本文主要是介绍YOLOV8 目标检测:训练自定义数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、下载
yolov8项目:ultralytics/ultralytics:新增 - PyTorch 中的 YOLOv8 🚀 > ONNX > OpenVINO > CoreML > TFLite --- ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite (github.com)
直接下载即可
官方教程:Predict - Ultralytics YOLO Docs
2、环境配置
建立虚拟环境:conda cerate -n yolov8 python=3.8(版本需要>=3.7)
激活虚拟环境:conda activate yolov8
进入yolov8项目,直接pip即可: pip install ultralytics

3、训练
数据集的摆放都可以,只要和 yaml 文件配置好就行,这里摆放成本人习惯的形式

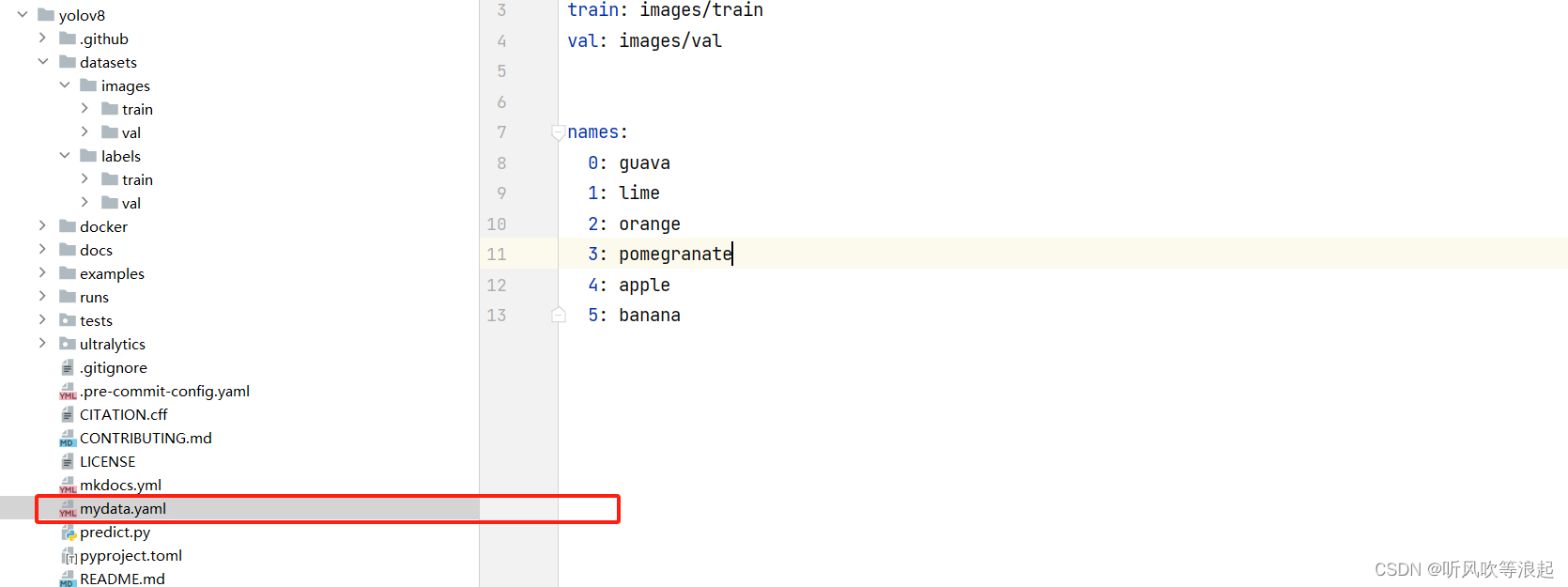
需要编写yaml文件,如下:
path: yolov8/datasets
train: images/train
val: images/valnames:0: guava1: lime2: orange3: pomegranate4: apple5: banana这里写法是mydata.yaml文件
path 是路径,绝对路径(相对路径)都可以,不过本人跑项目的时候填写绝对路径才行
train 脚本:
# encoding=gbkfrom ultralytics import YOLO#model = YOLO('../ultralytics/cfg/models/v8/yolov8n.yaml') # 建立模型
model = YOLO('./yolov8n.pt') # 预训练模型
model = YOLO('./yolov8n.yaml').load('./yolov8n.pt') # 载入权重model.train(data='./mydata.yaml')
4、训练过程
如下:
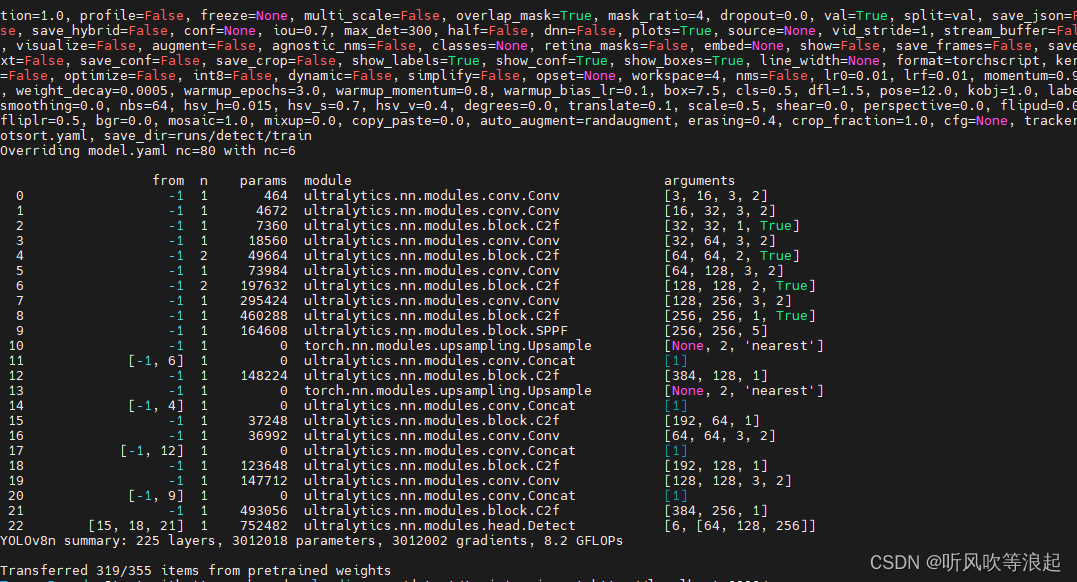


训练结果如下:

数据集是水果检测:

5、推理
脚本如下:
from ultralytics import YOLOmodel = YOLO('runs/detect/train/weights/best.pt')
model.predict('datasets/images/val',save=True)
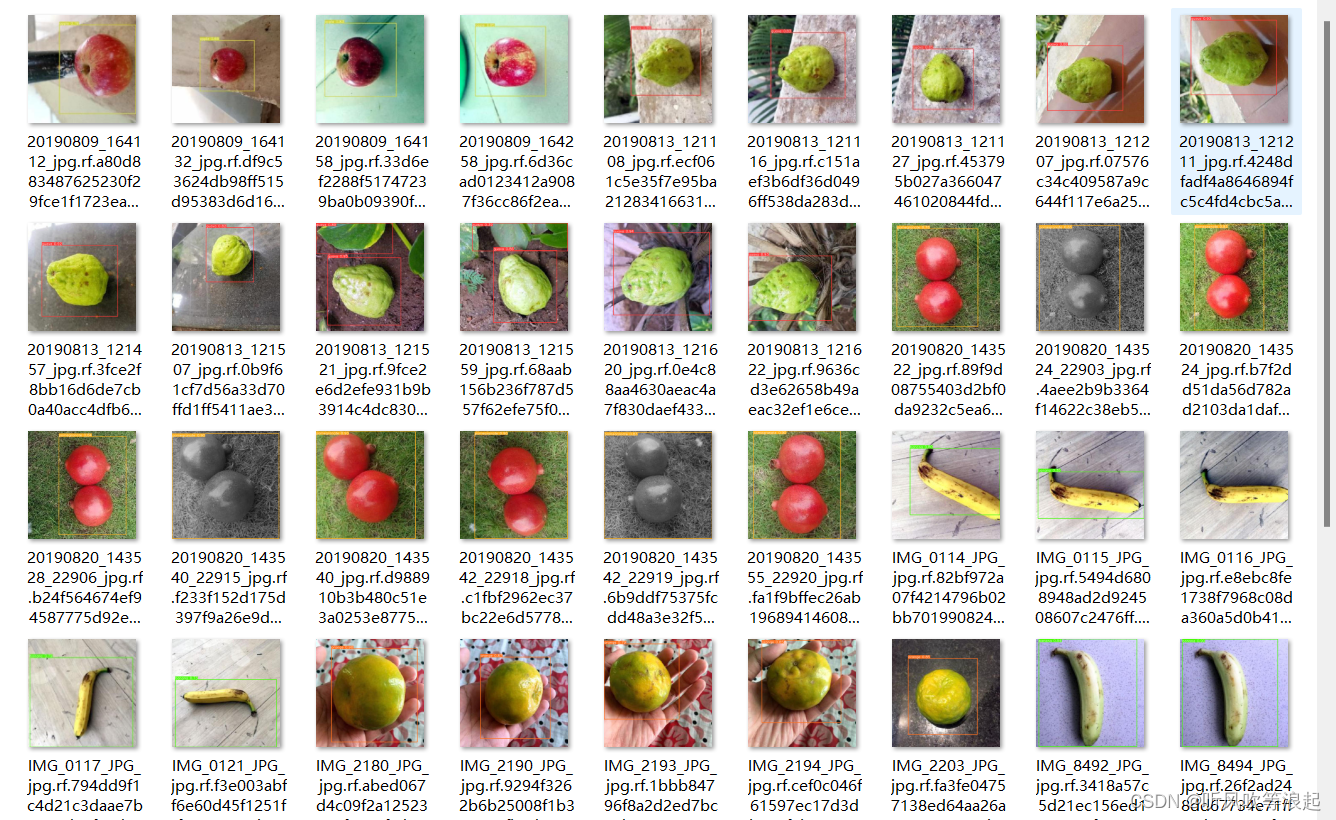
6、调参
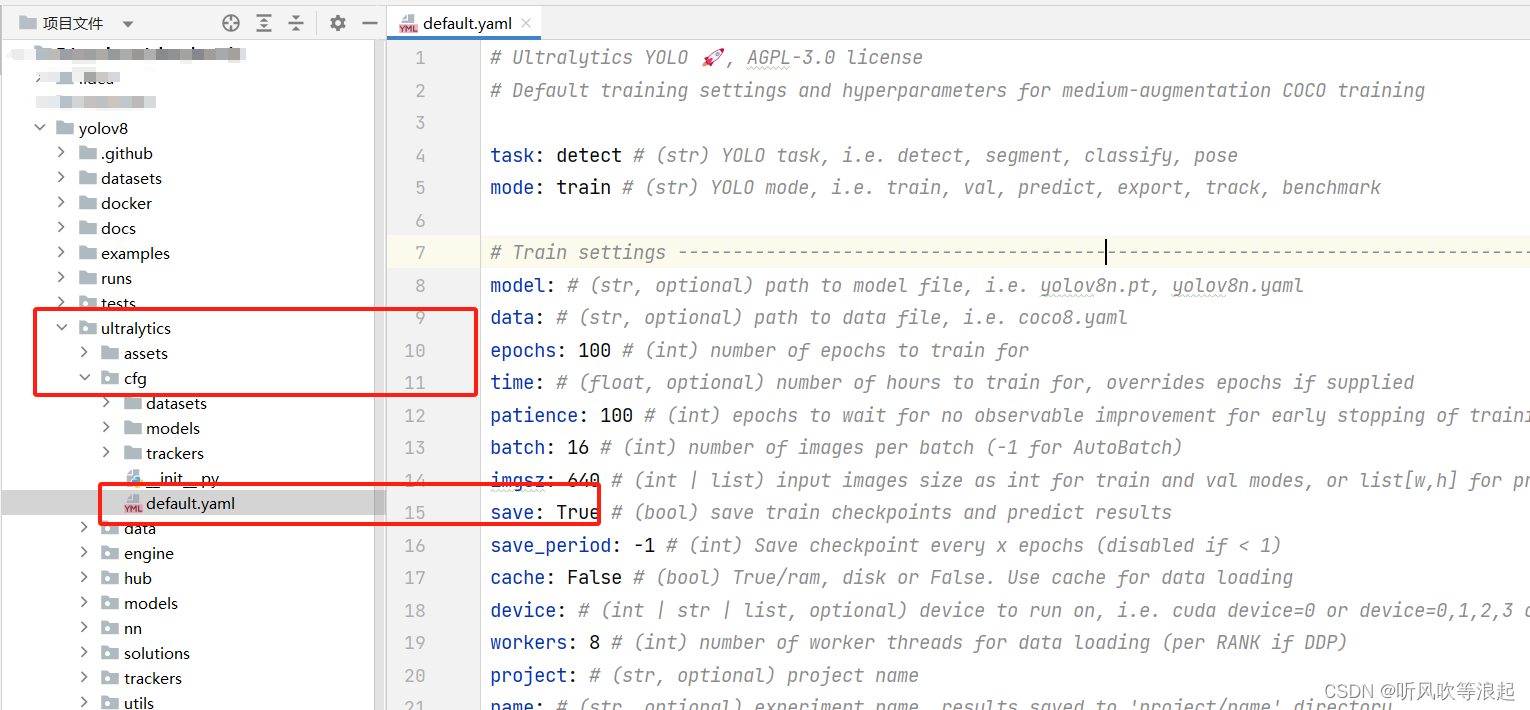
调参的话,可以在train脚本添加,更简单的直接更改文件即可:
yolov8\ultralytics\cfg\default.yaml
测试项目:基于yolov8对6种水果数据集的目标检测实现【数据+代码+训练好的权重】资源-CSDN文库![]() https://download.csdn.net/download/qq_44886601/89456431
https://download.csdn.net/download/qq_44886601/89456431
这篇关于YOLOV8 目标检测:训练自定义数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!