joint专题

Unity --hinge joint
关节介绍 关节一共分为5大类:链条关节,固定关节,弹簧关节,角色关节和可配置关节。 链条关节(hinge joint):将两个物体以链条的形式绑在一起,当力量大于链条的固定力矩时,两个物体就会产生相互的拉力。固定关节(fixed joint):将两个物体永远以相对的位置固定在一起,即使发生物理改变,它们之间的相对位置也将不变。弹簧关节(spring joint):将两个物体以弹簧的形式绑

DS简记1-Real-time Joint Object Detection and Semantic Segmentation Network for Automated Driving
创新点 1.更小的网络,更多的类别,更复杂的实验 2. 一体化 总结 终于看到一篇检测跟踪一体化的文章 网络结构如下: ResNet10是共享的Encoder,yolov2 是检测的Deconder,FCN8 是分割的Deconder。 其实很简单,论文作者也指出:Our work is closest to the recent MultiNet. We differ by focus

论文笔记 HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection
提出的HyperNet网络基于设计的Hyper特征,这种特征主要先集合分等级的特征图,然后将其压缩到一个空间。这种Hyper特征同时具有足够深和很好的语义信息,在PASCAL VOC 2007和2012上可以通过每张图产生仅仅100个proposal,而达到很好的精度和效果,同时可以达到实时,GPU下 5 fps的速度。 Hyper方法主要的贡献有: (1)在仅仅 50 proposal情况下

BERT for Joint Intent Classification and Slot Filling 论文阅读
BERT for Joint Intent Classification and Slot Filling 论文阅读 Abstract1 Introduction2 Related work3 Proposed Approach3.1 BERT3.2 Joint Intent Classification and Slot Filling3.3 Conditional Random Fiel

论文《Joint Cascade Face Detection and Alignment》笔记
论文:Joint Cascade Face Detection and Alignment.pdf 实现:https://github.com/FaceDetect/jointCascade_py 部分内容引用自:http://www.cnblogs.com/sciencefans/p/4394861.html#!comments 首先是简介: 论文首先介绍了一些当今人脸检测的技

Joint Cascade Face Detection and Alignment(JDA)文档
地址:https://github.com/luoyetx/JDA 一、算法流程图: 训练过程: 检测过程: 二、类图: 从上图可以看出整个系统主要分为两大模块,数据存储模块与CART模块,两个模块集中于JDA分类器上,整个系统只实例化一个JDA分类器,存储于Config中。 三、细节实现: 训练分为5个stage,每个stage训练一个cart森林,这里采用的是Real

论文阅读:Agreement-Based Joint Training for Bidirectional Attention-Based Neural Machine Translation
双向注意力模型,尽可能使注意力在两个方向上保持一致 模型的中心思想就是对于相同的training data,使source-to-target和target-to-source两个模型在alignment matrices上保持一致。这样能够去掉一些注意力噪声,使注意力更加集中、准确。 这篇文章胜在idea,很巧妙地想到了让正反向的注意力一致来改进attention。
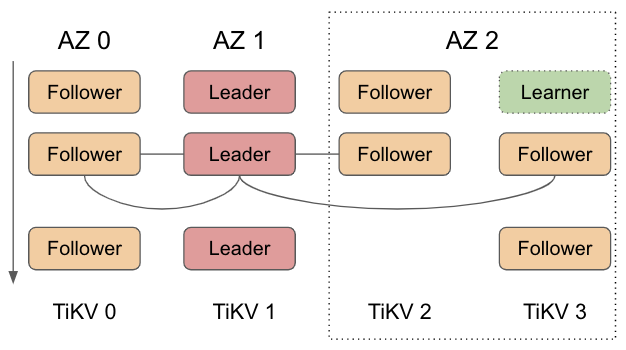
TiDB 5.0 跨中心部署能力初探 | Joint Consensus 助力 TiDB 5.0 无畏调度
TiDB 5.0 已于上周正式发布,在这个大版本更新中提升 TiDB 集群的跨中心部署能力是一个重要的着力点,在共识算法这一层,最激动人心莫过于 Joint Consensus 支持了。这个特性帮助 TiDB 5.0 在跨 AZ 的调度中完全容忍少数派数目的 AZ 不可用。本文会先谈成员变更在 TiDB 历史,然后介绍新特性的设计,最后说下我们在实现过程中遇到的问题和解决方案。 成员变更 Ti

论文阅读——Efficient and Robust Feature Selection via Joint L2,1-Norms Minimization
一、前言 最近因为对结构化多任务学习,以及对带范数目标函数求解的学习,一直都很想求解带L2,1范数的目标函数(其实这只是个过程),针对这样的不光滑目标函数,梯度下降法并不合适。 虽然sklearn中的MultiTaskLasso也是这样的目标函数,并且使用了坐标下降法来求解,但是当目标函数中的损失函数也用L2,1范数时我又懵圈了。 正当我琢磨是不是能把两部分合在一起求解一个L2,1范数时(其
Box2d)box2dweb之关节joint(连接器)
box2dweb非常重要的一个概念,关节(joint)也有叫连接器的,总之是一个意思。下面是关节详细的类库说明: BOX2D.Dynamics.Joints>>>动态关节包; b2DistanceJoint 距离连接 b2DistanceJointDef 距离连接定义. b2GearJoint 齿轮链接. b2GearJointDef 齿轮连接定义. b2Joint 连接基类. b2Joi
ROS error: Could not find the GUI, install the ‘joint_state_publisher_gui‘ package
ROS melodic运行urdf模型时碰到, [ WARN] [1645792286.082081404]: The 'state_publisher' executable is deprecated. Please use 'robot_state_publisher' instead [WARN] [1645792286.343040]: The 'use_gui' parameter
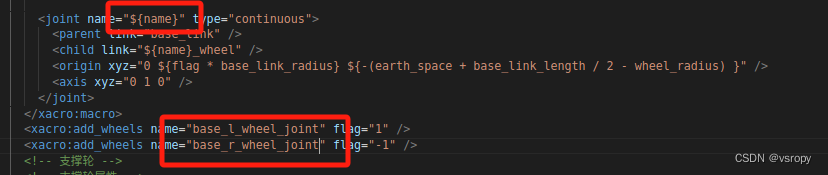
“base_l_wheel_joint“ was received but not found in URDF
运行demo05_car_base.urdf.xacro文件时报错: [ WARN] [1620731067.801481542]: Joint state with name: "base_l_wheel_joint" was received but not found in URDF 原因: 可能要与下载xacro的文件名称一致 解决: 将left和right(一样会
![Failed to build tree: parent link [base_link] of joint [lidar_joint] not found](https://img-blog.csdnimg.cn/direct/61e21c18922341d1a22fc62621053135.png#pic_center)
Failed to build tree: parent link [base_link] of joint [lidar_joint] not found
参考: Failed to build tree: parent link [base_link] of joint 在古月居gazebo 的基础教程里,运行古月居的mbot的launch文件报错,小机器人不出现。 主要原因是提供的xacro文件的宏定义没有放在xacro的命名空间。 解决: 将<mbot_base_gazebo>改为<xacro:mbot_base_gazebo>

Interleaved 3D-CNNs for Joint Segmentation of Small-Volume Structures in Head and Neck CT Images-笔记
传统分割: (1)Atlas based methods, (2)Statistical shape/appearance based methods (3)Classification based methods 论文方法: 1.调整窗宽窗位为[-200,200]。(肉眼可以观察软组织器官) 2.采用MABS method方法粗定位ROIs。使用归一化互信息指导配准。配准包含

JOTS: Joint Online Tracking and Segmentation
来源:CVPR2015 创新点: 提出一种新颖的联合在线跟踪和分割的算法,该算法把多部件跟踪和分割整合到一个统一的能量最优的框架中,目的是处理视频分割的任务。多部件分割可以看成是根据估计的部件模型使用正则化的像素级别的标签分配任务。跟踪可以被表达成基于像素标签,估计部件模型。多部件跟踪和分割被迭代的执行,目的是通过一种ransac-style的方式,最小化提出的函数。 贡献: ①为实现
Joint Tracking and Segmentation of Multiple Targets
来源:CVPR2015 创新点:(本文方法在降低IDs数量的同时,提升了10%的召回率) 在tracking-by-detection的方法中,一个明显的缺点是在图片序列中所获得的大部分信息通过阈值化的微弱的检测响应和非极大值抑制的使用被简单的忽略了。本文提出了一个多目标跟踪器,可以使用低层次的图像信息,把每个(超)像素关联到一个特定的目标或将该(超)像素分类为背景。因此,除了典型的边界框
HDU 5818 Joint Stacks (优先队列、链表)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5818 题意:两个栈,可以对其进行push,pop操作,除此之外还有一个操作 merge A, B,是B中的元素合并到A里,然后B清空,注意此时A内元素的顺序还是按照原来初始插入的顺序。让输出每个pop操作的数。 比赛时是用左偏树过的,代码当然是丑陋不堪。后来发现用优先队列进行一个小优化

Deep Learning Face Representation by Joint Identification-Verification
Deep Learning Face Representation by Joint Identification-Verification 转载请注明:http://blog.csdn.net/stdcoutzyx/article/details/41497545 这篇文章是论文Deep Learning Face Representation by Joint
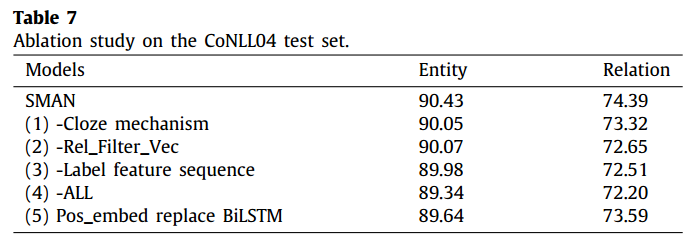
A Span-based Multi-Modal Attention Network for joint entity-relationextraction
原文链接: https://www.sciencedirect.com/science/article/pii/S0950705122013247?via%3Dihub Knowledge-Based Systems 2023 介绍 作者认为当前基于span的关系提取方法都太关注于span内部的语义,忽略了span与span之间以及span与其他模态之间(比如token

Ultraleap 3Di新建项目之给所有的Joint挂载物体
工程文件 Ultraleap 3Di给所有的Joint挂载物体 前期准备 参考上一期文章,进行正确配置 Ultraleap 3Di配置以及在 Unity 中使用 Ultraleap 3Di手部跟踪 新建项目 初始项目如下: 新建Create Empty 将新建的Create Empty,重命名为LeapProvider,并添加新的组件 新添加的组件如下,参数默认,不需要修改 继续
![关于joint_state_publisher出现No transform from [sth] to [sth]的问题](https://img-blog.csdnimg.cn/20200705180112280.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phYmJlcl9KYWdnZXI=,size_16,color_FFFFFF,t_70)
关于joint_state_publisher出现No transform from [sth] to [sth]的问题
问题描述: https://www.cnblogs.com/dayspring/articles/10109260.html "robot_description" 参数定义了urdf文件的路径,它被 robot_state_publisher节点使用。该节点解析urdf文件后将各个frame的状态发布给tf. 因此在rviz里面就看到各个frame(link)之间的tf转换显示OK.否则
[New Paper]A Joint Model for Word Embedding and Word Morphology
大家端午节快乐!本文将分享一篇关于词向量模型最新研究的文章,文章于6月8号提交到arxiv上,题目是A Joint Model for Word Embedding and Word Morphology,作者是来自剑桥大学的博士生Kris Cao。 本文最大的贡献在于第一次将词形联合词向量一同进行训练,从某种程度上解决了未登录词(OOV)的词向量表示问题,同时也得到了一个效果不错的词形分析器
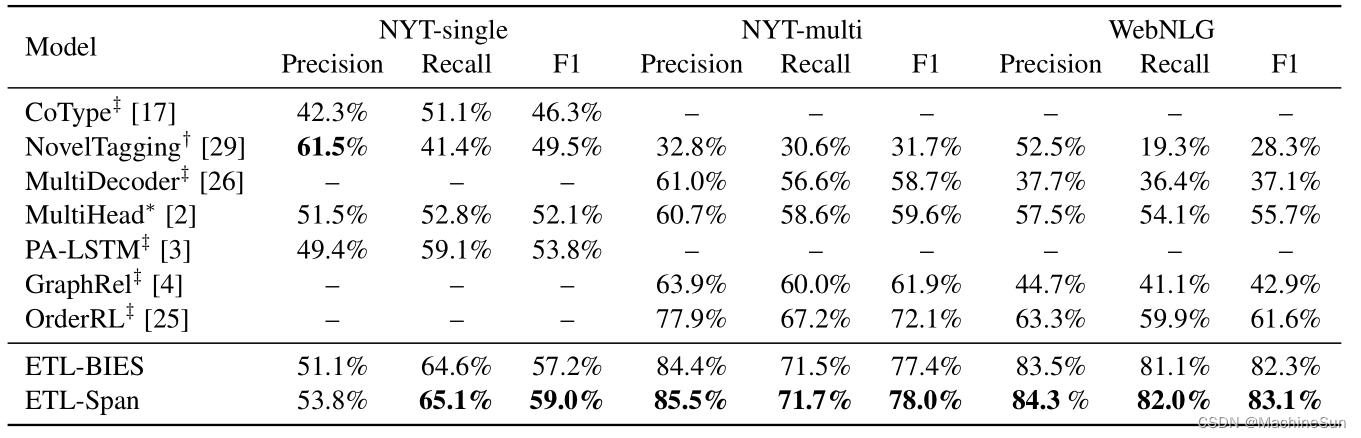
Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy
Abstract 本文将关系抽取任务转换为两个任务,HE抽取(头实体抽取)和TER抽取(尾实体和关系) 前一个子任务是区分所有可能涉及到object关系的头实体,后一个任务是识别每个提取的头实体对应的尾实体和关系,然后基于本文提出的基于span的标记方法将两个子任务进一步分解为多个序列标记任务,采用分层边界标记HBT和多跨度解码算法解决这些问题。本文的第一步不是提取所有实体,而是识别可能参与
关于joint_state_publisher与robot_state_publisher安装
ros2完整版自带robot_state_publisher,但是没有joint_state_publisher安装包,所以如果需要这2个包的话,只需要安装joint_state_publisher就可以了,下载方式:我采用源码安装: sudo git clone -b ros2 https://gitee.com/geniuschinahn/joint_state_publisher.git

论文阅读:Deep Joint Rain Detection and Removal from a Single Image
2017 CVPR:JORDER JORDER: JOint Rain DEtection and Removal 文章主要提出了一种多任务的联合检测和去除的去雨网络。 创新之处: 1、对雨的建模进行改进,增添了一个二值映射,形成了一个区域依赖的雨模型用于提供雨纹位置。同时还对大雨情况下因为雨纹的累积以及不同形状和方向雨纹的重叠形成的大气面纱进行了建模。使得建模更贴近于真实。 2、方法联合了
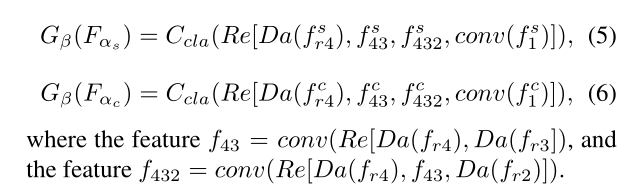
【论文阅读笔记】Uncertainty-aware Joint Salient Object and Camouflaged Object Detectio
【论文阅读笔记】Uncertainty-aware Joint Salient Object and Camouflaged Object Detection 提示:新手小白,单纯做笔记,如有错误还请指出。 原文链接 GitHub链接:https://github.com/JingZhang617/Joint_COD_SOD 文章目录 Author一、Abstract二、Introdu