本文主要是介绍BERT for Joint Intent Classification and Slot Filling 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BERT for Joint Intent Classification and Slot Filling 论文阅读
- Abstract
- 1 Introduction
- 2 Related work
- 3 Proposed Approach
- 3.1 BERT
- 3.2 Joint Intent Classification and Slot Filling
- 3.3 Conditional Random Field
- 4 Experiments and Analysis
- 4.1 Data
- 4.2 Training Details
- 4.3 Results
- 4.4 Ablation Analysis and Case Study
- 5 Conclusion
- 阅读总结
文章信息:

原文链接:https://arxiv.org/abs/1902.10909
源码:https://github.com/monologg/JointBERT
Abstract
意图分类和槽填充是自然语言理解中两个重要的任务。它们通常受制于规模较小的人工标记训练数据,导致泛化能力较差,特别是对于罕见词汇。最近,一种新的语言表示模型BERT(Bidirectional Encoder Representations from Transformers)在大规模未标记语料库上进行了深度双向表示的预训练,通过简单微调后为各种自然语言处理任务创建了最先进的模型。然而,对于自然语言理解,尚未有太多关于探索BERT的努力。在本工作中,我们提出了一种基于BERT的联合意图分类和槽填充模型。实验结果表明,与基于注意力的递归神经网络模型和槽门控模型相比,我们提出的模型在几个公共基准数据集上实现了意图分类准确性、槽填充F1值以及句子级语义框架准确性的显著改进。
1 Introduction

表1:用户查询到语义框架的示例。
近年来,各种智能音箱已经被部署并取得了巨大成功,例如Google Home、Amazon Echo、天猫精灵等,它们促进了目标导向的对话,并通过语音交互帮助用户完成任务。自然语言理解(NLU)对于目标导向的口语对话系统的性能至关重要。NLU通常包括意图分类和槽填充任务,旨在为用户的话语形成语义解析。意图分类专注于预测查询的意图,而槽填充则提取语义概念。表1展示了用户查询“找一部史蒂文·斯皮尔伯格的电影”进行意图分类和槽填充的示例。
意图分类是一个分类问题,它预测意图标签 y i y^i yi,而槽填充是一个序列标注任务,将输入词序列 x = ( x 1 , x 2 , ⋯ , x T ) x=(x_1,x_2,\cdots,x_T) x=(x1,x2,⋯,xT) 标记为槽标签序列 y s = ( y 1 s , y 2 s , ⋯ , y T s ) y^s=(y_{1}^{s},y_{2}^{s},\cdots,y_{T}^{s}) ys=(y1s,y2s,⋯,yTs)。基于循环神经网络(RNN)的方法,尤其是门控循环单元(GRU)和长短期记忆(LSTM)模型,已经在意图分类和槽填充方面取得了最先进的性能。最近,提出了几种用于意图分类和槽填充的联合学习方法,以利用和建模两个任务之间的依赖关系,并改善独立模型的性能(Guo等,2014年; Hakkani-Türet al.,2016年; Liu和Lane,2016年; Goo等,2018年)。先前的工作表明,注意力机制(Bahdanau等,2014年)有助于RNN处理长距离依赖关系。因此,提出了基于注意力的联合学习方法,并在联合意图分类和槽填充方面取得了最先进的性能(Liu和Lane,2016年; Goo等,2018年)。
NLU和其他自然语言处理(NLP)任务中缺乏人工标注数据导致了泛化能力的不足。为了解决数据稀缺的挑战,提出了各种技术用于训练通用语言表示模型,使用大量未标记的文本,例如ELMo(Peters等,2018)和生成式预训练Transformer(GPT)(Radford等,2018)。预训练模型可以在NLP任务上进行微调,并且相对于在特定任务的标注数据上训练,已经取得了显著的改进。最近,提出了一种预训练技术,即双向编码器表示的转换器(BERT)(Devlin等,2018),并且已经为各种NLP任务(包括问答(SQuAD v1.1)、自然语言推理等)创建了最先进的模型。
然而,关于探索BERT用于NLU方面的努力并不多。本工作的技术贡献有两个方面:
1)我们探索了BERT预训练模型以解决NLU的泛化能力不足问题;
2)我们提出了基于BERT的联合意图分类和槽填充模型,并且证明了与基于注意力的RNN模型和槽门控模型相比,所提出的模型在几个公共基准数据集上的意图分类准确性、槽填充F1分数以及句级语义框架准确性上均取得了显著的改进。
2 Related work
深度学习模型在自然语言理解领域得到了广泛的探索。根据意图分类和槽填充是否分别建模,我们将NLU模型分为独立建模方法和联合建模方法两类。
意图分类的方法包括CNN(Kim,2014; Zhang等,2015)、LSTM(Ravuri和Stolcke,2015)、基于注意力的CNN(Zhao和Wu,2016)、分层注意力网络(Yang等,2016)、对抗多任务学习(Liu等,2017)等。槽填充的方法包括CNN(Vu,2016)、深度LSTM(Yao等,2014)、RNNEM(Peng等,2015)、编码器-标签器深度LSTM(Kurata等,2016)以及联合指针和注意力(Zhao和Feng,2018),等等。
联合建模方法包括CNNCRF(Xu和Sarikaya,2013)、RecNN(Guo等,2014)、联合RNN-LSTM(Hakkani-Tur等,2016)、基于注意力的BiRNN(Liu和Lane,2016)和基于槽门的注意力模型(Goo等,2018)。
3 Proposed Approach
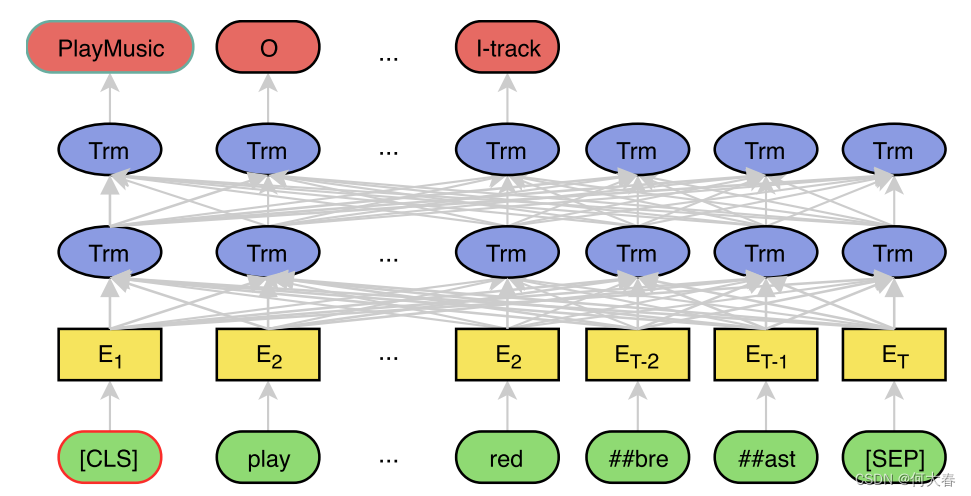
图1:所提出模型的高级视图。输入查询是“play the song little robin redbreast”。
3.1 BERT
输入表示是WordPiece嵌入(Wu等人,2016)、位置嵌入和段嵌入的串联。特别地,对于单句分类和标记任务,段嵌入没有区别。一个特殊的分类嵌入([CLS])被插入为第一个标记,一个特殊的标记([SEP])被添加为最后一个标记。给定一个输入标记序列 x = ( x 1 , … , x T ) x=(x_1,\ldots,x_T) x=(x1,…,xT),BERT的输出是 H = ( h 1 , … , h T ) \mathbf{H}=(\boldsymbol{h}_1,\ldots,\boldsymbol{h}_T) H=(h1,…,hT)。
3.2 Joint Intent Classification and Slot Filling
BERT 可以很容易地扩展为一个联合意图分类和槽填充模型。根据第一个特殊标记([CLS])的隐藏状态,记为 h 1 h_1 h1,可以预测意图为:
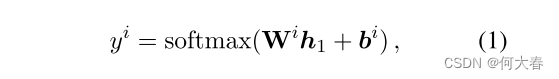
对于槽填充,我们将其他标记的最终隐藏状态 h 2 , … , h T \boldsymbol{h}_2,\ldots,\boldsymbol{h}_T h2,…,hT 输入到一个 softmax 层中,以对槽填充标签进行分类。为了使这个过程与 WordPiece 分词兼容,我们将每个标记化的输入词输入到一个 WordPiece 分词器中,并使用对应于第一个子标记的隐藏状态作为 softmax 分类器的输入。
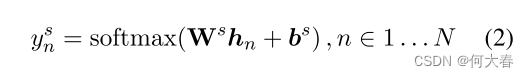
其中, h n 是与单词 x n 的第一个子标记对应的隐藏状态。 \begin{aligned}&\mathrm{其中,}\boldsymbol{h}_n\text{ 是与单词 }x_n\text{ 的第一个子标记对应的隐藏状态。}\end{aligned} 其中,hn 是与单词 xn 的第一个子标记对应的隐藏状态。
同时建模意图分类和槽填充,其目标被形式化为:
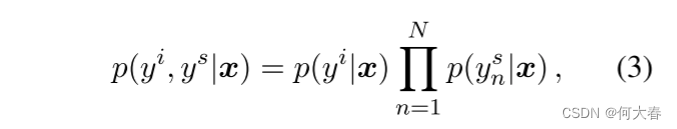
学习目标是最大化条件概率 p ( y i , y s ∣ x ) p(y^i,y^s|x) p(yi,ys∣x)。通过最小化交叉熵损失 l o s s loss loss来端到端地微调模型。
3.3 Conditional Random Field
槽标签的预测依赖于周围单词的预测。已经证明结构化预测模型可以提高槽填充性能,例如条件随机场(CRF)。Zhou和Xu(2015)通过为BiLSTM编码器添加CRF层来改进语义角色标注。在这里,我们调查了在联合BERT模型之上添加CRF来建模槽标签依赖性的效果。
4 Experiments and Analysis
我们在两个公开基准数据集ATIS和Snips上评估了提出的模型。
4.1 Data
ATIS数据集(Tür等,2010年)在NLU研究中被广泛使用,其中包括人们进行航班预订的音频录音。我们对这两个数据集使用了与Goo等人(2018年)相同的数据划分。训练、开发和测试集分别包含4,478、500和893个话语。训练集共有120个槽标签和21个意图类型。我们还使用了Snips数据集(Coucke等人,2018年),该数据集收集自Snips个人语音助手。训练、开发和测试集分别包含13,084、700和700个话语。训练集共有72个槽标签和7个意图类型。
4.2 Training Details
我们使用英文的uncased BERT-Base模型,它具有12层、768个隐藏状态和12个注意头。BERT是在BooksCorpus(800M字)和英文维基百科(2,500M字)上进行预训练的。对于微调,所有超参数都在开发集上进行调优。最大长度为50。批量大小为128。使用Adam进行优化,初始学习率为5e-5。丢失概率为0.1。最大迭代次数从[1, 5, 10, 20, 30, 40]中选择。
4.3 Results
表2显示了在Snips和ATIS数据集上的模型性能,包括slot填充F1分数、意图分类准确率和句子级语义框架准确率。
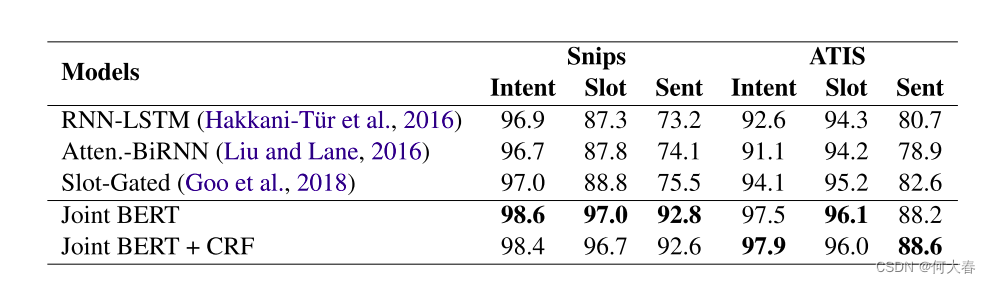
表2:Snips和ATIS数据集上的NLU性能。指标包括意图分类准确率、槽填充F1值和句子级语义框架准确率(%)。第一组模型的结果引自Goo等人(2018年)的研究。
第一组模型是基线模型,由最先进的联合意图分类和槽填充模型组成:使用BiLSTM的基于序列的联合模型(Hakkani-T¨ur等,2016)、基于注意力的模型(Liu and Lane,2016)和槽门控模型(Goo等,2018)。
第二组模型包括提出的联合BERT模型。从表2中可以看出,联合BERT模型在两个数据集上明显优于基线模型。在Snips数据集上,联合BERT的意图分类准确率达到了98.6%(从97.0%)、槽填充F1值达到了97.0%(从88.8%),句级语义框架准确率达到了92.8%(从75.5%)。在ATIS数据集上,联合BERT的意图分类准确率达到了97.5%(从94.1%)、槽填充F1值达到了96.1%(从95.2%),句级语义框架准确率达到了88.2%(从82.6%)。联合BERT+CRF将softmax分类器替换为CRF,其性能与BERT相当,可能是由于Transformer中的自注意机制已足够地对标签结构进行建模。
与ATIS相比,Snips包含多个领域并且具有更大的词汇量。对于更复杂的Snips数据集,联合BERT在句级语义框架准确率方面取得了巨大的提升,从75.5%提高到了92.8%(相对增加了22.9%)。这表明了联合BERT模型具有强大的泛化能力,考虑到它是在来自不同领域和类型(书籍和维基百科)的大规模文本上进行预训练的。在ATIS上,联合BERT在句级语义框架准确率方面也取得了显著的提升,从82.6%提高到了88.2%(相对增加了6.8%)。
4.4 Ablation Analysis and Case Study
我们在Snips数据集上进行了消融分析,如表3所示。如果没有联合学习,意图分类的准确率会降低到98.0%(从98.6%),而槽填充的F1值会降低到95.8%(从97.0%)。我们还比较了使用不同微调时期的联合BERT模型。仅经过1个时期的微调的联合BERT模型已经优于表2中第一组模型。
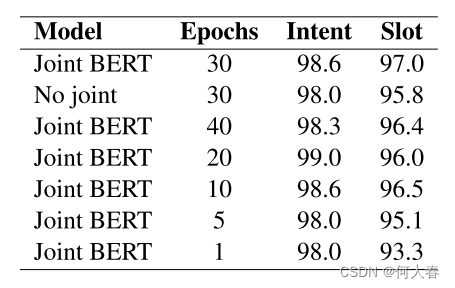
表3:Snips数据集的消融分析。
我们进一步从Snips中选择了一个案例,如表4所示,展示了联合BERT如何通过利用BERT的语言表示能力来提高泛化能力,从而优于槽门模型(Goo等人,2018)。在这种情况下,“mother joan of the angels”被槽门模型错误地预测为一个对象名称,并且意图也是错误的。然而,联合BERT正确地预测了槽标签和意图,因为“mother joan of the angels”是维基百科中的一个电影条目。BERT模型部分在维基百科上进行了预训练,并可能学习到了这个罕见短语的信息。

表4:Snips数据集中的一个案例。
5 Conclusion
我们提出了一种基于BERT的联合意图分类和槽填充模型,旨在解决传统NLU模型泛化能力差的问题。实验结果表明,我们提出的联合BERT模型优于单独建模意图分类和槽填充的BERT模型,显示了利用两个任务之间关系的有效性。我们提出的联合BERT模型在ATIS和Snips数据集上的意图分类准确率、槽填充F1和句子级语义框架准确率上显著优于先前的最先进模型。未来的工作包括在其他大规模和更复杂的NLU数据集上评估所提出的方法,并探索将外部知识与BERT结合的有效性。
阅读总结
简单来说就是使用BERT将意图分类和槽填充任务一起训练了
这篇关于BERT for Joint Intent Classification and Slot Filling 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)