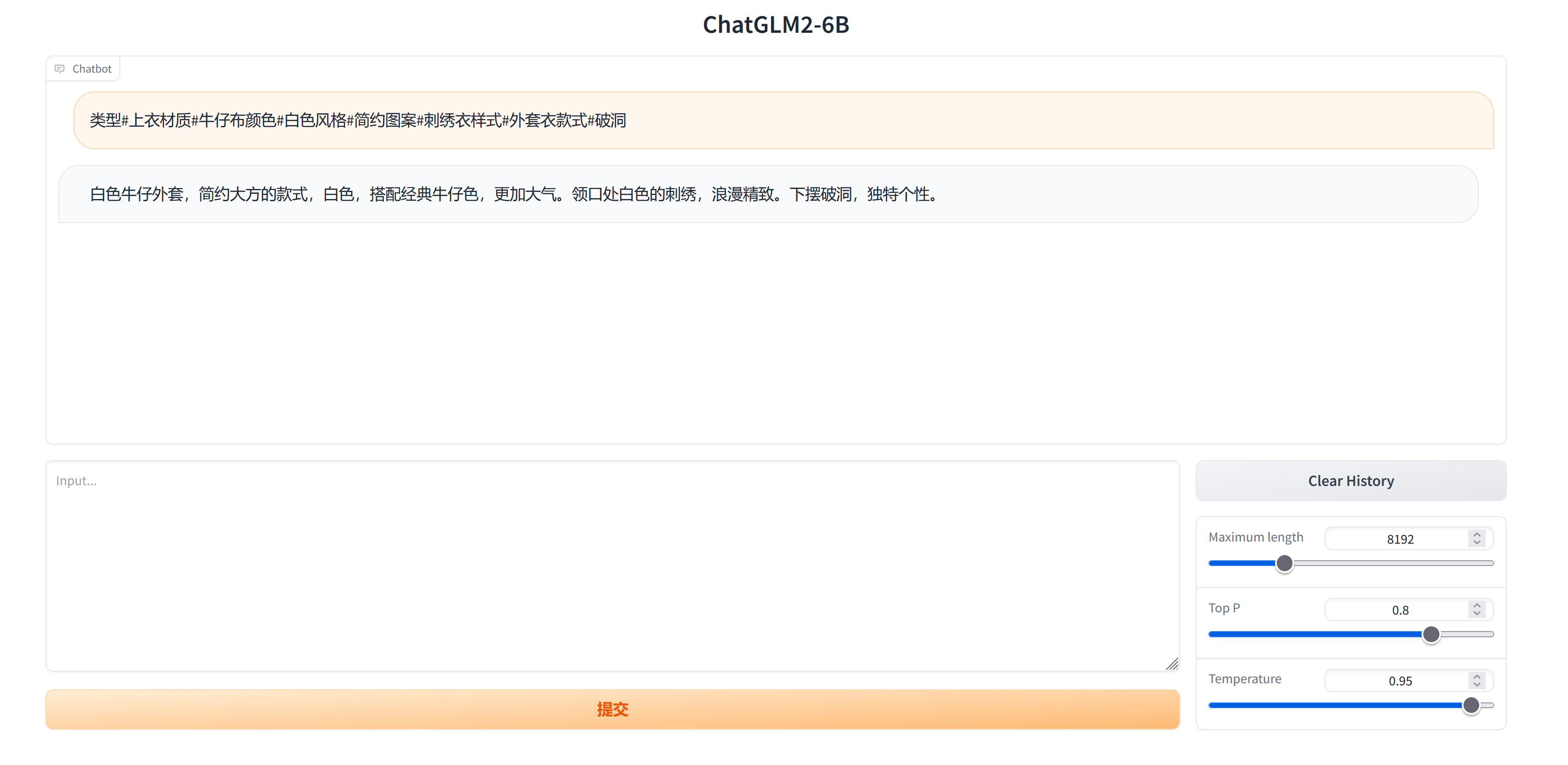
chatglm2专题

python-Langchain-Chatchat+ChatGLM2-6B在16G内存电脑上运行
python-Langchain-Chatchat+ChatGLM2-6B在16G内存电脑上运行 代码链接ChatGLMLangchain-Chatchat 环境准备模型下载Langchain-Chatchat配置configs中example文件修改configs/model_config.py修改修改 server配置 知识库初始化参考链接 代码链接 ChatGLM ht
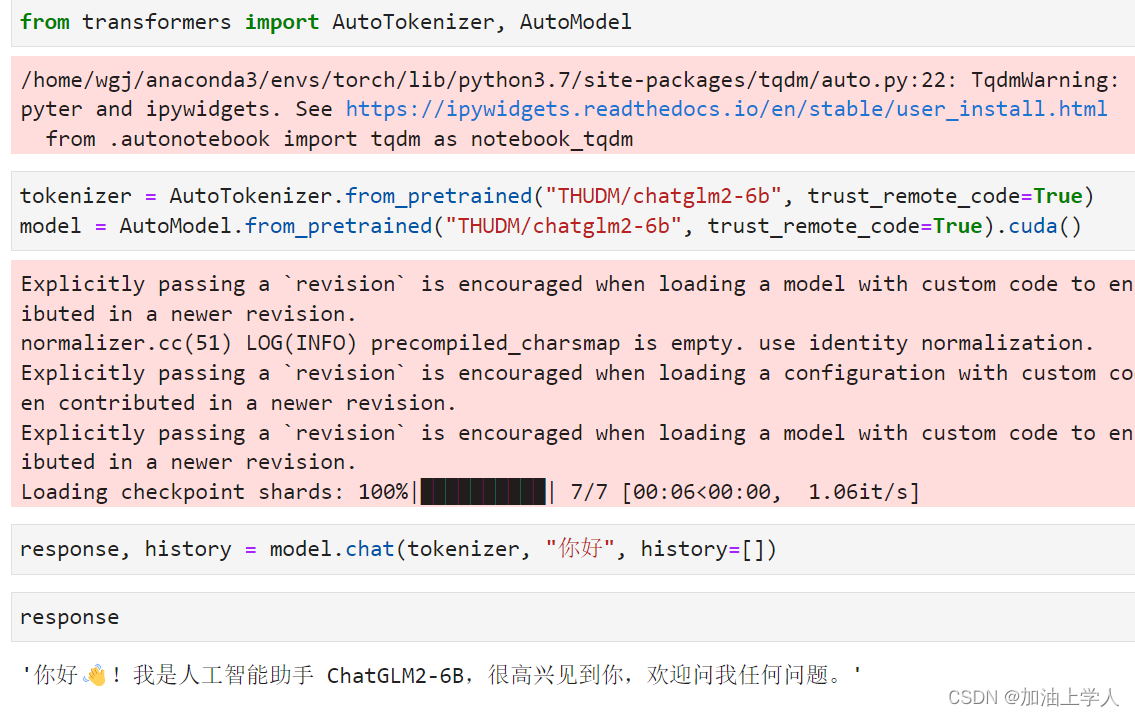
ChatGLM2-6b的本地部署
** 大模型玩了一段时间了,一直没有记录,借假期记录下来 ** ChatGlm2介绍: chatglm2是清华大学发布的中英文双语对话模型,具备强大的问答和对话功能,拥有长达32K的上下文,可以输出比较长的文本。6b的训练参数量为60亿,本地部署大约需要12G以上的显存才能运行起来,但6b提供了一个量化后的int4版本,实测推理仅需要6gb即可。int4版本对于某些老旧的或者不支持int4的G
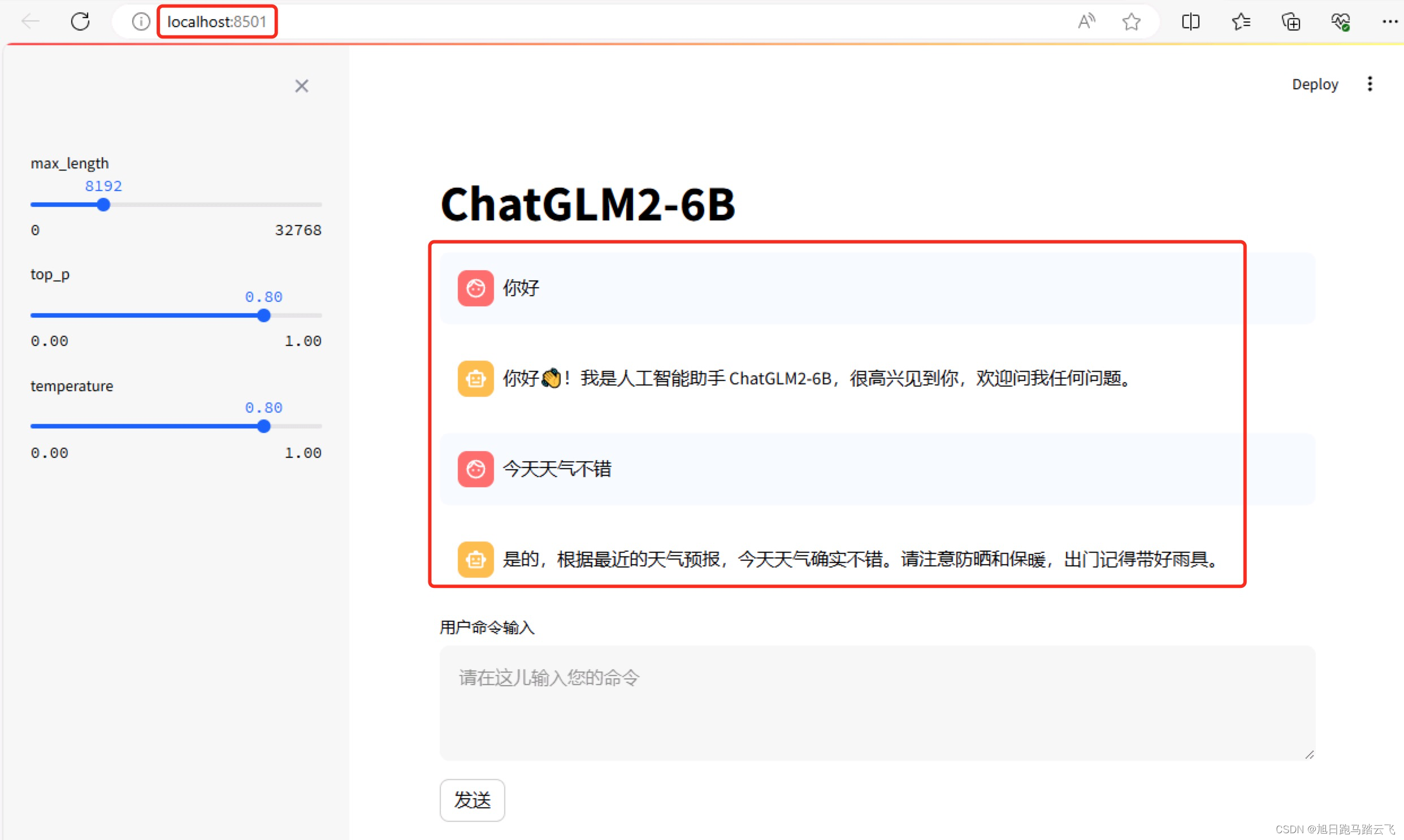
【AI基础】第三步:纯天然手动安装并运行chatglm2-6b
chatglm2构建时使用了RUST,所以在安装chatglm2之前,先安装RUST。 一、安装RUST 1.1 配置安装源 如果从官方安装,速度奇慢。 配置环境变量 RUSTUP_DIST_SERVER 到国内源: 这里指定了清华源,其余国内源还有: # 字节跳动 RUSTUP_DIST_SERVER=https://rsproxy.cn RUSTUP_UPDATE_ROOT=
![ChatGLM2-6B 模型基于 [P-Tuning v2]的微调](https://img-blog.csdnimg.cn/direct/59b132f34fa64e6d8128bb325732b79a.png)
ChatGLM2-6B 模型基于 [P-Tuning v2]的微调
ChatGLM2-6B-PT 一、介绍 1、本文实现对于 ChatGLM2-6B 模型基于 [P-Tuning v2](https://github.com/THUDM/P-tuning-v2) 的微调 2、运行至少需要 7GB 显存 3、以 [ADGEN](https://aclanthology.org/D19-1321.pdf) (广告生成) 数据集为例介绍代码的使用方法。

如何在本地调试THUDM/chatglm2-6b大模型
模型下载网站:https://www.opencsg.com/models 安装git: sudo apt install git 安装git-lfs,这个很重要。 sudo apt-get install git-lfs 下载模型:THUDM/chatglm2-6b mkdir THUDMcd THUDMgit lfs intsallgit clone https://por
部署接入 M3E和chatglm2-m3e文本向量模型
前言 FastGPT 默认使用了 openai 的 embedding 向量模型,如果你想私有部署的话,可以使用 M3E 向量模型进行替换。M3E 向量模型属于小模型,资源使用不高,CPU 也可以运行。下面教程是基于 “睡大觉” 同学提供的一个的镜像。 部署镜像 m3e-large-api 镜像名: stawky/m3e-large-api:latest 国内镜像: registry.cn
从零开始学AI:ChatGLM2-6B 部署测试
1.ChatGLM2 介绍 ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性: 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.
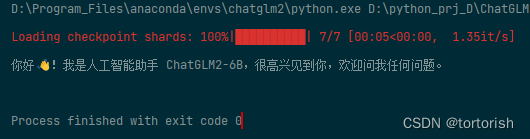
ChatGLM2本地部署方法
chatglm2部署在本地时,需要从huggingface上下载模型的权重文件(需要科学上网)。下载后权重文件会自动保存在本地用户的文件夹上。但这样不利于分享,下面介绍如何将chatglm2模型打包部署。 一、克隆chatglm2部署 这个项目是chatglm2的部署和实现方式,将模型以网页demo的形式呈现,其并不包含模型的结构。 git clone http
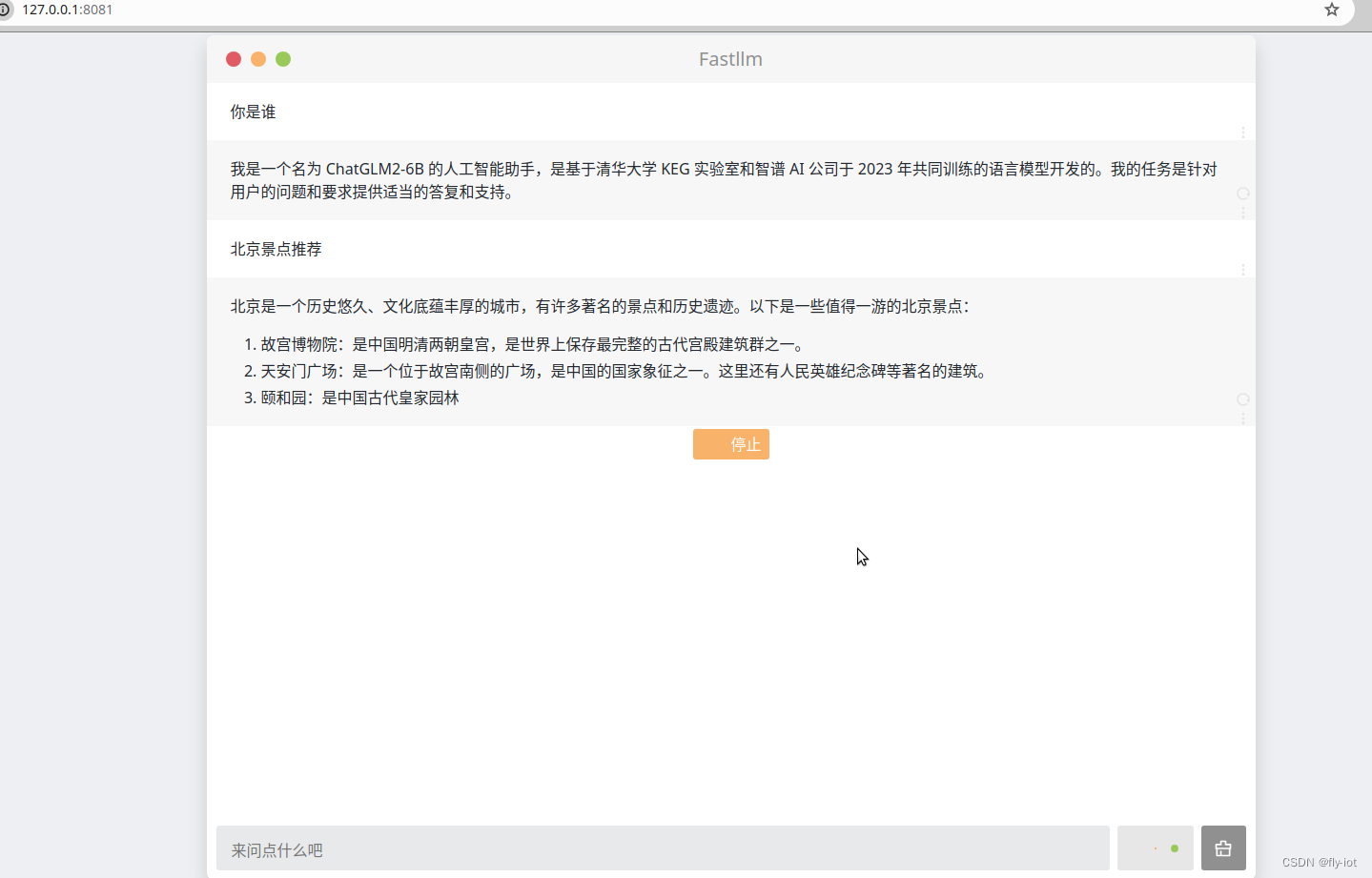
【fastllm】学习框架,本地运行,速度还可以,可以成功运行chatglm2模型
1,关于 fastllm 项目 https://www.bilibili.com/video/BV1fx421k7Mz/?vd_source=4b290247452adda4e56d84b659b0c8a2 【fastllm】学习框架,本地运行,速度还可以,可以成功运行chatglm2模型 https://github.com/ztxz16/fastllm 🚀 纯c++实
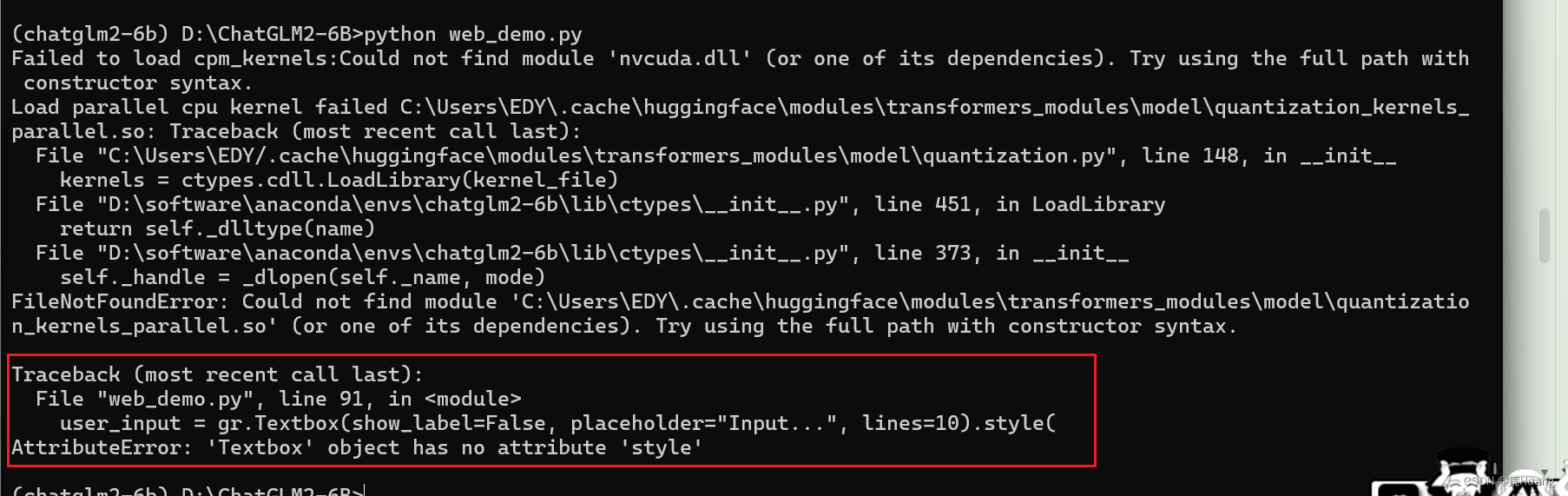
Windows环境下搭建chatGLM2-6B-int4量化版模型(图文详解-成果案例)
目录 一、ChatGLM2-6介绍 二、环境准备 1. 硬件环境 2. TDM-GCC安装 3.git安装 4.Anaconda安装 三、模型安装 1.下载ChatGLM2-6b和环境准备 方式一:git命令 方式二:手动下载 2.下载预训练模型 在Hugging Face HUb下载(挂VPN访问) (1)git命令行下载: (2)手动下载(建议) 3.模型使用(
![[FT]chatglm2微调](/front/images/it_default.jpg)
[FT]chatglm2微调
1.准备工作 显卡一张:A卡,H卡都可以,微调需要1-2张,ptunig需要一张,大概显存得30~40G吧;全量微调需要两张卡,总显存占用100G以上环境安装: 尽量在虚拟环境安装:参见,https://blog.csdn.net/u010212101/article/details/103351853环境安装参见:https://github.com/THUDM/ChatGLM2-6B/tre
用TensorRT-LLM跑通chatGLM2_6B模型
零、参考资料 NVIDIA官网 THUDM的Github NVIDIA的Github 一、构建 TensorRT-LLM的docker镜像 git lfs installgit clone https://github.com/NVIDIA/TensorRT-LLM.gitcd TensorRT-LLMgit submodule update --init --recursives
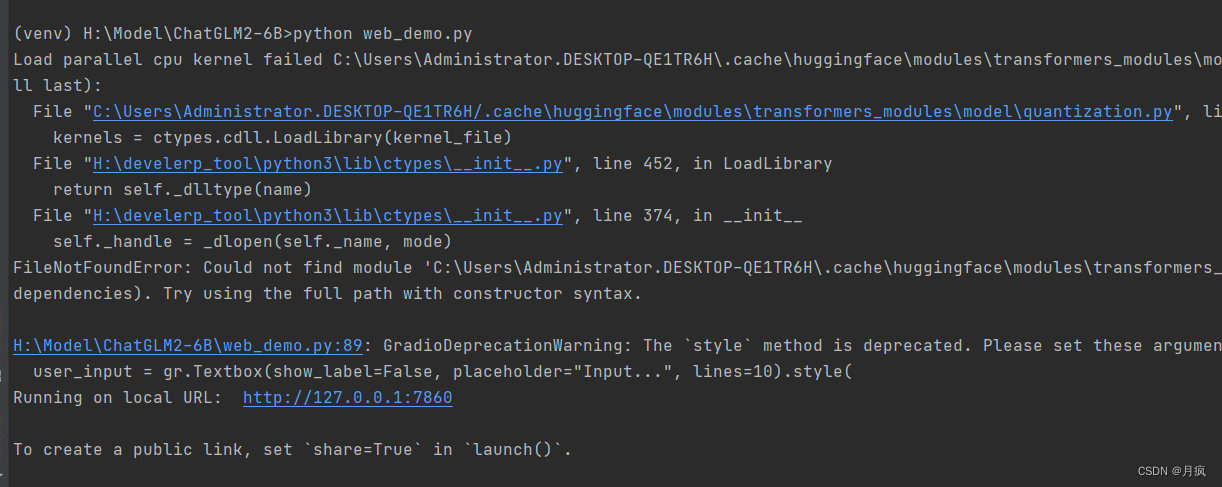
ChatGLM2-6B模型的win10测试笔记
ChatGLM2-6B介绍: 介绍 ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性: 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过
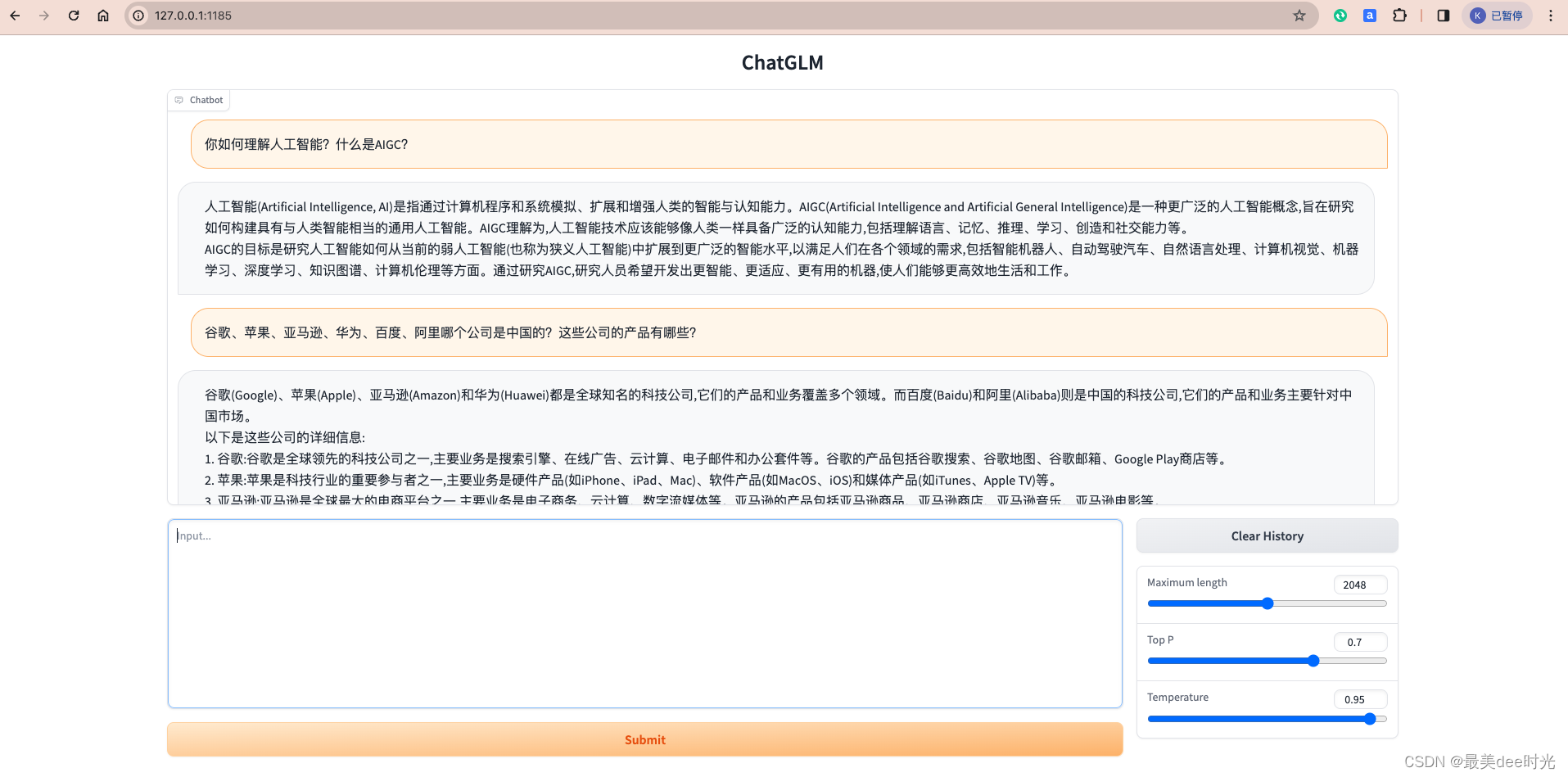
基于MacBook Pro M1芯片运行chatglm2-6b大模型
文章目录 1. 参考2. ChatGLM2-6B 介绍3. 本地运行3.1 硬件配置3.2 下载ChatGLM2-6B代码3.3 下载需要加载的模型3.4 运行大模型3.4.1 安装依赖3.4.2 编辑web_demo.py3.4.3 启动 4. 测试 1. 参考 ChatGLM2-6B代码地址chatglm2-6b模型地址Mac M1芯片部署 2. ChatGLM2-6B
ChatGLM2-6B 大语言模型本地搭建
ChatGLM模型介绍: ChatGLM2-6B 是清华 NLP 团队于不久前发布的中英双语对话模型,它具备了强大的问答和对话功能。拥有最大32K上下文,并且在授权后可免费商用! ChatGLM2-6B的6B代表了训练参数量为60亿,同时运用了模型量化技术,意味着用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存) 详细介绍(官方git:https://gith
基于 P-Tuning的高效微调ChatGLM2-6B
1 ChatGLM2-6B介绍 ChatGLM是清华技术成果转化的公司智谱AI研发的支持中英双语的对话机器人。ChatGLM基于GLM130B千亿基础模型训练,它具备多领域知识、代码能力、常识推理及运用能力;支持与用户通过自然语言对话进行交互,处理多种自然语言任务。比如:对话聊天、智能问答、创作文章、创作剧本、事件抽取、生成代码等等。 代码地址:https://github.com/THUDM

【chatglm2】使用Python在CPU环境中运行 chatglm.cpp 可以实现本地使用CPU运行chatglm2模型,速度也特别的快可以本地部署,把现有项目进行AI的改造。
1,项目地址 https://github.com/li-plus/chatglm.cpp.git 这个项目和llama.cpp 项目类似,使用C++ 去运行模型的。 项目使用了 ggml 这个核心模块,去运行的。 可以支持在 cpu 上面跑模型。 ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之

ChatGLM2-6b小白部署教程(windows系统,16G内存即可,对显卡无要求,CPU运行)
一.前言 近期清华KEG和智谱AI公司一起发布了中英双语对话模型ChatGLM2-6B(小尺寸LLM),开源在https://github.com/THUDM/ChatGLM2-6B,可单机部署推理和fine-tune。虽然默认程序是GPU运行且对显卡要求不高,官方也说默认需要13G的显存,使用量化模型貌似只需要6G显存,但对于我这种平民玩家,不租云服务器的话,单靠我这GTX3
chatglm2-6b本地部署(v0.1)
1.前置工具:安装anaconda,安装cuda/cudnn 2.下载安装包和模型 源码安装包:https://github.com/THUDM/ChatGLM2-6B 模型:https://huggingface.co/models?sort=trending&search=chatglm 3.创建并激活环境 conda create --name ChatGLM2B python==
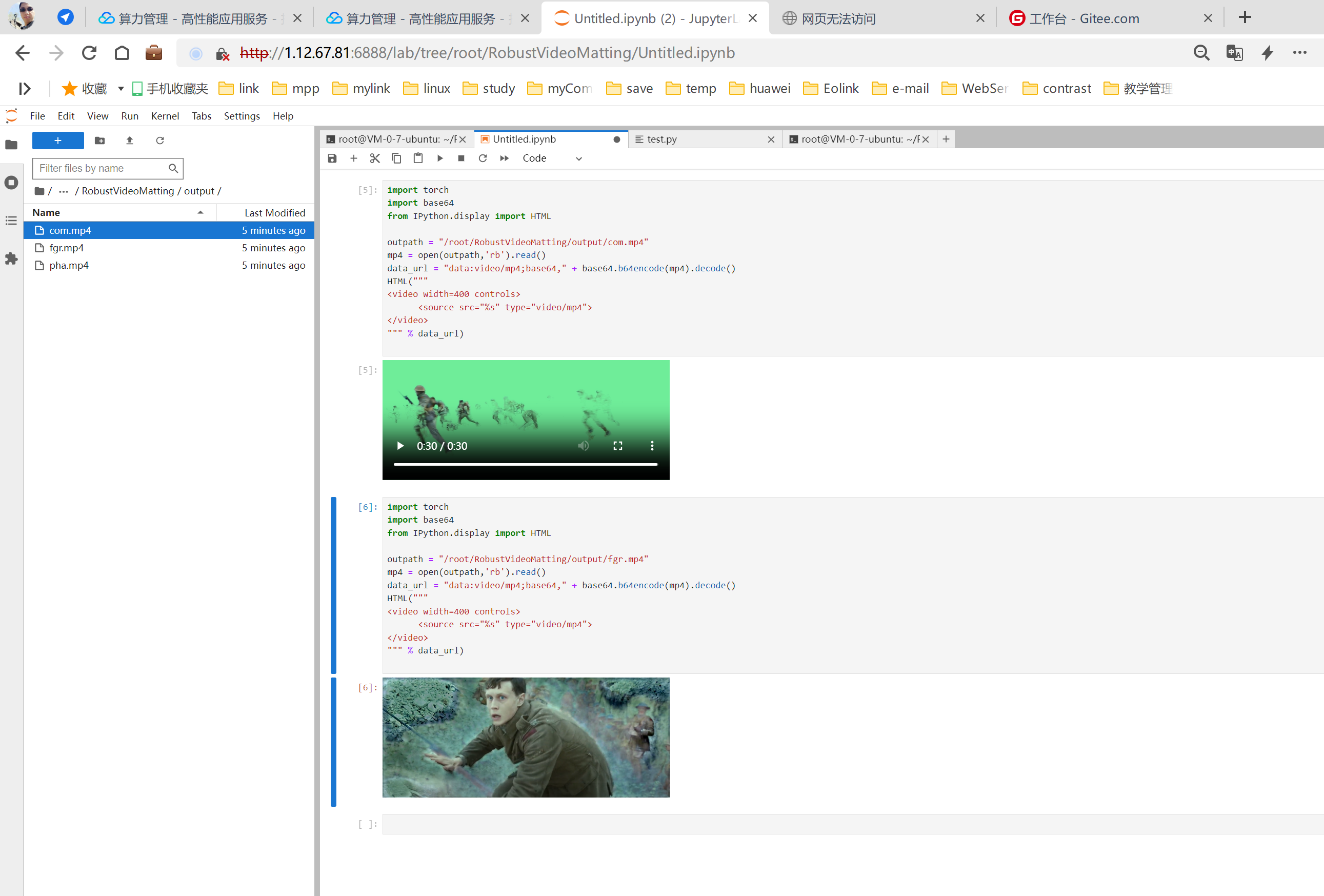
【腾讯云 HAI域探秘】——即时职场生存指南小游戏以及【自行搭建Stable Diffusion图片AI绘制 | ChatGLM2-6B AI进行智能对话 | Pytorch2.0 AI框架视频处理】
利用HAI的ChatGLM2 6B做一个即时对话小游戏 ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了更强大的性能、更长的上下文、更高效的推理,所以用来做个小游戏非常的合适了。 我基本没有做什么语句优化,直接给了,并且能看到回复的情况,相当可以的呢。接下来我们
【LangChain实战】开源模型学习(1)-ChatGLM2-6B
介绍 ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性: 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了
ChatGLM2-6B微调过程说明文档
参考文档: ChatGLM2-6B 微调(初体验) - 知乎 环境配置 下载anaconda,版本是Anaconda3-2023.03-0-Linux-x86_64.sh,其对应的python版本是3.10,试过3.7和3.11版本的在运行时都报错。 执行下面的命令安装anaconda sh Anaconda3-2023.03-0-Linux-x86_64.sh 进入安装过程
centos 显卡驱动安装(chatglm2大模型安装步骤一)
1.服务器配置 服务器系统:Centos7.9 x64 显卡:RTX3090 (24G) 2.安装环境 2.1 检查显卡驱动是否安装 输入命令:nvidia-smi(显示显卡信息) 如果有以下显示说明,已经有显卡驱动。否则需要重装。 2.2 下载显卡驱动 第一步:浏览器输入https://www.nvidia.cn/Download/index.aspx,跳转到英伟达显卡页面,点击s
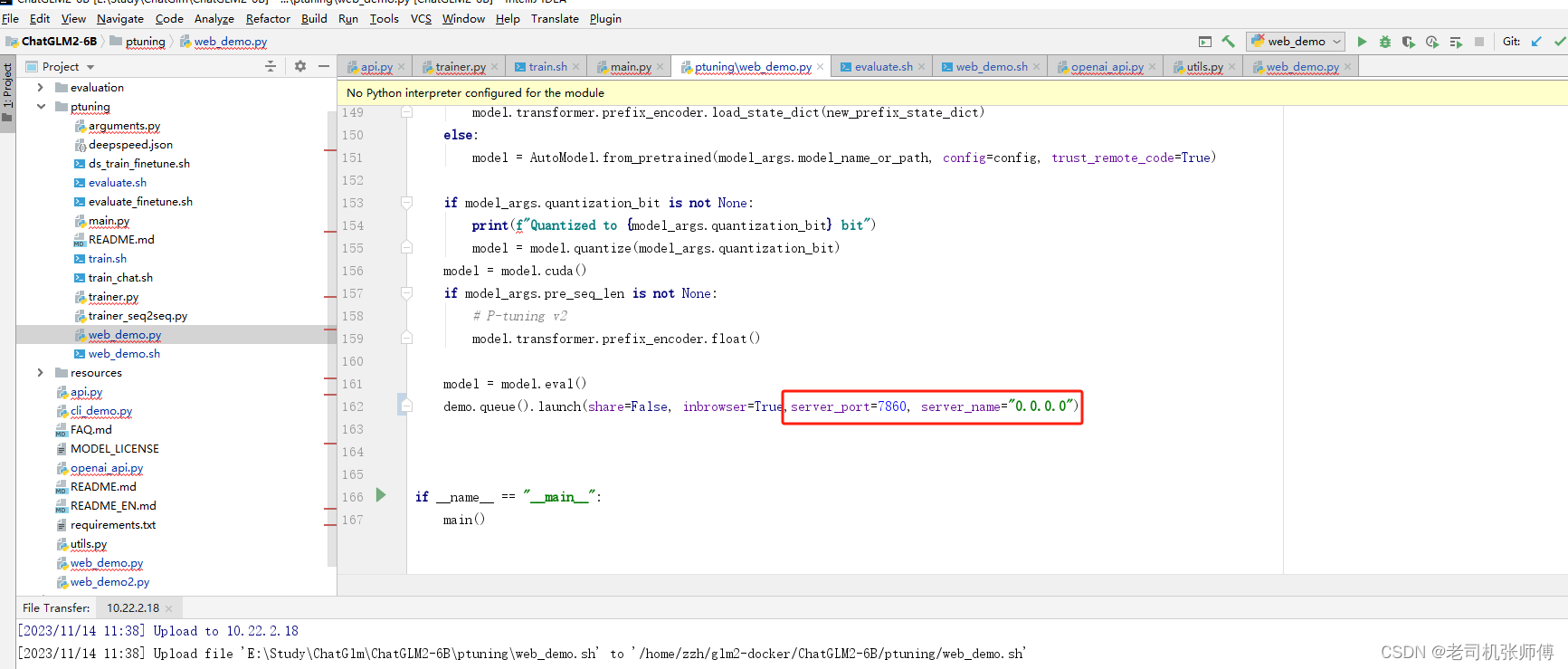
【ChatGLM2-6B】Docker下部署及微调
【ChatGLM2-6B】小白入门及Docker下部署 一、简介1、ChatGLM2是什么2、组成部分3、相关地址 二、基于Docker安装部署1、前提2、CentOS7安装NVIDIA显卡驱动1)查看服务器版本及显卡信息2)相关依赖安装3)显卡驱动安装 2、 CentOS7安装NVIDIA-Docker1)相关环境准备2)开始安装3)验证&使用 3、 Docker部署ChatGLM21)下

ChatGLM2-6B 部署与微调
文章目录 一、ChatGLM-6B二、ChatGLM2-6B三、本地部署ChatGLM2-6B3.1 命令行模式3.2 网页版部署3.3 本地加载模型权重3.4 模型量化3.5 CPU部署3.6 多卡部署 四、P-tuning v2微调教程4.1 P-tuning v2 原理4.2 P-tuning v2微调实现4.2.1 安装依赖,下载数据集4.2.2 开始训练4.2.3 训练效果对比4.
ChatGLM2 大模型微调过程中遇到的一些坑及解决方法(更新中)
1. 模型下载问题 OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like bert-base-uncased is not the path to a directory containin