tuning专题

Google Research 推出高效的Prompt Tuning方法
人工智能咨询培训老师叶梓 转载标明出处 一般模型微调方法需要对预训练模型的所有参数进行调整,这在大规模模型中既耗时又耗资源。Google Research的研究团队提出了一种名为“Prompt Tuning”的方法,旨在通过学习“软提示”来调整冻结的语言模型,使其能够更好地完成特定的下游任务。这种方法不仅简单有效,而且在模型规模增大时,其性能逐渐接近全模型微调(Model Tuning)的效果。

《The Power of Scale for Parameter-Efficient Prompt Tuning》论文学习
系列文章目录 文章目录 系列文章目录一、这篇文章主要讲了什么?二、摘要中T5是什么1、2、3、 三、1、2、3、 四、1、2、3、 五、1、2、3、 六、1、2、3、 七、1、2、3、 八、1、2、3、 一、这篇文章主要讲了什么? The article “The Power of Scale for Parameter-Efficient Prompt Tuning

Illustrated Guide to Monitoring and Tuning the Linux Networking Stack: Receiving Data
太长不读(TL; DR) 这篇文章用一系列图表扩展了以前的博客文章Monitoring and Tuning the Linux Networking Stack: Receiving Data,旨在帮助读者形成一个更清晰的视野来了解Linux网络协议栈是如何工作的 在监控或调优 Linux 网络协议栈试没有捷径可走。如果你希望调整或优化每个组件及其相互作用,你就必须努力充分了解它们。也就是说

NLP-预训练模型-2017:ULMFiT(Universal LM Fine-tuning for Text Classification)【使用AWD-LSTM;模型没有创新;使用多个训练小技巧】
迁移学习在计算机视觉有很大的影响,但现在的NLP中的方法仍然需要特定任务的修改和 从头开始的训练。我们提出通用语言模型微调,一种可以应用NLP任何任务中的迁移学习方法。我们模型在分类任务中都表现得良好,并且在小数据集上的表现优异。 一、ULMFiT (Universal Language Model Fine- tuning)组成步骤: a) General-domain LM pretr
oracle面试总结SQL tuning 类,数据库基本概念类,备份恢复类,系统管理类
一:SQL tuning 类 1. 列举几种表连接方式 Answer:等连接(内连接)、非等连接、自连接、外连接(左、右、全) Or hash join/merge join/nest loop(cluster join)/index join ?? ORACLE 8i,9i 表连接方法。 一般的相等连接: select * from a, b where a.i

caffe fine-tuning 图像分类
fine-tuning流程: 1、准备数据集(包括训练、验证、测试); 2、数据转换和数据集的均值文件生成; 3、修改网络输出类别和最后一层的网络名称,加大最后一层参数的学习速率,调整solver的配置参数; 4、加载预训练模型的参数,启动训练; 5、选取图片进行测试。 准备数据集 将图像整理到对应的文件夹中,对应的ground-truth放到对应的txt文件中。把自己的数据集划

一文彻底搞懂Fine-tuning - 预训练和微调(Pre-training vs Fine-tuning)
Pre-training vs Fine-tuning 预训练(Pre-training)是预先在大量数据上训练模型以学习通用特征,而微调(Fine-tuning)是在特定任务的小数据集上微调预训练模型以优化性能。 Pre-training vs Fine-tuning 为什么需要预训练? 预训练是为了让模型在见到特定任务数据之前,先通过学习大量通用数据来捕获广泛有用的特征,从而

GPT微调和嵌入哪个好,大模型微调 和嵌入有什么区别?微调(fine-tuning),嵌入(embedding)的用法!
GPT擅长回答问题,但是只能回答它以前被训练过的问题,如果是没有训练过的数据,比如一些私有数据或者最新的数据该怎么办呢? 这种情况下通常有两种办法,一种是微调(fine-tuning),一种是嵌入(embedding)。 现在基于自然语言和文档进行对话的背后都是使用的基于嵌入的向量搜索。OpenAI在这方面做的很好,它的Cookbook(http://github.com/openai/ope
一文彻底搞懂Fine-tuning - 超参数(Hyperparameter)
Hyperparameter 超参数(Hyperparameter), 是机器学习算法中的调优参数,用于控制模型的学习过程和结构。与模型参数(Model Parameter)不同,模型参数是在训练过程中通过数据学习得到的,而超参数是在训练之前由开发者或实践者直接设定的,并且在训练过程中保持不变。 Hyperparameter vs Model Parameter 超参数是机器学习算法
pytorch 参数冻结 parameter-efficient fine-tuning
目标:在网络中冻结部分参数进行高效训练 框架:pytorch (version 1.11.0) 基本实现: 需要学习的参数requires_grad设置为True,冻结的设置为False需要学习的参数要加到 optimizer的List中;对于冻结的参数,可以直接不加进去,(应该也可以加进去,但是requires_grad=False) 注意事项: 3. 如果不传递参数的层,记得前向操作是

Oracle(84)什么是SQL调优顾问(SQL Tuning Advisor)?
SQL调优顾问(SQL Tuning Advisor)是Oracle数据库中的一个工具,旨在帮助数据库管理员(DBA)和开发人员自动分析SQL语句的性能并提供优化建议。它通过分析SQL语句的执行计划、统计信息和其他相关信息,识别潜在的性能问题,并建议具体的优化措施。 SQL调优顾问的主要功能 自动分析SQL语句:分析指定的SQL语句,识别性能瓶颈。优化建议:提供具体的优化建议,如创建索引、调整
Fine-tuning与 Instruction Tuning
Instruction Tuning是指什么 Instruction Tuning 是一种机器学习技术,特别是在自然语言处理 (NLP) 领域中,用于优化模型的行为,使其能够更好地遵循自然语言指令。它是在预训练和微调之后的一种技术,以进一步提升模型在实际应用中的表现。 现代 NLP 模型通常经历三个阶段: 预训练(Pretraining):模型在大规模未标注的数据上进行训练,学习语言的基本结

大模型Prompt-Tuning技术入门
Prompt-Tuning方法 1 NLP任务四种范式 目前学术界一般将NLP任务的发展分为四个阶段,即NLP四范式: 第一范式:基于「传统机器学习模型」的范式,如TF-IDF特征+朴素贝叶斯等机器算法;第二范式:基于「深度学习模型」的范式,如word2vec特征+LSTM等深度学习算法,相比于第一范式,模型准确有所提高,特征工程的工作也有所减少;第三范式:基于「预训练模型+fine
![LLM微调方法(Efficient-Tuning)六大主流方法:思路讲解优缺点对比[P-tuning、Lora、Prefix tuning等]](https://img-blog.csdnimg.cn/direct/9ddbc0ebbb4c456dbf42c95c066245dd.png)
LLM微调方法(Efficient-Tuning)六大主流方法:思路讲解优缺点对比[P-tuning、Lora、Prefix tuning等]
LLM微调方法(Efficient-Tuning)六大主流方法:思路讲解&优缺点对比[P-tuning、Lora、Prefix tuning等] 由于LLM参数量都是在亿级以上,少则数十亿,多则数千亿。当我们想在用特定领域的数据微调模型时,如果想要full-tuning所有模型参数,看着是不太实际,一来需要相当多的硬件设备(GPU),二来需要相当长的训练时间。因此,我们可以选择一条捷径,不需要微
oracle sql tuning之非常实用的4条sql语句
--[1]查看full sql text SELECTp.sql_fulltext FROM gv$locked_object l, gv$session s, gv$sqlarea p WHERE l.session_id = s.sid and s.sql_id = p.sql_id; --[2]查看表和锁的相关信息 SELECTdistinct s.u

【李宏毅-生成式 AI】Spring 2024, HW5:LLM Fine-tuning 实验记录
文章目录 1. Task Overview2. Overall Workflow3. Dataset 介绍4. 代码介绍4.1 环境介绍4.2 下载 dataset4.3 下载并加载模型4.2 Notebook 代码1)import 部分2)固定 seed3)加载 LLM4)加载 tokenizer5)设置解码参数6)⭐ LLM 和 tokenizer 使用示例7)generate_trai

RAG vs Fine-Tuning 微调哪种大模型(LLM)技术更好?
数据科学和机器学习的研究人员和从业者都在不断探索创新策略来增强语言模型的能力。在众多方法中,出现了两种突出的技术,即检索增强生成 (RAG)和微调。本文旨在探讨模型性能的重要性以及 RAG 和微调策略的比较分析。 模型性能在 NLP 中的重要性 增强用户体验 改进的模型性能可确保 NLP 应用程序能够有效地与用户沟通。这对于聊天机器人、虚拟助手和客户支持系统等应用程序至关重要,因为准确理解用
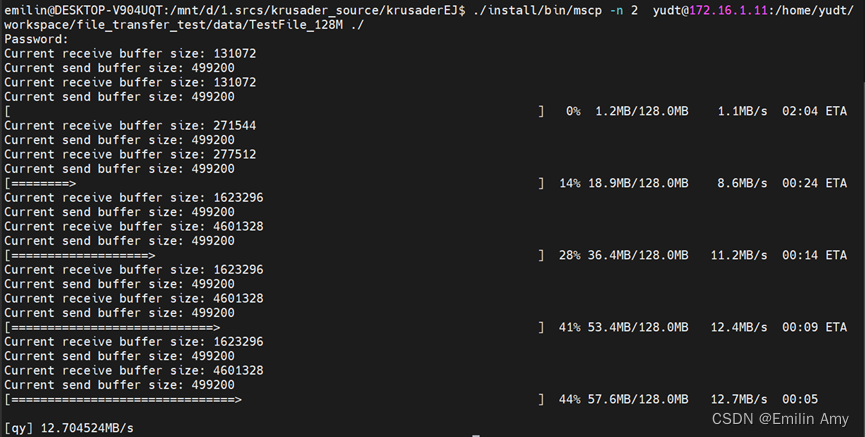
论文研读 Automatic TCP Buffer Tuning
由于“动态右尺寸”(DRS)的方法关于其自动调优方法的介绍并不清楚,改读了论文"Automatic TCP Buffer Tuning"。其中调节接收缓存大小的想法就是,“动态调整接收套接字缓冲区的一个想法是在缓冲区大部分为空时增加缓冲区大小,因为缺少排队等待应用程序传输的数据表明数据速率低,这可能是接收窗口限制连接的结果。在恢复期间达到峰值使用量(由丢失的数据包指示),因此,如果缓冲区大小远大于
Fine-tuning和模型训练的关系
概述 Fine-tuning和模型训练不是完全相同的概念,但它们之间有密切的关系,都是机器学习和深度学习过程中的重要步骤。 模型训练是一个更广泛的概念,指的是使用数据去调整模型的内部参数,以使得模型能够从输入数据中学习并做出预测或决策。这个过程通常包括前向传播(forward pass)、计算损失函数(loss function)、反向传播(backward pass)以及参数更新等步骤。模型

参数高效微调PEFT(二)快速入门P-Tuning、P-Tuning V2
参数高效微调PEFT(二)快速入门P-Tuning、P-Tuning V2 参数高效微调PEFT(一)快速入门BitFit、Prompt Tuning、Prefix Tuning 今天,我们继续了解下来自清华大学发布的两种参数高效微调方法P-Tuning和P-Tuning v2。可以简单的将P-Tuning是认为针对Prompt Tuning的改进,P-Tuning v2认为是针对Prefix

Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(十) 使用 LoRA 微调常见问题答疑
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3
【LLM多模态】综述Visual Instruction Tuning towards General-Purpose Multimodal Model
note 文章目录 note论文1. 论文试图解决什么问题2. 这是否是一个新的问题3. 这篇文章要验证一个什么科学假设4. 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?5. 论文中提到的解决方案之关键是什么?6. 论文中的实验是如何设计的?7. 用于定量评估的数据集是什么?代码有没有开源?8. 论文中的实验及结果有没有很好地支持需要验证的科学假设?9. 这篇论文到底有
![ChatGLM2-6B 模型基于 [P-Tuning v2]的微调](https://img-blog.csdnimg.cn/direct/59b132f34fa64e6d8128bb325732b79a.png)
ChatGLM2-6B 模型基于 [P-Tuning v2]的微调
ChatGLM2-6B-PT 一、介绍 1、本文实现对于 ChatGLM2-6B 模型基于 [P-Tuning v2](https://github.com/THUDM/P-tuning-v2) 的微调 2、运行至少需要 7GB 显存 3、以 [ADGEN](https://aclanthology.org/D19-1321.pdf) (广告生成) 数据集为例介绍代码的使用方法。
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(一) LLaMA-Factory简介
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3
Web agent 学习 2:TextSquare: Scaling up Text-Centric VisualInstruction Tuning
学习论文:TextSquare: Scaling up Text-Centric Visual Instruction Tuning(主要是学习构建数据集) 递归学习了:InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Models(
微调(fine-tuning)和泛化(generalization)
主要讨论两个主要方面:微调(fine-tuning)和泛化(generalization)。 文章目录 微调 Fine-tune泛化 Generalization 微调 Fine-tune 对于微调:选择合理的步骤(也就是迭代轮数或称为epochs),以获得良好的下游任务性能,但同时避免过拟合。微调是指在一个已经在大规模数据上预训练好的模型的基础上,针对特定任务领域的数据进行调