本文主要是介绍Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Abstract
本文将关系抽取任务转换为两个任务,HE抽取(头实体抽取)和TER抽取(尾实体和关系)
前一个子任务是区分所有可能涉及到object关系的头实体,后一个任务是识别每个提取的头实体对应的尾实体和关系,然后基于本文提出的基于span的标记方法将两个子任务进一步分解为多个序列标记任务,采用分层边界标记HBT和多跨度解码算法解决这些问题。本文的第一步不是提取所有实体,而是识别可能参与目标三元组的头实体,从而减轻冗余实体对的影响。
Model
标注策略
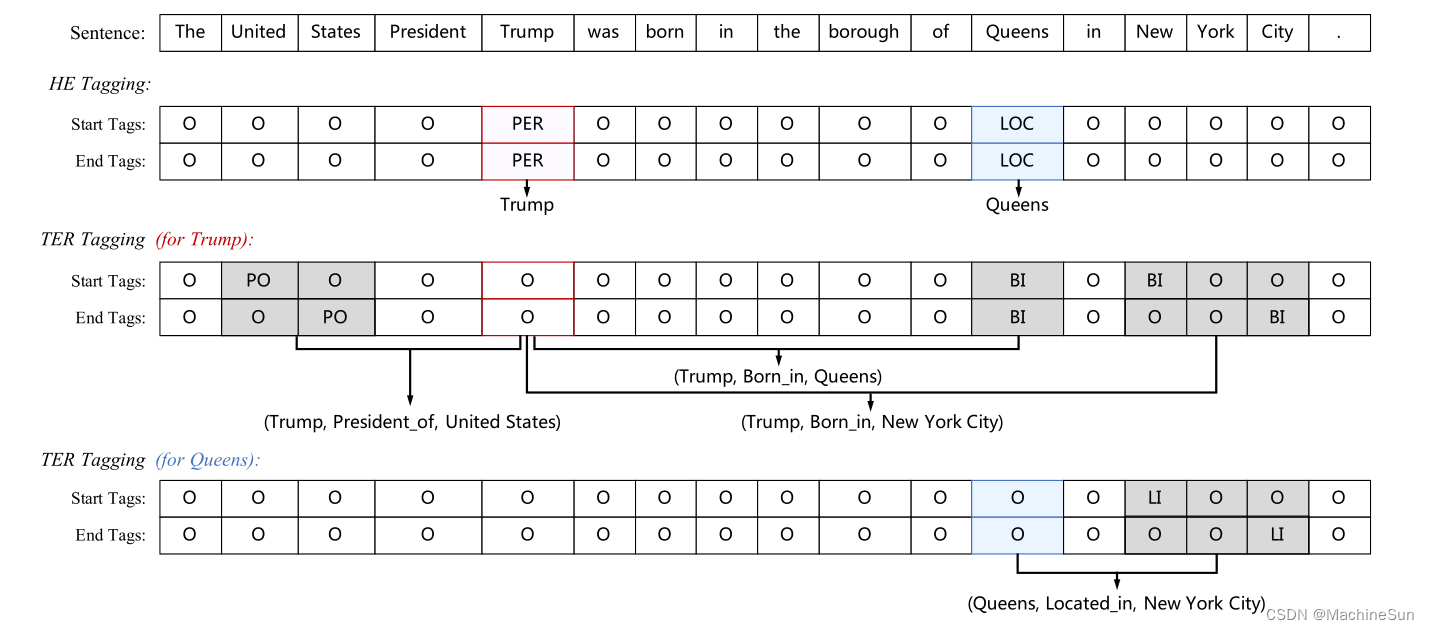
对于每个识别出的头实体,TER提取也分解为两个序列标注任务,利用跨度边界提取尾实体并同时预测关系。
第一个序列标记子任务主要标记尾实体的开始字标记的关系类型,第二个子任务标记结束字标记的关系类型。
模型
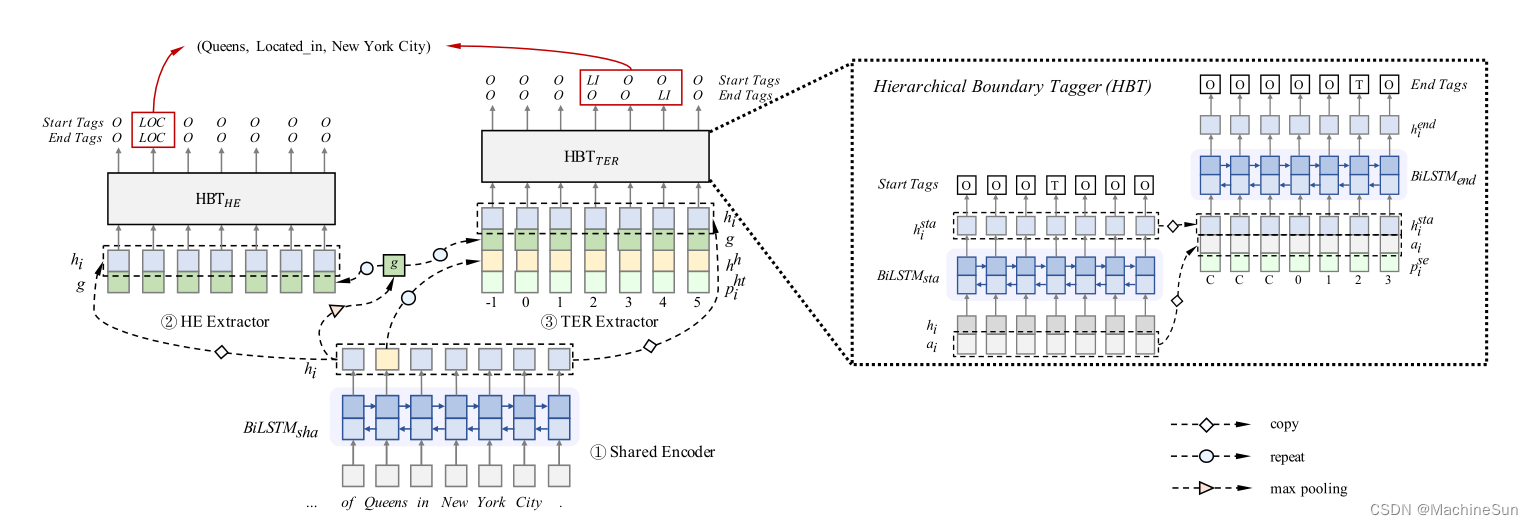
层次边界标记器HBT
使用LSTM编码。标注开始位置时,单词 x i x_i xi的标签被预测为:
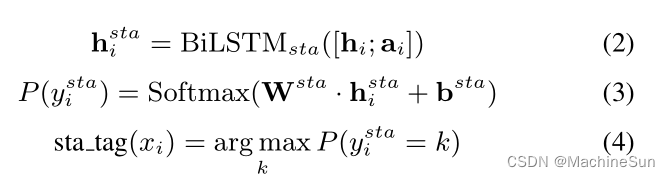
h i h_i hi是token的隐藏表示, a i a_i ai是辅助向量,从整个句子中学习到的全局表示
x i x_i xi的结束标签可以通过如下计算:
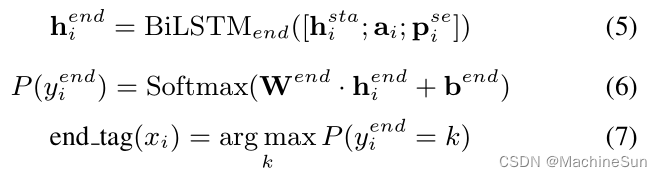
这里又增加了一个位置向量 p i s e p_i^{se} pise,在预测结束位置时能够感知起始位的隐藏状态,因此引入了 h i s t a h_i^{sta} hista
抽取模型

这个过程和级联二进制和multi-QA的方法几乎一样,或者说这三篇文章的思路都是一个思路
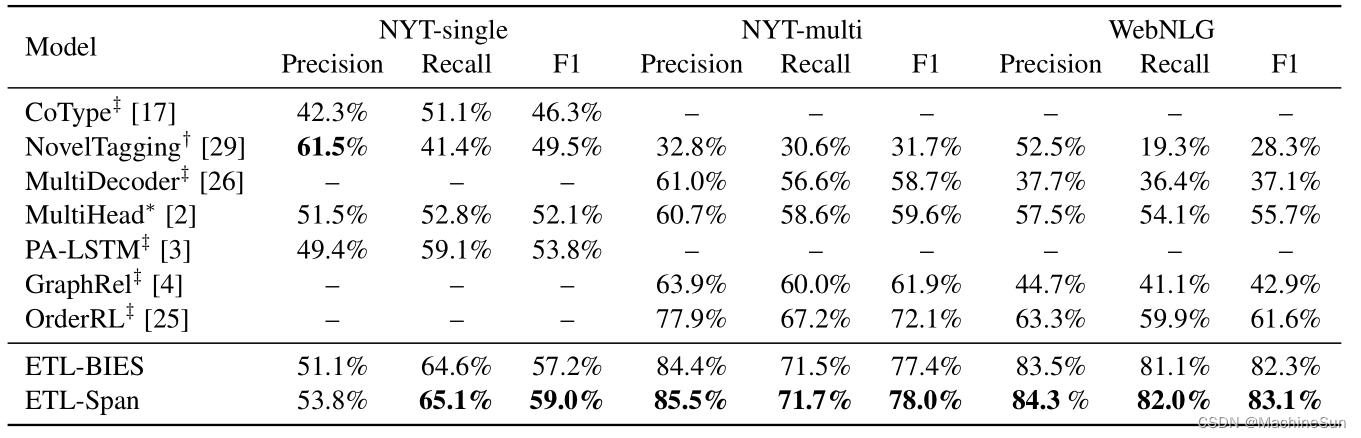
Result
启示
- 在没有用BERT的情况下达到了现在的分数,确实厉害,不过还是老生常谈的问题,时间复杂度太高了
- 感觉关系抽取太卷了,作为NLP,一个任务需要跑个十几个和二十多个小时,算力不充足的我太难受了,大家能run的就抓紧run吧。
这篇关于Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







