本文主要是介绍ChatGLM2-6B模型的win10测试笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ChatGLM2-6B介绍:
介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练。对于更长的上下文,我们发布了 ChatGLM2-6B-32K 模型。LongBench 的测评结果表明,在等量级的开源模型中,ChatGLM2-6B-32K 有着较为明显的竞争优势。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写[问卷](https://open.bigmodel.cn/mla/form)进行登记后**亦允许免费商业使用**。
代码托管的github:https://github.com/THUDM/ChatGLM-6B
先将代码下载到本地:
可以使用git :
git clone https://github.com/THUDM/ChatGLM2-6B或者直接将GitHubzip包下载到本地,然后解压:
Multi-Query Attention 同时也降低了生成过程中 KV Cache 的显存占用,此外,ChatGLM2-6B 采用 Causal Mask 进行对话训练,连续对话时可复用前面轮次的 KV Cache,进一步优化了显存占用。因此,使用 6GB 显存的显卡进行 INT4 量化的推理时,初代的 ChatGLM-6B 模型最多能够生成 1119 个字符就会提示显存耗尽,而 ChatGLM2-6B 能够生成至少 8192 个字符。
| 量化等级 | 编码 2048 长度的最小显存 | 生成 8192 长度的最小显存 |
|---|---|---|
| FP16 / BF16 | 13.1 GB | 12.8 GB |
| INT8 | 8.2 GB | 8.1 GB |
| INT4 | 5.5 GB | 5.1 GB |
然后去huggingface去下载模型文件:
https://huggingface.co/THUDM/chatglm2-6b 这个是FP16的站显存比较大
我们选择INT-4:
https://huggingface.co/THUDM/chatglm2-6b-int4/tree/main
然后将文件下载到本地,注意huggingface需要翻墙,现在国内无法登陆
下载zip解压到本地,然后创建一个model的文件,存放模型文件,这是我下载到本地的文件:
本地下载的模型文件 :
然后启动pycharm,导入这个项目
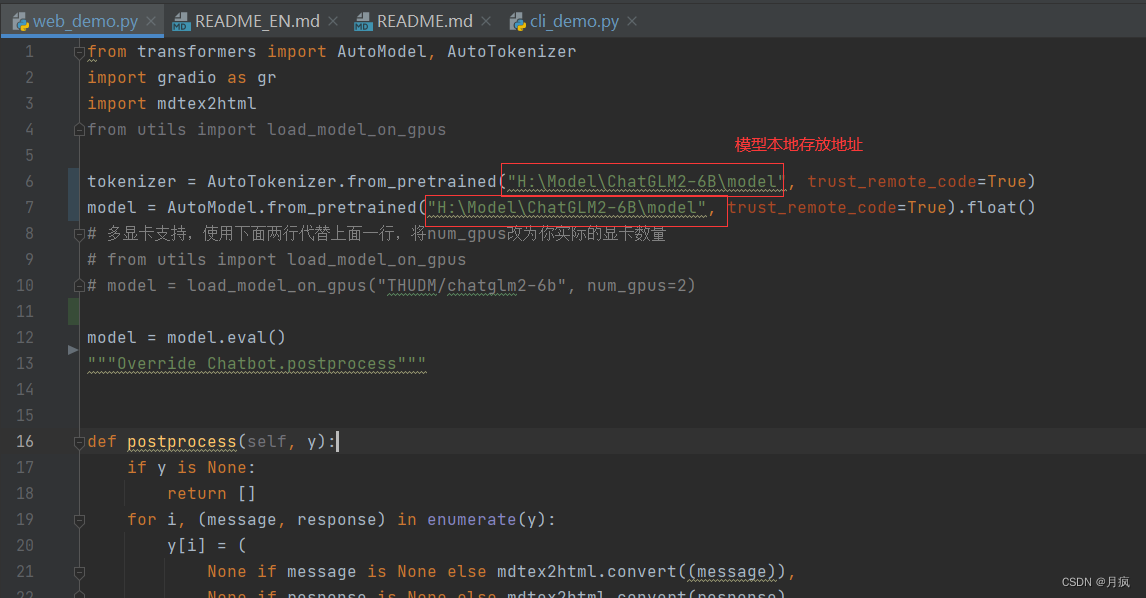
修改模型加载地址:打开web_demo.py文件
然后使用 pip 安装依赖:
pip install -r requirements.txt
其中 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。
我是测试CPU运行,所以还要改一些地方:我这边选择的是chatglm2-6b-int4
CPU 部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()如果你的内存不足的话,也可以使用量化后的模型
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).float()在 cpu 上运行量化后的模型需要安装
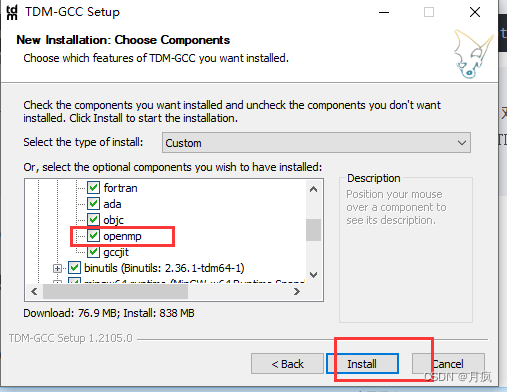
gcc与openmp。多数 Linux 发行版默认已安装。对于 Windows ,可在安装 TDM-GCC 时勾选openmp。 Windows 测试环境gcc版本为TDM-GCC 10.3.0, Linux 为gcc 11.3.0。
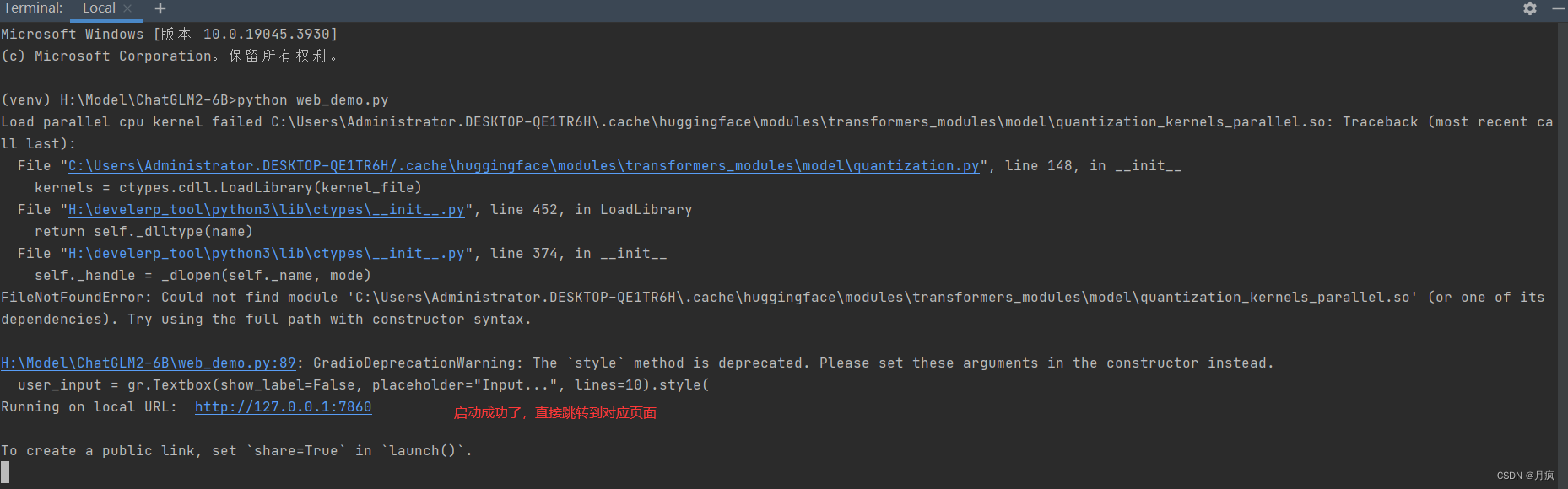
如果不安装 TDM-GCC 会报错:安装TDM-GCC如果不选openmp会报错:
TDM-GCC g++: error: libgomp.spec: No such file or directory
注意要勾选:TDM-GCC的安装过程


安装好了。
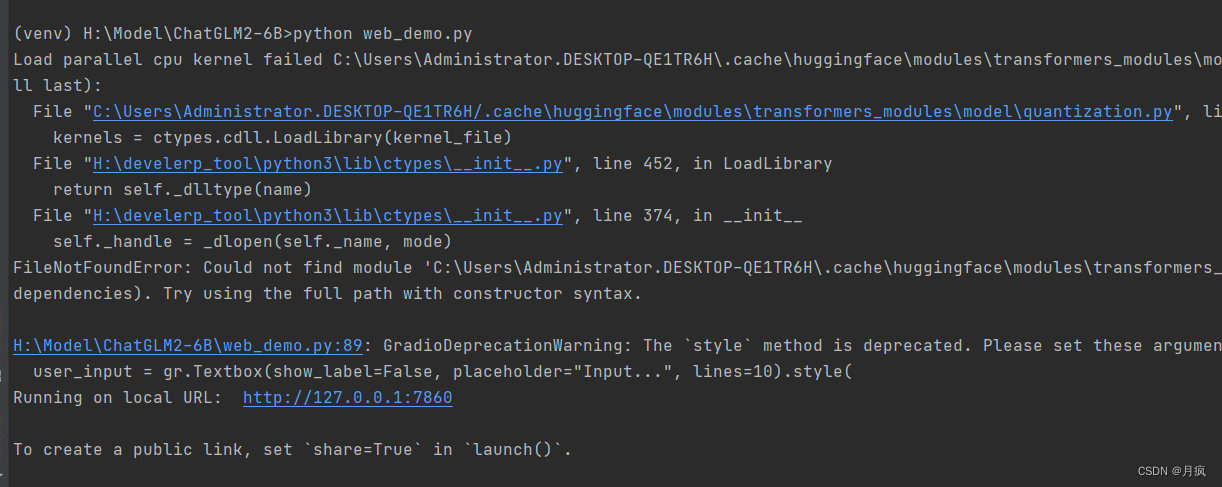
运行还会报错:
Traceback (most recent call last):
File "H:\Model\ChatGLM2-6B\web_demo.py", line 89, in <module>
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(
AttributeError: 'Textbox' object has no attribute 'style'
解决:gradio安装3.40.0
pip install gradio==3.40.0
ChatGLM2-6B有三中方式实现交互:
web_demo.py 是 gradio测试网页版本
启动命令:python web_demo.py
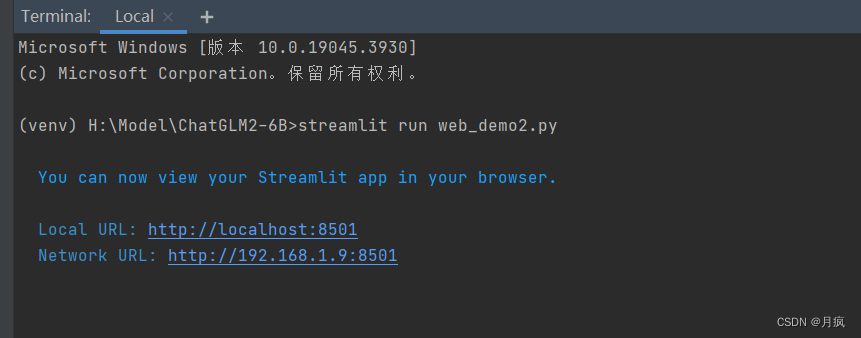
web_demo2.py是命令启动基于 Streamlit 的网页版 demo
启动命令:
streamlit run web_demo2.pycli_demo.py 是程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入
clear可以清空对话历史,输入stop终止程序。启动命令:
python cli_demo.py
然后运行python web_demo.py
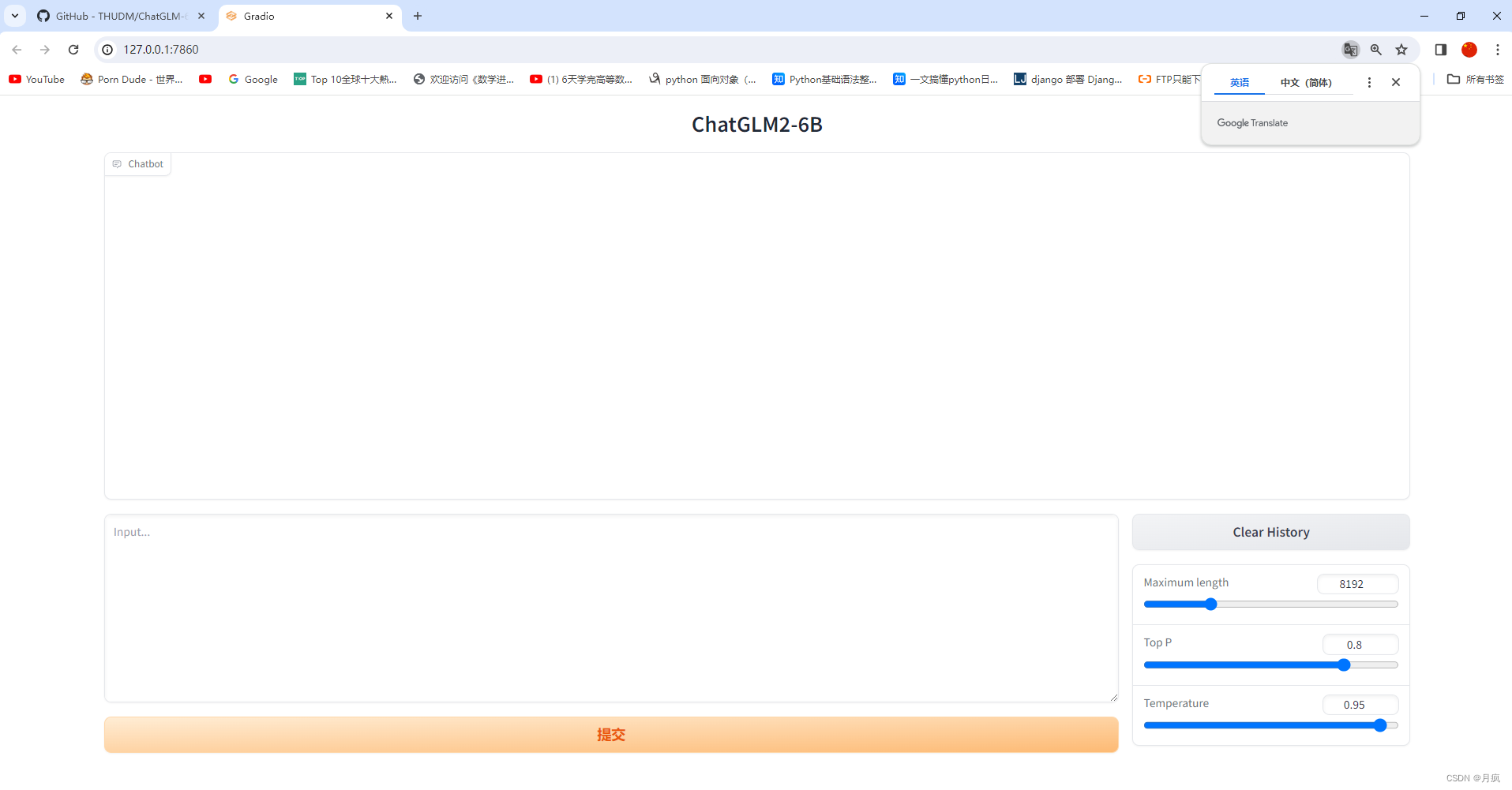
然后可以开始对话了,但是特别的卡,主要是我的配置太低了
半天就刷出来这几个字,哈哈
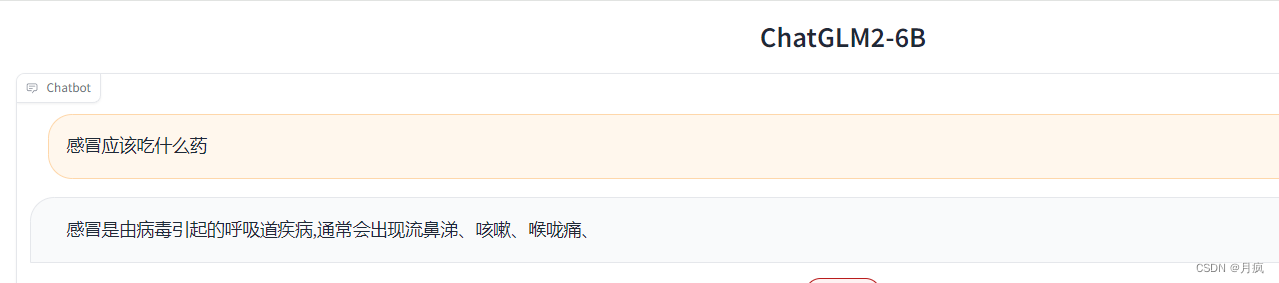
测试 web_demo2.py

测试cli_demo.py

在安装显卡驱动的前提下(显卡驱动安装方法),输入:
nvidia-smi
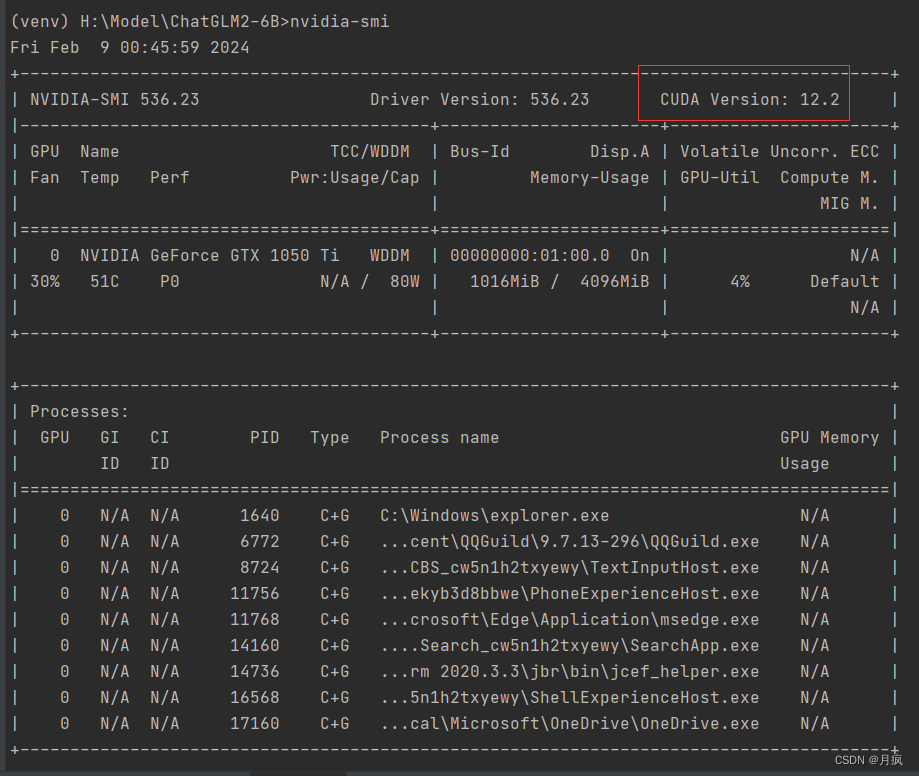
可以看到该电脑可以支持的cuda版本最高是12.2,驱动是向下兼容的,所以cuda版本小于等于12.2的都可以安装上。
先安装CUDA的一个版本,我们先要安装cuda,cuda11.7是稳定版本,cuda12.1是预览版本,但是不稳定。所以我们安装CUDA11.7
官网:CUDA

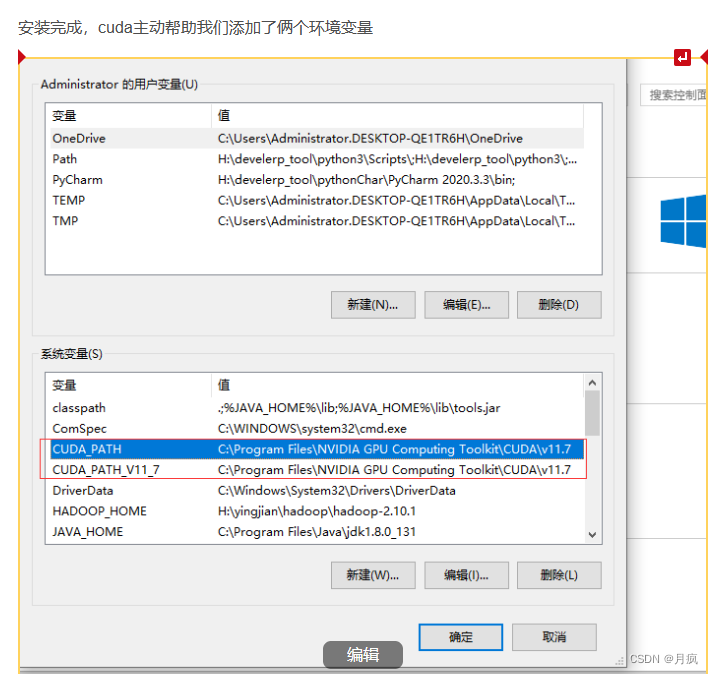
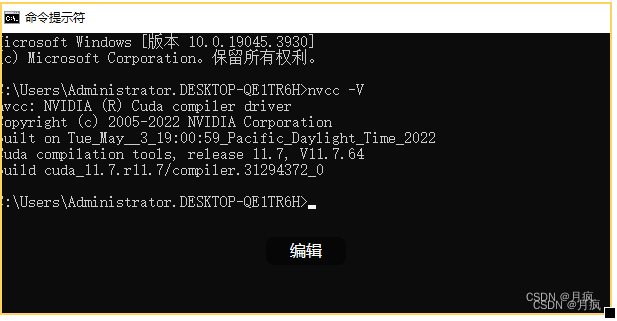
cmd查看是否安装成功:
nvcc -V
cudnn下载:cudnn官网
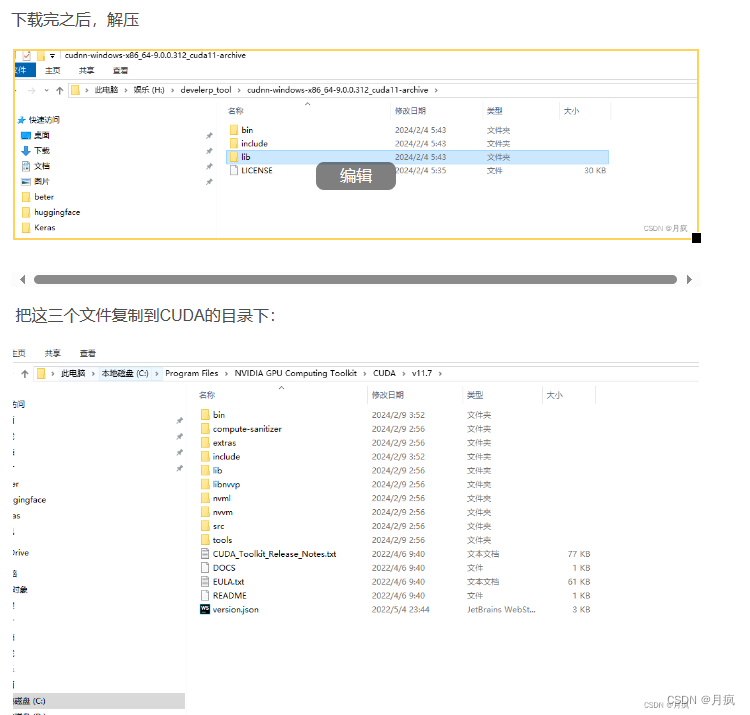
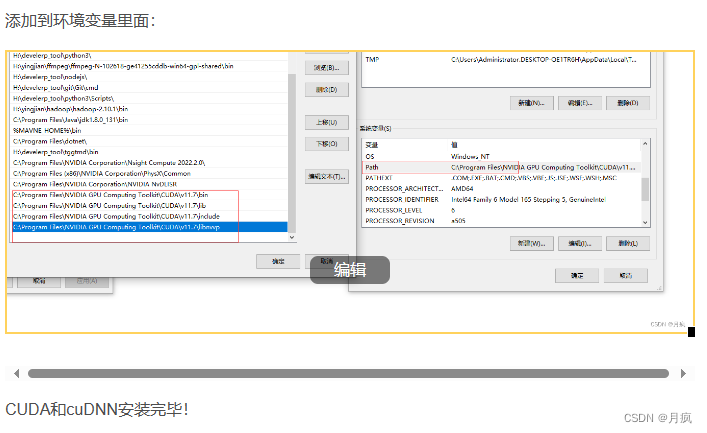
GPU运行会提示错误:
AssertionError: Torch not compiled with CUDA enabled
主要是安装的torch不支持GPU导致的,我们先把torch卸载掉,然后下载和GPU相匹配的torch
pip uninstall torch
然后下载和torch对应支持的cuda版本
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
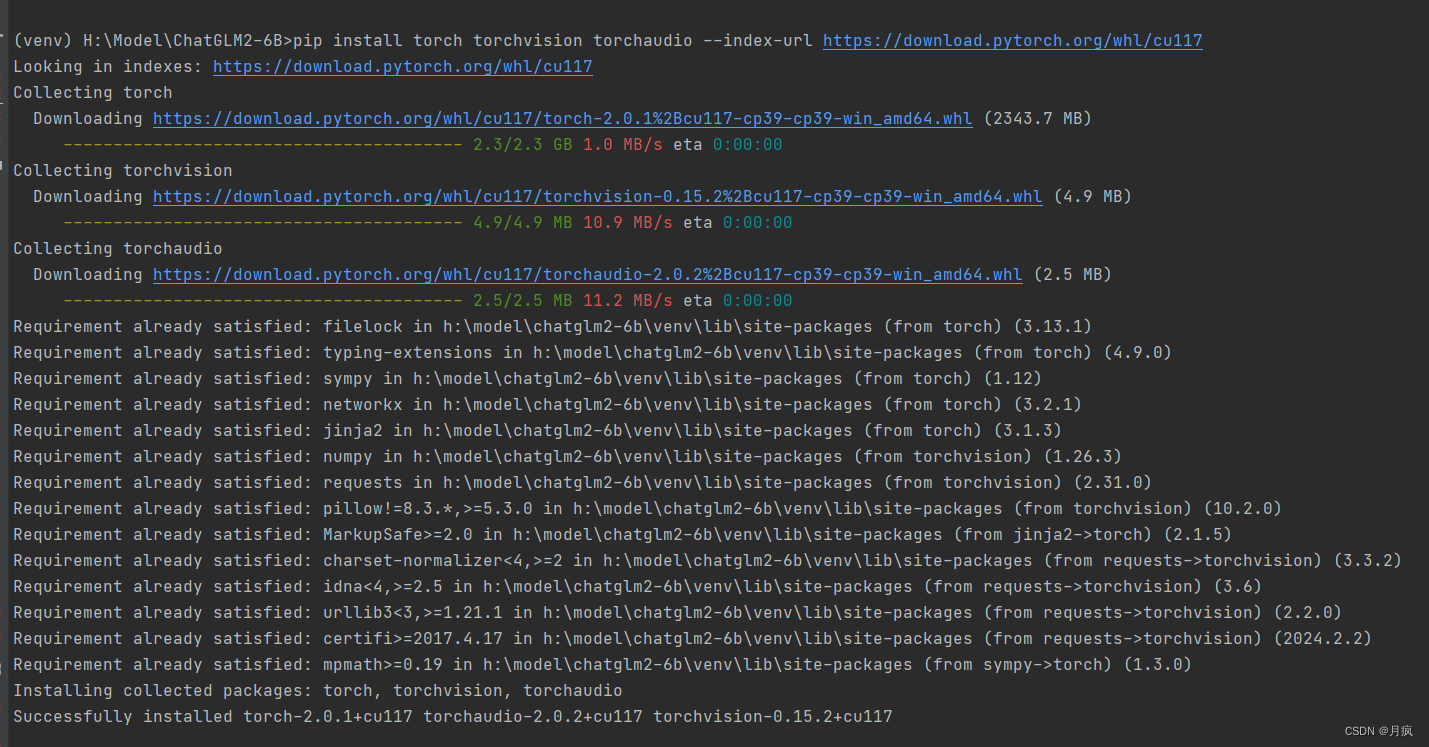
安装成功了,我们测试一下
这篇关于ChatGLM2-6B模型的win10测试笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









