本文主要是介绍YOLOv5训练自定义数据集模型的参数与指令说明,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一· 概述
- 二· 准备工作
- 三· 参数说明
- 四· 训练模型
- 4.1 单 GPU 训练
- 4.2 多 GPU 训练
- 五· 模型评估
- 指令示例
- 1. 单 GPU 训练
- 2. 多 GPU 训练
一· 概述
📚 本文档主要记录如何在单台或多台机器上使用单个或多个 GPU 正确训练 YOLOv5 数据集 🚀。
二· 准备工作
训练环境安装,参考YOLOv5训练环境的部署与测试
自定义训练数据集处理,参考YOLOv5训练数据集的创建与格式说明
训练集配置文件的处理,参考YOLOv5训练数据集的配置文件说明
三· 参数说明
选择一个预训练模型作为训练的起点。这里我们选择 YOLOv5s,这是最小的、最快的可用模型。请参阅我们的 README 表格,了解所有模型的完整比较。我们将使用多 GPU 在 COCO 数据集上训练此模型。
首先看一下官方源代码脚本中提供了哪些参数:
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
先重点关注以下参数:
--weights:预训练权重的路径。默认为yolov5s.pt。--cfg:模型配置文件的路径。默认为空。如果指定此配置文件,模型将从头开始训练data: 训练数据集配置文件路径。默认为YOLOv5提供的coco128.yamlepochs: 训练轮次。默认为300batch-size: 每个 GPU 的批次大小。默认为16,按照GPU显存大小调整device: 指定使用的训练设备。可指定cuda device,如0或0,1,2,3或cpuname: 保存的项目名称。默认为exp,可根据实际情况修改
四· 训练模型
启动训练前,需要先下载预训练模型权重文件,下载地址:yolov5s.pt
如果你想从头开始训练,还需要根据自己的数据集创建一个模型配置文件,修改默认的模型配置文件,如 yolov5s.yaml,修改 nc 的值为你的数据集类别数。 例如,以猫狗识别数据集为例,将默认的 nc 值 80 修改为 2,如下所示:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
# nc: 5 # 原coco数据集类别数
nc: 2 # 自定义猫狗数据集类别数
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
4.1 单 GPU 训练
从预训练模型开始训练,训练自定义数据集或使用不同尺寸的模型,相应的更改 --data 或 --weights 参数即可,指令如下:
python train.py --weights yolov5s.pt --data coco.yaml --batch-size 64 --device 0 --name yolov5s_results
训练完成后,模型文件保存在 runs/train/yolov5s_results 目录下。
如果数据量足够多,可以选择从头开始训练,需要添加 --cfg 参数指定模型的配置文件,同时,--weights 参数值为空,指令如下:
python train.py --cfg yolov5s.yaml --weights "" --data coco.yaml --batch-size 64 --device 0 --name yolov5s_results
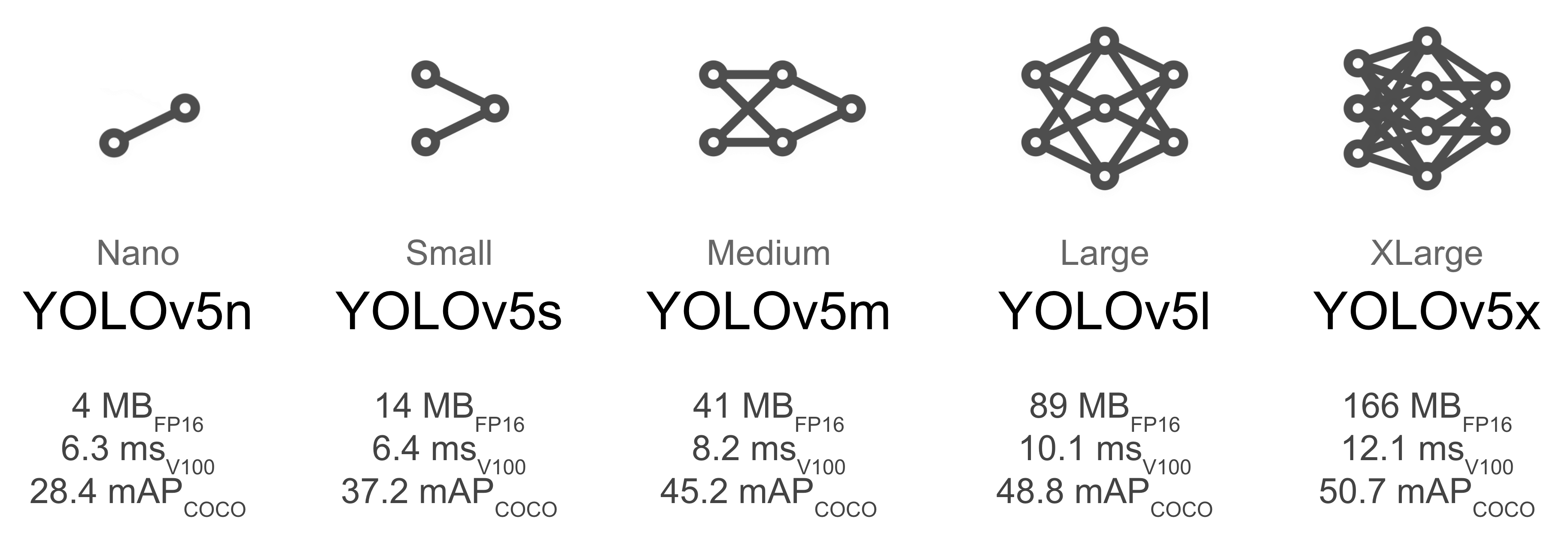
YOLOv5 提供了多种模型配置文件,如 yolov5s.yaml、yolov5m.yaml、yolov5l.yaml、yolov5x.yaml,可以根据实际情况选择合适的模型配置文件。
4.2 多 GPU 训练
多 GPU DataParallel 模式(⚠️ 不推荐)
你可以在 DataParallel 模式下增加设备以使用多个 GPU。
python train.py --weights yolov5s.pt --data coco.yaml --batch-size 64 --name yolov5s_results --device 0,1
与只使用 1 个 GPU 相比,此方法速度较慢,几乎不会加快训练速度。
多 GPU DistributedDataParallel 模式(✅ 推荐)
使用此模式需要使用指令 python -m torch.distributed.run --nproc_per_node,后面再跟上训练参数。例如,使用 2 个 GPU 训练 YOLOv5s 模型,指令如下:
python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --weights yolov5s.pt --device 0,1
注意:
--nproc_per_node参数指定你要使用的 GPU 数量。在上面的示例中,它是 2。--batch是总批次大小。它将平均分配给每个 GPU。在上面的示例中,它是 64/2= 32/GPU
💡 提示! 在
PyTorch>=1.9 中,torch.distributed.run替换了torch.distributed.launch。有关详细信息,请参阅文档。
使用特定 GPU
你可以通过简单地传递 --device 后跟你的特定 GPU 来做到这一点。例如,在下面的代码中,我们将使用 GPU 2,3。
python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --device 2,3
使用 SyncBatchNorm
SyncBatchNorm 可以提高多 GPU 训练的准确性,但是,它会显著降低训练速度。它仅适用于多 GPU DistributedDataParallel 训练。当每个 GPU 上的批次大小较小(<=8)时,最好使用它。要使用 SyncBatchNorm,只需将 --sync-bn 传递给命令,如下所示,
python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data coco.yaml --cfg yolov5s.yaml --weights '' --sync-bn
五· 模型评估
训练完成后,可以使用以下命令评估模型的性能:
python val.py --data coco.yaml --weights runs/train/yolov5s_results/weights/best.pt --task test
注意:
--weights参数指定了你要评估的模型的权重文件路径。在上面的示例中,它是runs/train/yolov5s_results/weights/best.pt。--task参数指定了你要执行的任务。在上面的示例中,它是test,表示评估模型在测试集上的性能,如果是val,表示评估模型在验证集上的性能。
指令示例
1. 单 GPU 训练
python train.py --weights "" --cfg /path/to/model_cfg.yaml --data /path/to/customer_dataset.yaml --epochs 300 --batch-size 16 --device 0 --name yolov5s_results
2. 多 GPU 训练
python -m torch.distributed.run --nproc_per_node 4 train.py --weights '' --device 0,1,2,3 --data /path/to/customer_dataset.yaml --cfg /path/to/model_cfg.yaml --batch 256 --epochs 300 --name yolov5s_results
这篇关于YOLOv5训练自定义数据集模型的参数与指令说明的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




