本文主要是介绍【论文阅读笔记】Uncertainty-aware Joint Salient Object and Camouflaged Object Detectio,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【论文阅读笔记】Uncertainty-aware Joint Salient Object and Camouflaged Object Detection
提示:新手小白,单纯做笔记,如有错误还请指出。
原文链接
GitHub链接:https://github.com/JingZhang617/Joint_COD_SOD
文章目录
- Author
- 一、Abstract
- 二、Introduce
- 1.数据扩充
- 2.
- 三、Related Work
- 1.Salient Object Detection Models
- 2.Camouflaged Object Detection Models
- 3.Multi-task Learning
- 4.Adversarial Learning
- 四、Method
- 1.Data augmentation
- 2.Contradicting modeling
- (1)Feature Encoder
- (2)Similarity Measure
- 3.Uncertainty-aware adversarial learning
- (1)Prediction decoder
- (2)Feature Encoder
- (3)Feature Encoder
- 五、Experimental
- 六、Code
- Conclusion
Author

提示:以下是网上找到的作者的一些信息,可供参考。
Aixuan Li:西北工业大学,研究成果
Jing Zhang:澳大利亚国立大学&&澳大利亚联邦科学与工业研究组织 ,研究成果
Yunqiu Lv:西北工业大学,研究成果
Bowen Liu:西北工业大学,研究成果
Tong Zhang:瑞士洛桑联邦理工学院,研究成果
Tong Zhang:瑞士洛桑联邦理工学院,研究成果
Yuchao Dai(戴玉超):西北工业大学,研究成果,个人介绍,添加链接描述
一、Abstract
根据视觉显著性物体检测与伪装性物体检测任务的相互对立与学习展开,提出了基于不确定性感知的显著性物体检测和伪装物体检测的联合学习网络,建模网络预测的置信度,并通过深入挖掘两任务间的相关性,利用显著性物体和伪装物体的矛盾对立属性,使相互对立的显著性物体检测与伪装物体检测任务相互帮助。
显著目标检测(SOD)目的是发现吸引人注意的明显的目标,伪装目标检测(COD)目的是发现藏在背景中的伪装的目标。
本文提出了一种通过矛盾信息增强显著目标检测和伪装目标检测的检测能力。
首先把COD 的简单正样本,作为SOD的hard 正样本,增强了SOD的鲁棒性。
其次,引入“相似性度量”来明确矛盾属性。
另外,COD和SOD的数据标注不确定性,提出敌对学习网络来实现高阶相似性度量和网络置信度估计。
二、Introduce
1.数据扩充

在显著目标和伪装目标过渡中,也存在中间的目标,同时属于两者,比如北极熊。
现在的显著目标检测主要关注网络结构和损失函数。但是除了这两者之外,有效的训练数据集会带来性能的提升。
有效的数据集:扩充数据集
把中间的(类似北极熊)低对比度的目标加入到显著目标数据集,设计一个学习网络来实现 easy samples from COD (e.g. the polar bear) as hard samples for SOD,提高对比度。
2.
三、Related Work
1.Salient Object Detection Models
2.Camouflaged Object Detection Models
3.Multi-task Learning
4.Adversarial Learning
四、Method
1.Data augmentation
首先介绍了一种数据扩充:COD中的简单样本作为SOD中困难样本。从COD中选择样本,用训练好的SOD技术安MAE,选择值最小的样本。选择COD中MAE(平均绝对误差)最小的400张图片随即代替SOD中的样本。
2.Contradicting modeling
其次,提出“相似性度量”模块然后显式地建模两个任务(SOD和COD)的“矛盾”属性。

Dc:COD dataset;
Ds:SOD dataset
i:图像索引
X,Y:图像和GT对
Nc,Ns:伪装训练集和显著训练集的大小

Dp:PASCAL VOC 2007数据集作为连接建模数据集,从中提取显著特征和伪装特征
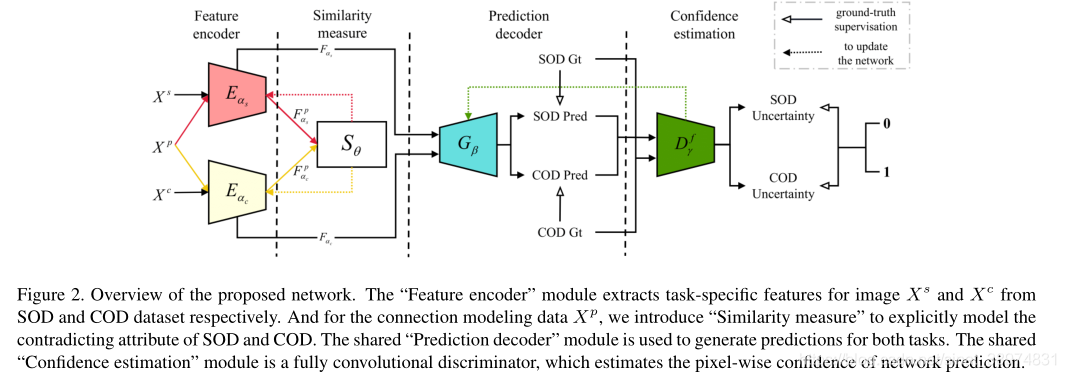
(1)Feature Encoder
特征编码器用来提取特征。Dc和Ds作为输入
显著性编码器Eαs和伪装编码器Eαc。α表示参数。使用ResNet50作为编码器的backbone,四组卷积层,通道为[256, 512, 1024, 2048]。其输出特征用F={f1,f2,f3,f4}表示。

group:相同空间大小
(2)Similarity Measure
Dp作为输入,提取出特征图,然后把特征逐通道连接,反馈到相同的全连接层去获取潜在显著特征和潜在伪装特征,潜在空间维度设为K=700

相似性度量来将COD和SOD任务与Dp连接起来。
假设两个任务激活的区域不同,导致潜在特征彼此分离。然后选择cos相似度来度量潜在空间中的显著特征和伪装特征之间的差异,把潜在空间损失定义为:
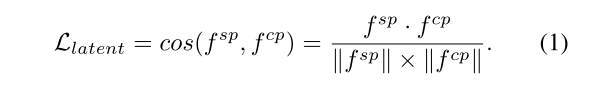

给显著编码器和伪装编码器相同的图像,计算显著图和伪装图,并用红色突出前景,可以看出两者激活区域不同,显著编码器更关注从上下文突出的区域,而伪装编码器关注和背景颜色或结构相似的隐藏对象。这和我们假设一致。
3.Uncertainty-aware adversarial learning
最后是基于不确定性感知的对抗训练网络,在测试过程中产生可解释的预测,在训练过程中实现更高阶的相似性度量。

SOD中的不确定性来在于显著性的模糊性,比如a中的球是突出的,但在b中是背景。COD的不确定性是标注不精确,c中的橙色区域和背景太相似了,不好标注。
为此,我们引入了一种不确定性感知的对抗性训练策略,在我们的联合学习框架中对特定任务的不确定性进行建模,该框架包括一个“预测解码器”模块来产生与任务相关的预测,一个“置信度估计”模块来估计每个预测的不确定性,以及一个用于鲁棒模型训练的对抗性学习策略。
(1)Prediction decoder
预测解码器
设计一个共享解码结构,他们认为不同的特征解码模型能
为COD和SOD图产生特定任务的特征。然后"预测解码"模型的目的是特定任务特征与他们相对应的低水平特征结合产生预测结果。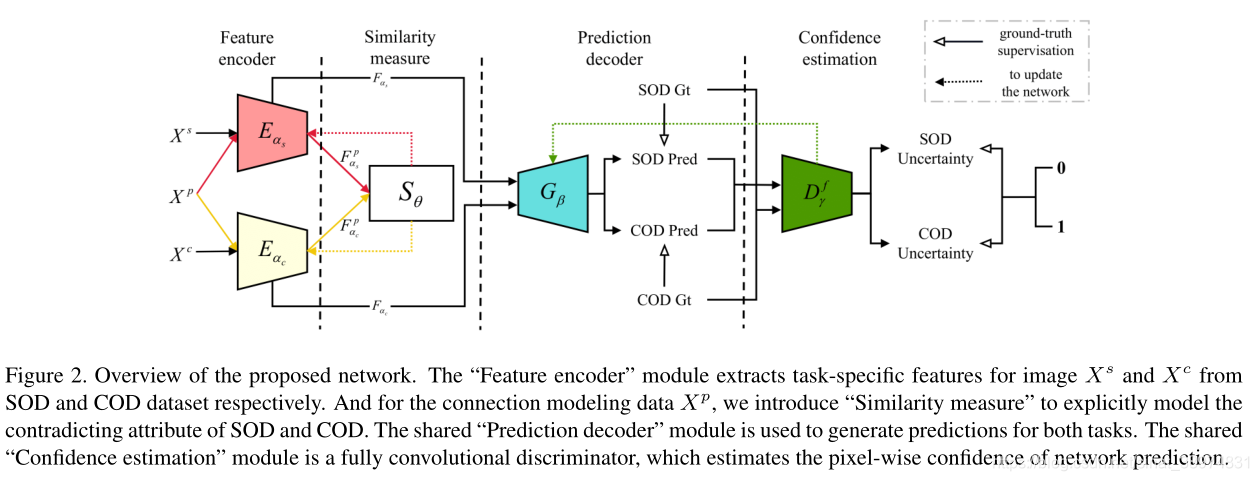
设计了一个自上而下的连接网络
Re:residual channel atten-
tion module,(剩余通道注意模块)提取更好的特征。
Da:dual attention module(双重注意模块)将较高层的语义信息和较低层的结构信息融合,来获取初预测。
conv是33的卷积,输出通道为23
[]逐通道拼接,拼接前上采样至相同空间
Ccla:33的卷积,为每一个任务将特征映射到通道预测。

R3和R4是ResNet50的第三阶段和第四阶段。

最终的预测解码器结构。
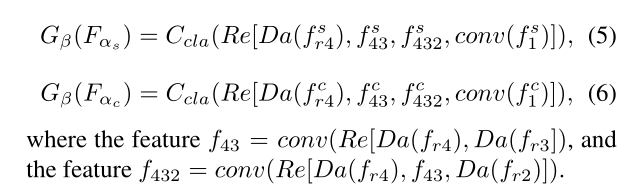
(2)Feature Encoder
(3)Feature Encoder
五、Experimental
六、Code
此论文的代码是公开的,将发布到
https://github.com/JingZhang617/Joint_COD_SOD
实验细节也在上边,代码将在不久之后发布,目前还没有!
Conclusion
这篇关于【论文阅读笔记】Uncertainty-aware Joint Salient Object and Camouflaged Object Detectio的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






