效果,不对模型做任何改动,将mAP从0.46提升到了0.79。 介绍 目标检测能够完成许多视觉任务,如实例分割、姿态估计、跟踪和动作识别。这些计算机视觉任务在监控、自动驾驶和视觉问
YOLOV8 目标检测:训练自定义数据集
1、下载 yolov8项目:ultralytics/ultralytics:新增 - PyTorch 中的 YOLOv8 🚀 > ONNX > OpenVINO > CoreML > TFLite --- ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite (github

【多模态大模型教程】在自定义数据上使用Qwen-VL多模态大模型的微调与部署指南
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。 Qwen-VL-Chat = 大语言模型(Qwen-7B) + 视觉图片特征编码器(Openclip ViT-bigG) + 位置感知视觉语言适配器(可训练Adapter)+ 1.5B的图文数据

实战 | YOLOv10 自定义数据集训练实现车牌检测 (数据集+训练+预测 保姆级教程)
导读 本文主要介绍如何使用YOLOv10在自定义数据集训练实现车牌检测 (数据集+训练+预测 保姆级教程)。 YOLOv10简介 YOLOv10是清华大学研究人员在Ultralytics Python包的基础上,引入了一种新的实时目标检测方法,解决了YOLO以前版本在后处理和模型架构方面的不足。通过消除非最大抑制(NMS)和优化各种模型组件,YOLOv10在降低计算像素数
diffusers 使用脚本导入自定义数据集
在训练扩散模型时,如果附加额外的条件图片数据,则需要我们准备相应的数据集。此时我们可以使用官网提供的脚本模板来控制导入我们需要的数据。 您可以参考官方的教程来实现具体的功能需求,为了更加简洁,我将简单描述一下整个流程的关键点: 首先按照您的需求准备好所有的数据集文件,统一放到一个dataset_name(可以自己定义)目录下,可以划分多个子文件夹,但是需要在您的matadata.json中描述

【MMdetection】2.自定义数据训练
1.废话 因为MMdetection里面提供了非常多的模型和配置文件供我们选择,这样做对比实验非常方便。 在标准数据集上训练预定义的模型 — MMDetection 3.3.0 文档 官方文档在此。 openMMlab提供了各种经典网络和配置文件系统使得MMdetection的上手难度有一点,不熟悉官方常规操作的小伙伴可能被各种各样的配置文件弄晕,这里总结网上一些优秀博主的博客和视频教程,
MedSAM 学习笔记(续):训练自定义数据集
1、下载官方权重 官方的预训练权重:https://dl.fbaipublicfiles.com/segment_anything/sam_vit_b_01ec64.pth 下载后保存在:work_dir/SAM/sam_vit_b_01ec64.pth 目录 2、摆放数据集 因为MedSAM 分割模型需要对3D数据集进行切片处理,也就是对nii.gz 数据处理成 npy 格式
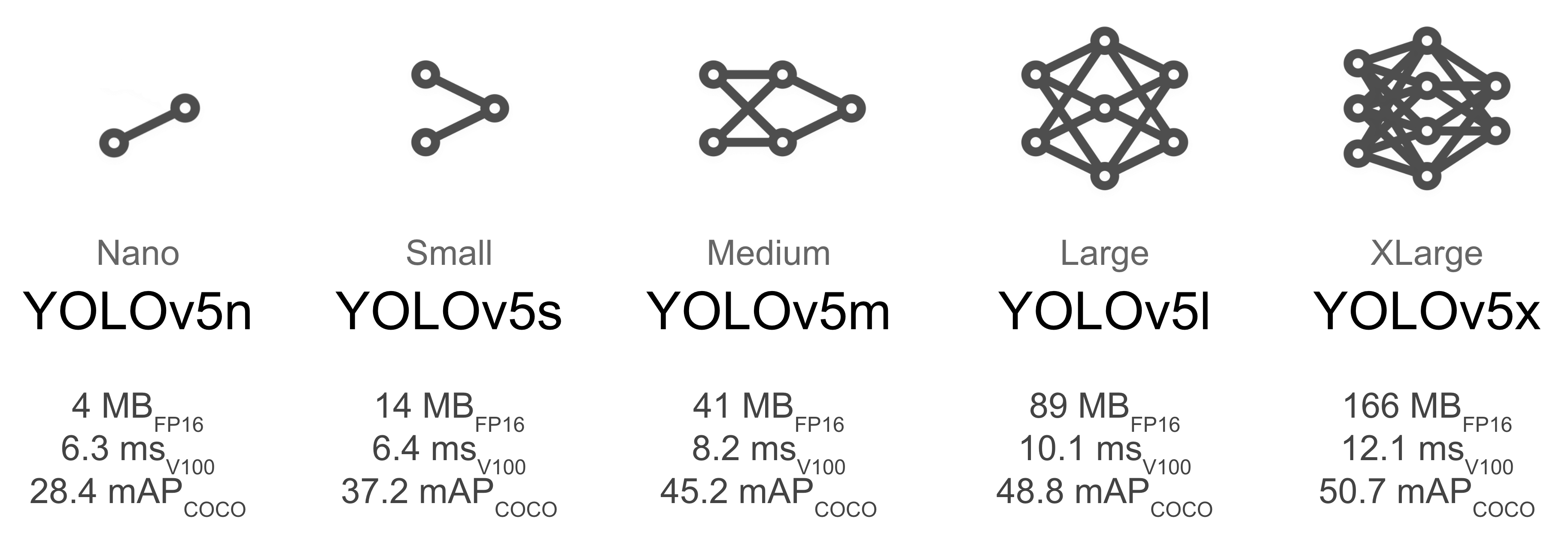
YOLOv5训练自定义数据集模型的参数与指令说明
文章目录 一· 概述二· 准备工作三· 参数说明四· 训练模型4.1 单 GPU 训练4.2 多 GPU 训练 五· 模型评估指令示例1. 单 GPU 训练2. 多 GPU 训练 一· 概述 📚 本文档主要记录如何在单台或多台机器上使用单个或多个 GPU 正确训练 YOLOv5 数据集 🚀。 二· 准备工作 训练环境安装,参考YOLOv5训练环境的部署与测试 自定义

RandLA-Net 训练自定义数据集
https://arxiv.org/abs/1911.11236 搭建训练环境 git clone https://github.com/QingyongHu/RandLA-Net.git搭建 python 环境 , 这里我用的 3.9conda create -n randlanet python=3.9source activate randlanetpip install

【Pytorch】18.创建自定义数据集并根据文件名或对应文件名的文本文件获取labels
源码 MNIST_Training_By_FileName_Dataset MNIST_Training_By_TXTLabel 简介 本文主要探讨两种不同的数据集获取labels的方法 根据图片的文件名中获取文件标签 根据与图片名称相同的.txt文件获取文件名 根据图片名称获取labels 主要的区别在__init__方法中 def __init
自定义数据集图像分类实现
模型训练 要使用自己的图片分类数据集进行训练,这意味着数据集应该包含一个目录,其中每个子目录代表一个类别,子目录中包含该类别的所有图片。以下是一个使用Keras和TensorFlow加载自定义图片数据集进行分类训练的例子。 我们自己创建的数据集结构如下: data/train/class1/img1.jpgimg2.jpg...class2/imga.jpgimgb.jpg......valid

灾备建设中虚拟机备份自定义数据块大小应用
灾备建设中,传输备份数据时,自定义数据块大小可以帮助优化数据传输和存储效率。 确定数据块大小,首先,需要确定合适的数据块大小。这可以根据备份数据量和网络带宽来决定。通常情况下,较小的数据块可以更好地适应网络传输的限制,而较大的数据块可以提供更快的传输速度。 需要注意的是,自定义数据块大小可能涉及到一些额外的步骤和注意事项。例如,对于大型备份数据,分割和传输过程可能需要较长时间。此外,如果数

使用QLoRA在自定义数据集上finetuning 大模型 LLAMA3 的数据比对分析
概述: 大型语言模型(LLM)展示了先进的功能和复杂的解决方案,使自然语言处理领域发生了革命性的变化。这些模型经过广泛的文本数据集训练,在文本生成、翻译、摘要和问答等任务中表现出色。尽管LLM具有强大的功能,但它可能并不总是与特定的任务或领域保持一致。 什么是LLM微调? 微调LLM涉及对预先存在的模型进行额外的训练,该模型之前使用较小的特定领域数据集从广泛的数据集中获取了模式和特征。在“L

深度学习笔记_10YOLOv8系列自定义数据集实验
1、mydaya.yaml 配置方法 # 这里分别指向你训练、验证、测试的文件地址,只需要指向图片的文件夹即可。但是要注意图片和labels名称要对应# 训练集、测试集、验证机文件路径,可以是分类好的TXT文件,也可以直接是图片文件夹路径train: # train images (relative to 'path') 128 imagesval: # val images (re
EasyExcel自定义数据格式化
自定格式常量类 public class ExcelFormatConstants {public static final String DATE_FORMAT = "yyyy-MM-dd";public static final String NUMBER_FORMAT_DEFAULT = "#,##0.00";public static final String NUMBER_FORMAT

自定义数据上的YOLOv9分割训练
原文地址:yolov9-segmentation-training-on-custom-data 2024 年 4 月 16 日 在飞速发展的计算机视觉领域,物体分割在从图像中提取有意义的信息方面起着举足轻重的作用。在众多分割算法中,YOLOv9 是一种稳健且适应性强的解决方案,它具有高效的分割能力和出色的准确性。 在本文中,我们将深入探讨 YOLOv9 在自定义数据集上进行对象分割的训练过
【答读者问58】用backtrader实现一个基于高开低收之外的自定义数据实现的基本交易策略
这个策略模板主要实现了下面三个功能: 除了高开低收等行情数据,额外扩展了两列自定义数据使用了一篮子订单 策略逻辑存在一些很大的问题,感兴趣的童鞋们可以研究找一找哈,在下一篇文章中会更新这个策略逻辑中存在的问题。 import sysimport numpy as npimport pandas as pdimport backtrader as btclass ExtendPanda

机器学习笔记 - 基于pytorch的自定义数据集和数据加载器
PyTorch 提供了torch.utils.data.DataLoader和torch.utils.data.Dataset 允许您使用预加载的数据集以及您自己的数据。 Dataset存储样本及其相应的标签,并基于DataLoader进行迭代Dataset以访问样本。 自定义 Dataset 类必须实现三个函数:__init__、__len__和__getit