本文主要是介绍【文献阅读与想法笔记13】Pre-Trained Image Processing Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
任务目标
low-level computer vision task
- denoising(30,50)
- super-resolution(X2,X3,X4)
- deraining
贡献与创新(个人认为有价值的部分)
-
IPT模型采用多头多尾共享的变压器体,用于图像超分辨率和去噪等不同的图像处理任务。
-
为了最大限度地挖掘Transformer结构在各种任务上的性能,探索了一个合成的ImageNet数据集。
-
对比学习的加入稳定、提升Transformer
-
实现较为完整的可复用的预训练模型和训练策略(单数据集预训练支持多任务(预训练有可能为图像处理任务提供一个有吸引力的解决方案)
实现这些贡献的价值
- 优势一:特定任务的数据可能是有限的。可以应用在涉及付费数据或数据隐私的图像处理的任务中,如医学图像和卫星图像。
Pre-training has the potential to provide an attractive solution to image processing tasks by addressing the following two challenges: First, task-specific data can be limited. such as medical images and satellite images.
- 优势二:各种不一致的因素(如摄像机参数、光照、天气等)会进一步干扰采集到的训练数据的分布。其次,它是未知的类型的图像处理工作将被要求,直到测试图像出现。因此,我们必须准备一系列的图像处理模块在手。他们有不同的目标,但一些基本操作可以共享。
Various inconsistent factors (e.g. camera parameter, illumination and weather) can further perturb the distribution of the captured data for training. Second, it is unknown which type of image processing job will be requested until the test image is presented. We therefore have to prepare a series of image processing modules at hand. They have distinct aims, but some underlying operations could be shared.
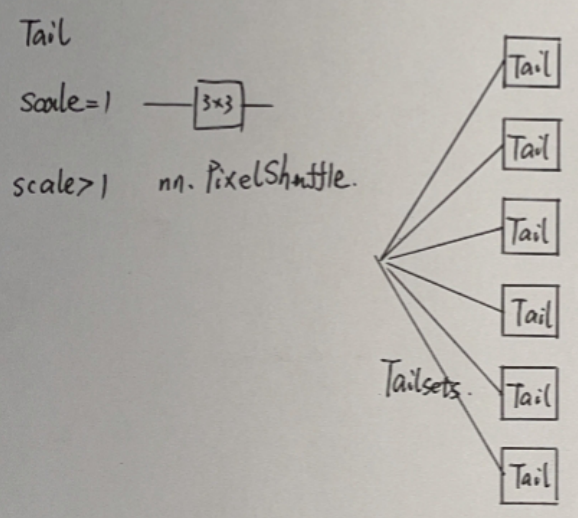
网络结构说明
训练图像被输入到特定的头部,生成的特征被裁剪成小块(即“单词”),并随后被平摊成序列。利用变压器本体处理扁平特征,其中位置嵌入和任务嵌入分别用于编码器和解码器。
The training images are input to the specific head, and the generated features are cropped into patches (i.e., “words”) and flattened to sequences subsequently. The transformer body is employed to process the flattened features in which position and task embedding are utilized for encoder and decoder, respectively.
image processing transformer (IPT)
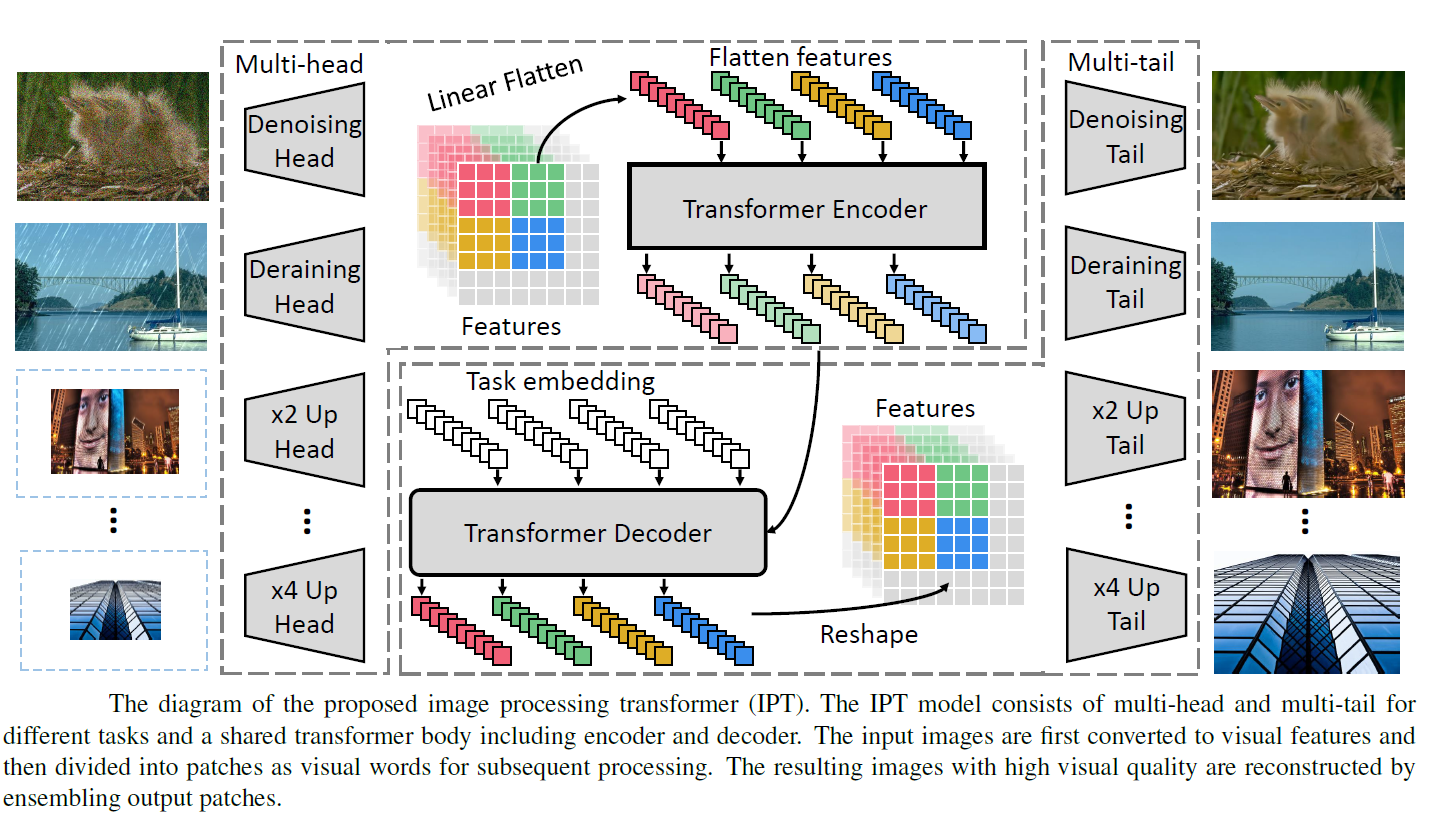
- 结构一
heads for extracting features from the input corrupted images (e.g., images with noise and low-resolution images)
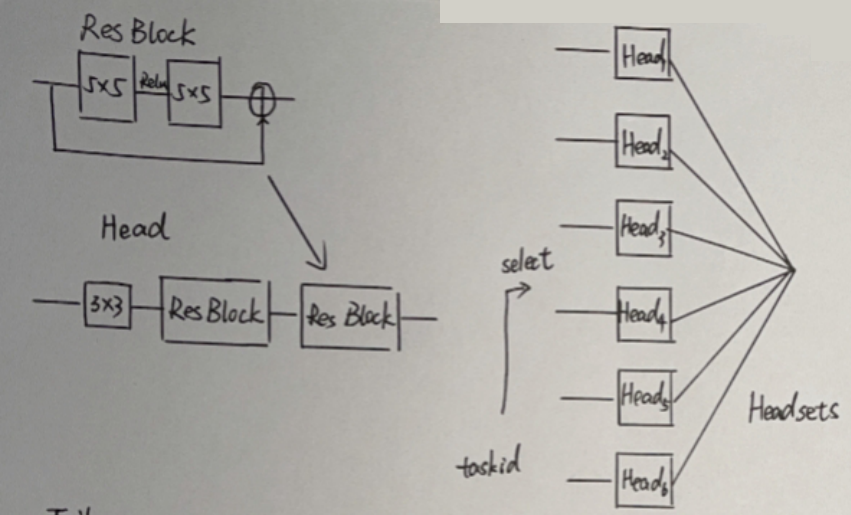
- 结构二,结构三
an encoder-decoder transformer is established for recovering the missing information in input data
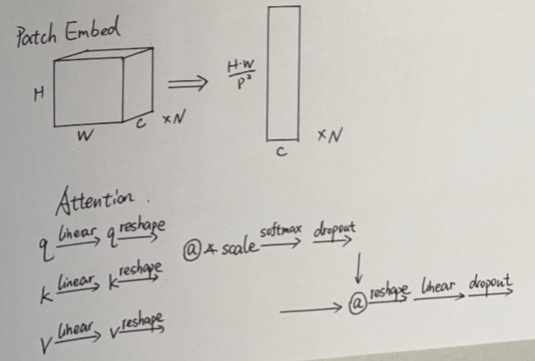
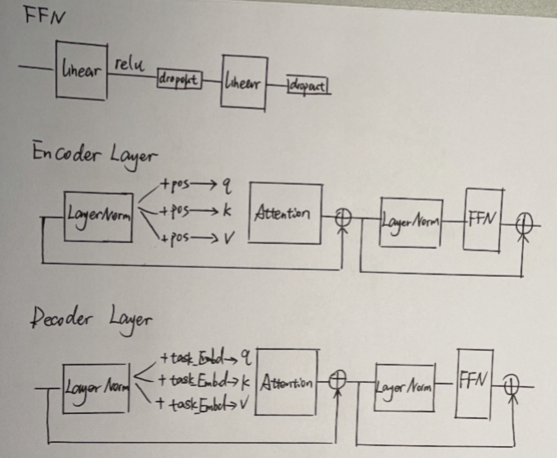
- 结构四
tails are used for mapping the features into restored images
训练细节
Imagenet预训练
数据集的制作
we present to utilize the well-known ImageNet benchmark for generating a large amount of corrupted image pairs.
ImageNet 1M的高多样性彩色图像组成
10M 48×48patches(overlap10)
2X、3X、4Xbicubic插值、30、50噪声级高斯噪声和添加雨点等6种
CNN模型也采用了相同的测试策略,得到的CNN模型的PSNR值与它们的基线相同。
设备平台
32张Nvidia Nvidia Tesla V100
优化设置
Adam优化器,β1= 0.9, β2= 0.999
300个epoch的训练。0-200 学习率设置为5e−5,200-300到2e−5
Batchsize= 256
300e随机结束后,30个e的微调5e−5
loss

- 第一部分:L1范数部分
随机选择一个task进行训练,每个task同时使用相应的head, tail和task embedding进行处理。
每一个头,尾,Encoder,Decoder都会被训练到
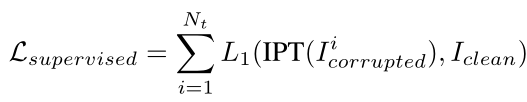
- 第二部分:对比学习部分
需要进一步提高所得IPT的泛化能力。与训练前的自然语言处理模型相似,图像中的小块之间的关系也很有用。图像场景中的补丁可以看作是自然语言处理中的一个词。例如,从相同的特征图上裁剪出来的补丁更有可能一起出现,它们应该嵌入到相似的位置。
目标是使相同图像上的补丁特征之间的距离最小,同时使不同图像上的补丁之间的距离最大。
x j x_j xj是一个batch中的一个图片 x j ∈ X , X = { x 1 , x 2 , ⋯ x B } x_j\in X,X = \{x_1,x_2,\cdots x_B\} xj∈X,X={x1,x2,⋯xB}
x j x_j xj解码输出的特征图 f D i j ∈ R P 2 × C , i = { 1 , … , N } f_{D_{i}}^{j} \in \mathbb{R}^{P^{2} \times C}, i=\{1, \ldots, N\} fDij∈RP2×C,i={1,…,N}
余弦相似性 d ( a , b ) = a T b ∥ a ∥ ∥ b ∥ d(a, b)=\frac{a^{T} b}{\|a\|\|b\|} d(a,b)=∥a∥∥b∥aTb
D i D_i Di表示不同的解码器的输出共有 N N N个解码器
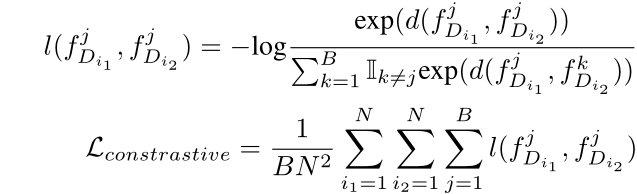

训练细节
对于每批任务,我们N_t$ task中随机选择一个task进行训练,每个task同时使用相应的head, tail和task embedding进行处理。在对IPT模型进行预训练后,它将捕获大量图像处理任务的内在特征和转换,从而可以进一步微调,使用新提供的数据集应用于所需的任务。另外,为了节省计算成本,将其他头像和尾巴丢弃,并根据反向传播更新剩余头像、尾巴和身体中的参数。
测试与性能
测试数据集
Rain100L dataset [79]
Urban100
测试细节
- The result images are converted into
YCbCrcolor space. The PSNR is evaluated on theYchannel only.
测试结论
参数与计算量
整个IPT有114m parameters和33gflops,与传统的CNN模型相比(例如EDSR有43m parameters和99gflops)有更多的参数而更少的FLOPs。
总体表现
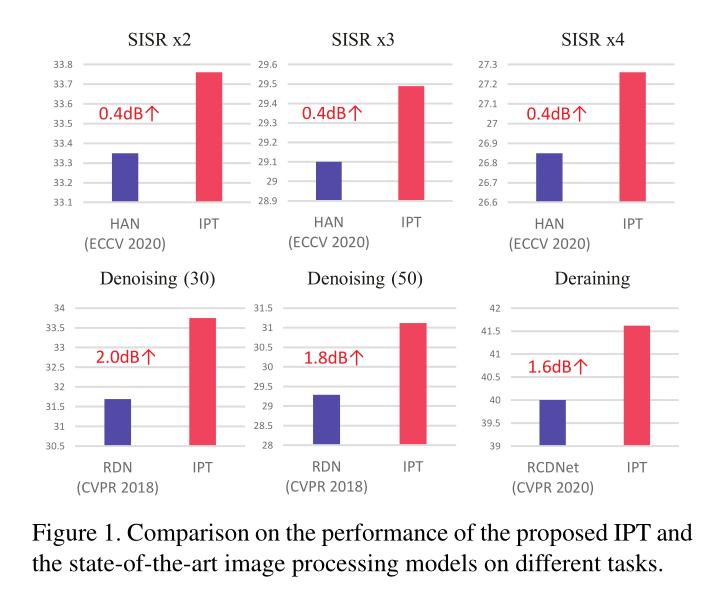
超分表现
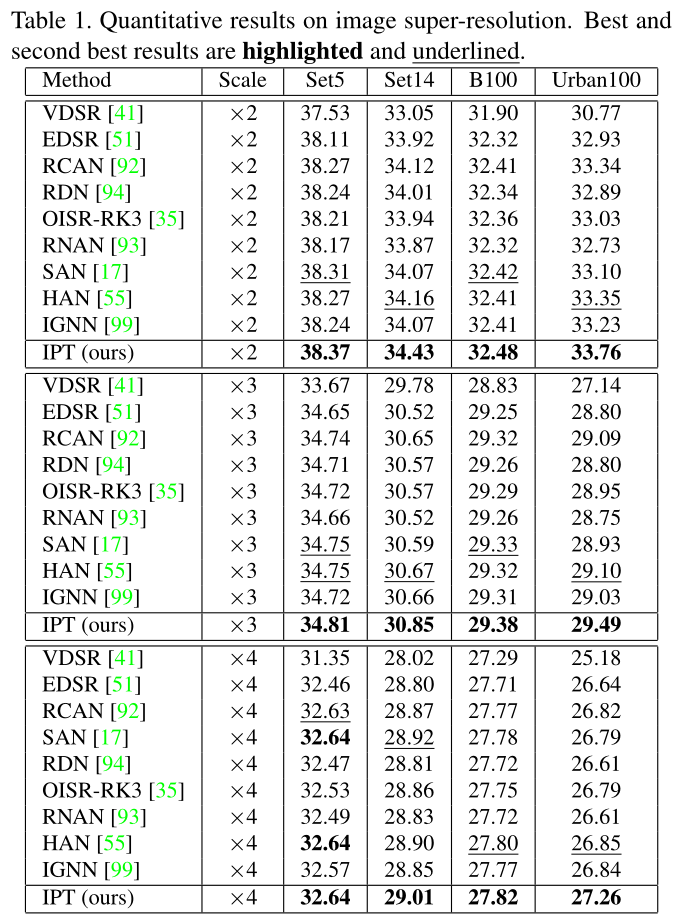
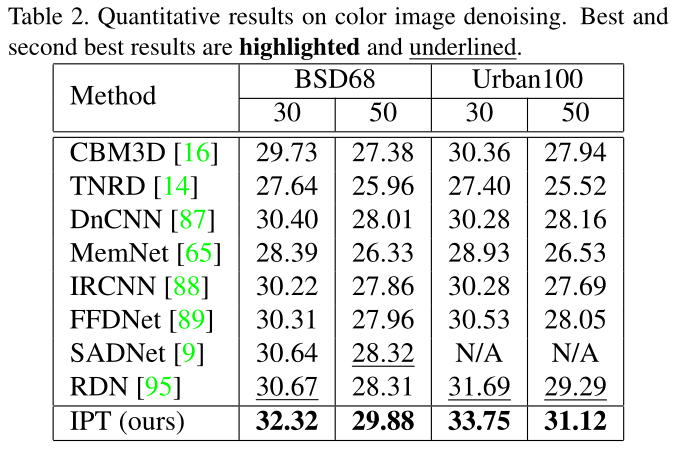
去噪表现
去雨表现

消融实验与泛化性
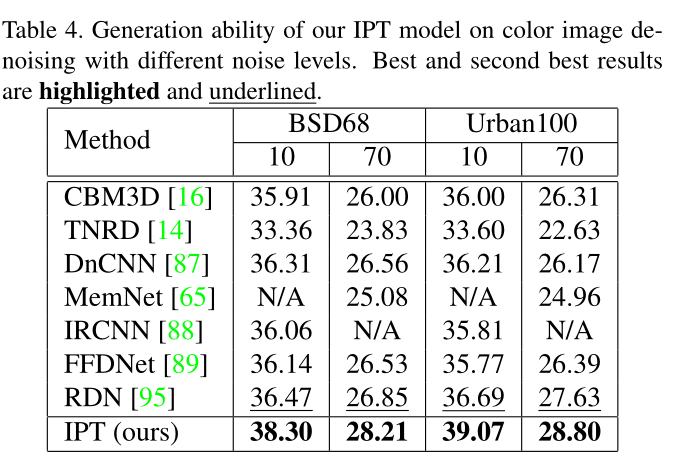
有价值的实验 去噪训练3050 测试10 70 (泛化性能表现)
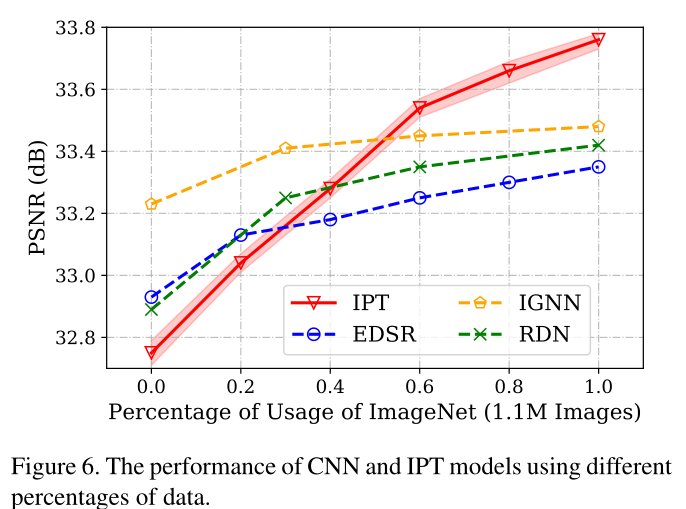
数据集选择性实验(实用价值)
当模型未进行预训练或使用整个数据集的少量(< 60%)进行预训练时,CNN模型取得了较好的性能。相比之下,在使用大规模数据时,基于转换器的模型优于CNN模型,这证明了IPT模型对预训练的有效性。
对比学习消融实验

附录
去模糊实验
GoPro dataset [54]

Embeddings实验
自动 固定 无 (自动最优)不同任务的差异在0.2 ~ 0.3dB
可视化
任务嵌入可视化 分析训练完毕后的嵌入部分网络参数可视化和任务的相关性
代码开源
pytorch gpu版本
huawei-noah/Pretrained-IPT
mindspore npu版本
mindspore: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios. - Gitee.com
个人评价
-
need pre-trained = 不能判断是在大数据及预训练所带来的性能提升还是网络结构所带来的提升
-
ViT的使用和调整
-
1000万张图片的数据量,patch处理后更大,再加之需要做六种不同的退化
-
输入像素在像素尺寸上固定
-
T的问题是否会出现于flatten
要参考的其它文献
SRCNN [20,21]
Ahnet al. [2] and Limet al. [50] propose introduce residual block into SR task. Zhanget al. [92] and Anwar and Barnes [3] utilize the power of attention to enhance the performance on SR task. A various excellent works are also proposed for the other tasks, such as denoising [68,32,37,45,24], dehazing [6,46,85,80], deraining [36,78,62,29,74,47], and debluring [67,53,23,10].
【26】Jun Fu, Jing Liu, Haijie Tian, Y ong Li, Y ongjun Bao, Zhi-wei Fang, and Hanqing Lu. Dual attention network forscene segmentation. InProceedings of the IEEE Confer-ence on Computer Vision and Pattern Recognition, pages3146–3154, 2019.3
Wanget al. [75], Chenet al. [15], Jiangetal. [38] and Zhanget al. [91] also augment features by self-attention to enhance model performance on several high-level vision tasks.
[31,1] 提供退化方式:,超分辨率任务通常采用双三次退化来生成低分辨率图像,去噪任务在不同噪声水平的干净图像中加入高斯噪声来生成噪声图像
[79] 加雨
这篇关于【文献阅读与想法笔记13】Pre-Trained Image Processing Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








