本文主要是介绍ChatGLM2-6B 模型基于 [P-Tuning v2]的微调,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ChatGLM2-6B-PT
一、介绍
1、本文实现对于 ChatGLM2-6B 模型基于 [P-Tuning v2](https://github.com/THUDM/P-tuning-v2) 的微调
2、运行至少需要 7GB 显存
3、以 [ADGEN](https://aclanthology.org/D19-1321.pdf) (广告生成) 数据集为例介绍代码的使用方法。
模型部署参考: MiniCPM-Llama3-V-2_5-int4 部署推理流程
二、开始
1、软件依赖
首先进入你之前的conda环境
conda activate chatglm2 运行微调除 ChatGLM2-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets
2、下载数据集
ADGEN 数据集任务为根据输入(content)生成一段广告词(summary)。
```json
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
```
从 [Google Drive](https://drive.google.com/file/d/13_vf0xRTQsyneRKdD1bZIr93vBGOczrk/view?usp=sharing) 或者 [Tsinghua Cloud](https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1) 下载处理好的 ADGEN 数据集,将解压后的 `AdvertiseGen` 目录放到本目录下。
3、开始训练
P-Tuning v2
运行以下指令进行训练:
bash train.sh运行成功
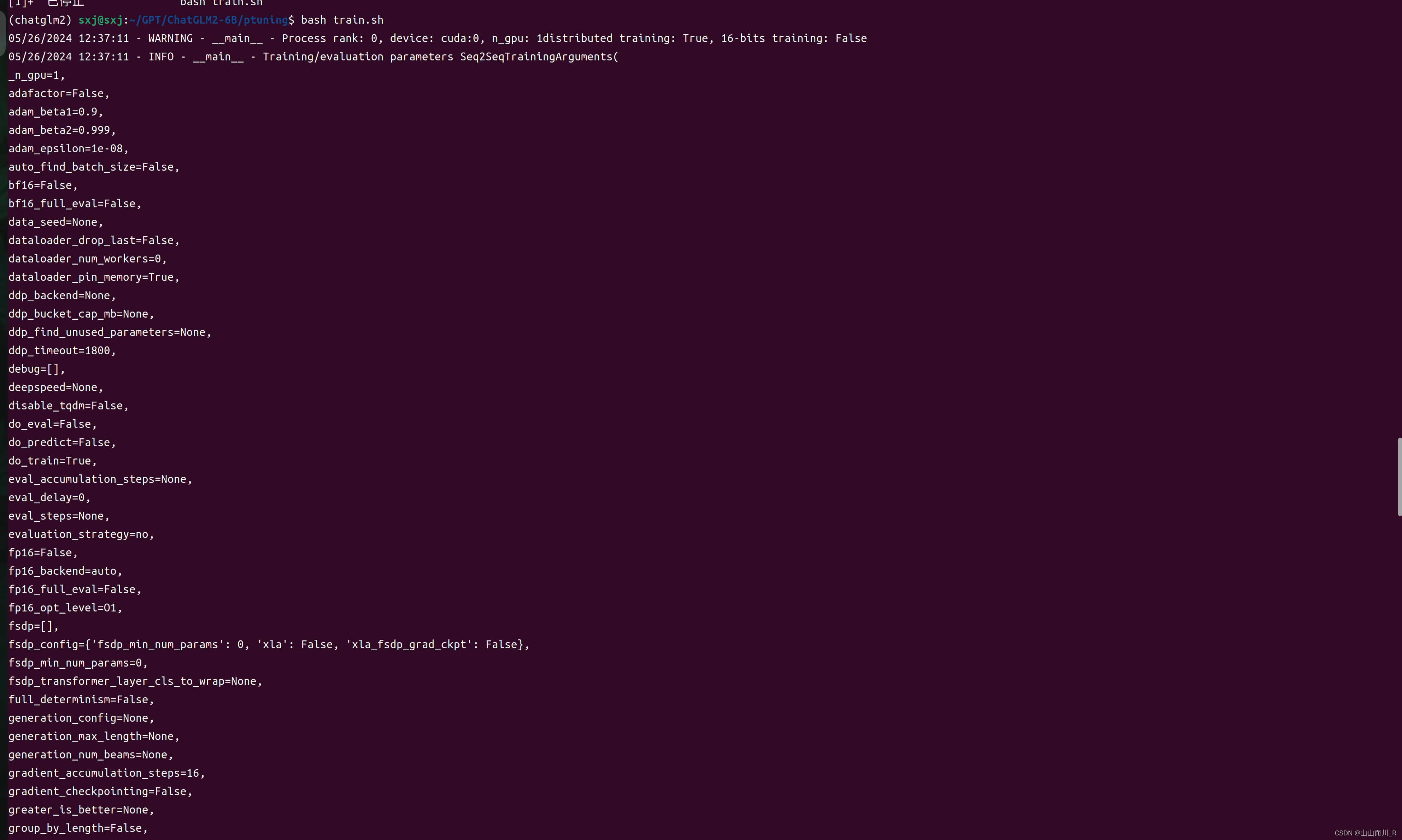
默认训练是3000,我调成300进行测试
解读train.sh:
PRE_SEQ_LEN=128: 这设置了一个序列的长度为128,这通常指的是输入文本的长度或者模型的上下文长度。
LR=2e-2: 这是学习率(Learning Rate)的设置,2e-2表示0.02,是一个常见的学习率初始值。
NUM_GPUS=1: 指定使用的GPU数量,这里设置为1。
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py: 这是启动PyTorch程序的命令,指定了独立运行、1个节点和每个节点的进程数(即GPU数)。
接下来是传递给main.py脚本的参数:--do_train: 表示执行训练过程。
--train_file AdvertiseGen/train.json: 指定训练数据文件,这里是AdvertiseGen/train.json。
--validation_file AdvertiseGen/dev.json: 指定验证数据文件,这里是AdvertiseGen/dev.json。
--preprocessing_num_workers 10: 设置预处理数据时使用的工作进程数为10。
--prompt_column content: 指定数据中作为输入(prompt)的列名,这里是content。
--response_column summary: 指定数据中作为输出(response)的列名,这里是summary。
--overwrite_cache: 如果缓存已存在,覆盖它。
--model_name_or_path THUDM/chatglm2-6b: 指定预训练模型的名称或路径,这里是THUDM/chatglm2-6b,表示使用的是清华大学开发的开源双语对话模型ChatGLM2-6B。
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR: 设置输出目录,会根据预设的序列长度和学习率动态生成。
--overwrite_output_dir: 如果输出目录已存在,覆盖它。
--max_source_length 64: 设置输入文本的最大长度为64。
--max_target_length 128: 设置输出文本的最大长度为128。
--per_device_train_batch_size 1: 设置每个设备上的训练批次大小为1。
--per_device_eval_batch_size 1: 设置每个设备上的评估批次大小为1。
--gradient_accumulation_steps 16: 设置梯度累积的步数为16,这可以在有限的GPU内存下训练更大的批次。
--predict_with_generate: 在评估时使用生成模式。
--max_steps 3000: 设置训练的最大步数为3000。
--logging_steps 10: 设置记录日志的步数为10。
--save_steps 1000: 设置保存模型检查点的步数为1000。
--learning_rate $LR: 设置学习率为之前定义的变量LR的值。
--pre_seq_len $PRE_SEQ_LEN: 设置序列长度为之前定义的变量PRE_SEQ_LEN的值。
--quantization_bit 4: 设置模型量化为4位,这是为了减少模型大小和提高推理速度的一种技术。
`train.sh` 中的 `PRE_SEQ_LEN` 和 `LR`
分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。
P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 `quantization_bit` 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 `quantization_bit=4`
`per_device_train_batch_size=1`
`gradient_accumulation_steps=16`
下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 `per_device_train_batch_size` 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
从本地加载模型,需将 `train.sh` 中的 `THUDM/chatglm2-6b` 改为你本地的模型路径。
#### Finetune
如果需要进行全参数的 Finetune,需要安装 [Deepspeed](https://github.com/microsoft/DeepSpeed),然后运行以下指令:
```shell
bash ds_train_finetune.sh
```
### 推理
在 P-tuning v2 训练时模型只保存 PrefixEncoder 部分的参数,所以在推理时需要同时加载原 ChatGLM2-6B 模型以及 PrefixEncoder 的权重,因此需要指定 `evaluate.sh` 中的参数:
```shell
--model_name_or_path THUDM/chatglm2-6b
--ptuning_checkpoint $CHECKPOINT_PATH
```
如果是,只需要跟之前一样设定 `model_name_or_path`:
```shell
--model_name_or_path $CHECKPOINT_PATH
```
评测指标为中文 Rouge score 和 BLEU-4。生成的结果保存在
`./output/adgen-chatglm2-6b-pt-128-2e-2/generated_predictions.txt`。
### 例子
#### 示例1
* Input: 类型#上衣\*材质#牛仔布\*颜色#白色\*风格#简约\*图案#刺绣\*衣样式#外套\*衣款式#破洞
* Label: 简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。
* Output[微调前]: 这件上衣的材质是牛仔布,颜色是白色,风格是简约,图案是刺绣,衣样式是外套,衣款式是破洞。
* Output[微调后]: 这是一款简约的牛仔外套,破洞设计,将牛仔布破洞,带来一种随意与个性。破洞的牛仔外套,展现出时尚气息,带来一种休闲感。同时,刺绣图案,让整件外套更加立体。
#### 示例2
* Input: 类型#裙\*版型#显瘦\*风格#文艺\*风格#简约\*图案#印花\*图案#撞色\*裙下摆#压褶\*裙长#连衣裙\*裙领型#圆领
* Label: 文艺个性的印花连衣裙,藏青色底蕴,低调又大气,撞色太阳花分布整个裙身,绚丽而美好,带来时尚减龄的气质。基础款的舒适圆领,简约不失大方,勾勒精致脸庞。领后是一粒包布扣固定,穿脱十分方便。前片立体的打褶设计,搭配后片压褶的做工,增添层次和空间感,显瘦又有型。
* Output[微调前]: 类型#裙*版型#显瘦*风格#文艺*风格#简约*图案#印花*图案#撞色*裙下摆#压褶*裙长#连衣裙*裙领型#圆领 1\. 连衣裙:简约风格,裙长为膝盖以上,裙领型为圆领。2\. 裙下摆:压褶设计,使裙摆呈现出流畅的褶皱效果。3\. 裙领型:裙领型为圆领,使穿上连衣裙后更加有型。4\. 版型:采用显瘦设计,让连衣裙看起来更加苗条。5\. 风格:文艺风格,让连衣裙更加有内涵和品味。6\. 图案:印花设计,在连衣裙上印有独特的图案。7\. 撞色:采用撞色设计,让连衣裙在色彩上更加鲜明、富有层次感。
* Output[微调后]: 这是一款文艺范的连衣裙,以印花为元素,采用简约的印花,既能够突出文艺气质,又能够展现简约风。在印花的同时又有领子和裙摆的压褶设计,更加凸显文艺气质。简约而不会过于单调,搭配出街,穿着十分舒适。
## 模型部署
首先载入Tokenizer:
```python
from transformers import AutoConfig, AutoModel, AutoTokenizer
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
```
1. 如果需要加载的 P-Tuning 的 checkpoint:
```python
config = AutoConfig.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
```
注意你可能需要将 `pre_seq_len` 改成你训练时的实际值。如果你是[从本地加载模型](../README.md#从本地加载模型)的话,需要将 `THUDM/chatglm2-6b` 改成本地的模型路径(注意不是checkpoint路径)。
2. 如果需要加载的是全参数微调的 checkpoint,则直接加载整个 checkpoint:
```python
model = AutoModel.from_pretrained(CHECKPOINT_PATH, trust_remote_code=True)
```
之后根据需求可以进行量化,也可以直接使用:
```python
# Comment out the following line if you don't use quantization
model = model.quantize(4)
model = model.cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
```
你也可以直接运行支持加载 P-Tuning v2 checkpoint 的 [web demo](./web_demo.py)
```shell
bash web_demo.sh
```
可能需要修改 [web_demo.sh](./web_demo.sh) 的内容以符合你实际的 checkpoint 情况。
## 使用自己的数据集
修改 `train.sh` 和 `evaluate.sh` 中的 `train_file`、`validation_file`和`test_file`为你自己的 JSON 格式数据集路径,并将 `prompt_column` 和 `response_column` 改为 JSON 文件中输入文本和输出文本对应的 KEY。可能还需要增大 `max_source_length` 和 `max_target_length` 来匹配你自己的数据集中的最大输入输出长度。
## 对话数据集
如需要使用多轮对话数据对模型进行微调,可以提供聊天历史,例如以下是一个三轮对话的训练数据:
```json lines
{"prompt": "长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "response": "用电脑能读数据流吗?水温多少", "history": []}
{"prompt": "95", "response": "上下水管温差怎么样啊?空气是不是都排干净了呢?", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"]]}
{"prompt": "是的。上下水管都好的", "response": "那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!", "history": [["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"], ["95", "上下水管温差怎么样啊?空气是不是都排干净了呢?"]]}
```
训练时需要指定 `--history_column` 为数据中聊天历史的 key(在此例子中是 `history`),将自动把聊天历史拼接。要注意超过输入长度 `max_source_length` 的内容会被截断。
可以参考以下指令:
bash train_chat.sh
这篇关于ChatGLM2-6B 模型基于 [P-Tuning v2]的微调的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








