本文主要是介绍ChatGLM2-6b的本地部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
** 大模型玩了一段时间了,一直没有记录,借假期记录下来 **
ChatGlm2介绍:
chatglm2是清华大学发布的中英文双语对话模型,具备强大的问答和对话功能,拥有长达32K的上下文,可以输出比较长的文本。6b的训练参数量为60亿,本地部署大约需要12G以上的显存才能运行起来,但6b提供了一个量化后的int4版本,实测推理仅需要6gb即可。int4版本对于某些老旧的或者不支持int4的GPU而言运行不了,在额外的blog里面会记录如何修改使其运行起来。
硬件需求
要确保自己有超过32G的内存,超过12G的显存且显卡支持float16计算,以及足够的硬盘空间
模型部署
代码下载
git clone https://github.com/THUDM/ChatGLM2-6Bcd ChatGLM2-6B
环境配置
conda create -n torch python=3.10 ipykernel
conda activate torch
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simlple
模型下载
建议使用这样的方式,同时这也解决了国内无法访问huggingface的问题:
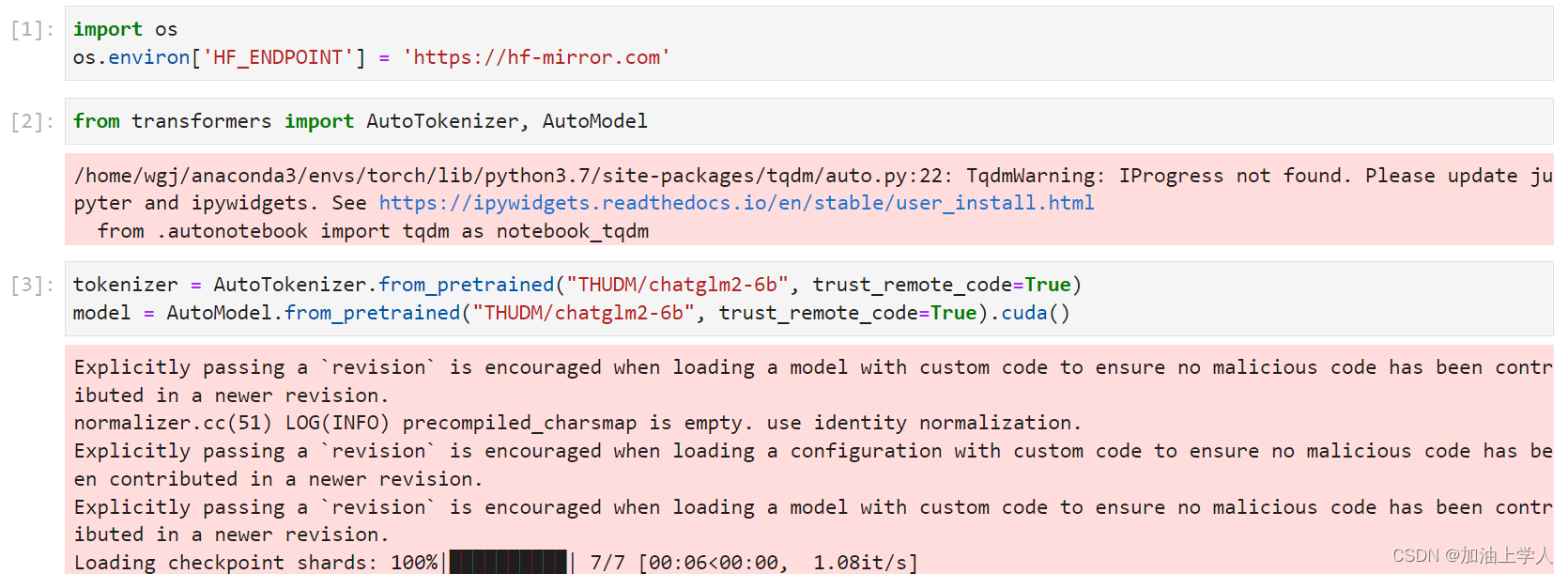
或者直接从清华的数据库进行下载:清华云
如果速度不够快,也可以用paddle,阿里云进行下载,实际测试发现,阿里云下载下来的模型容易出错,慎用。
模型下载下来以后,直接放在文件夹下面即可!
配置GPU
查看设备:
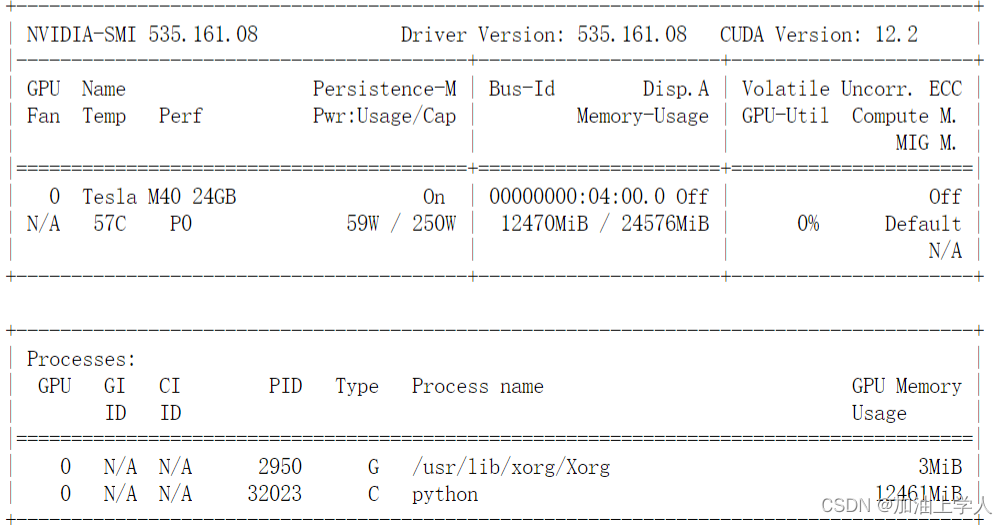
torch2.0以上需要CUDA12以上的支持,故安装一个比较高版本的CUDA即可解决问题,因为CUDA是向下兼容的,即CUDA12.2支持CUDA11.8,同时要选择合适的CUDNN,通常CUDA12.2对应的CUDNN为8.8.0以上。

检查GPU是否可用
import torch
torch.cuda.is_available()
开始本地测试
测试web
如果是在本地电脑上,可以不修改服务器的端口,负责要在lauch中修改server_name为0.0.0.0或所用电脑的ip。

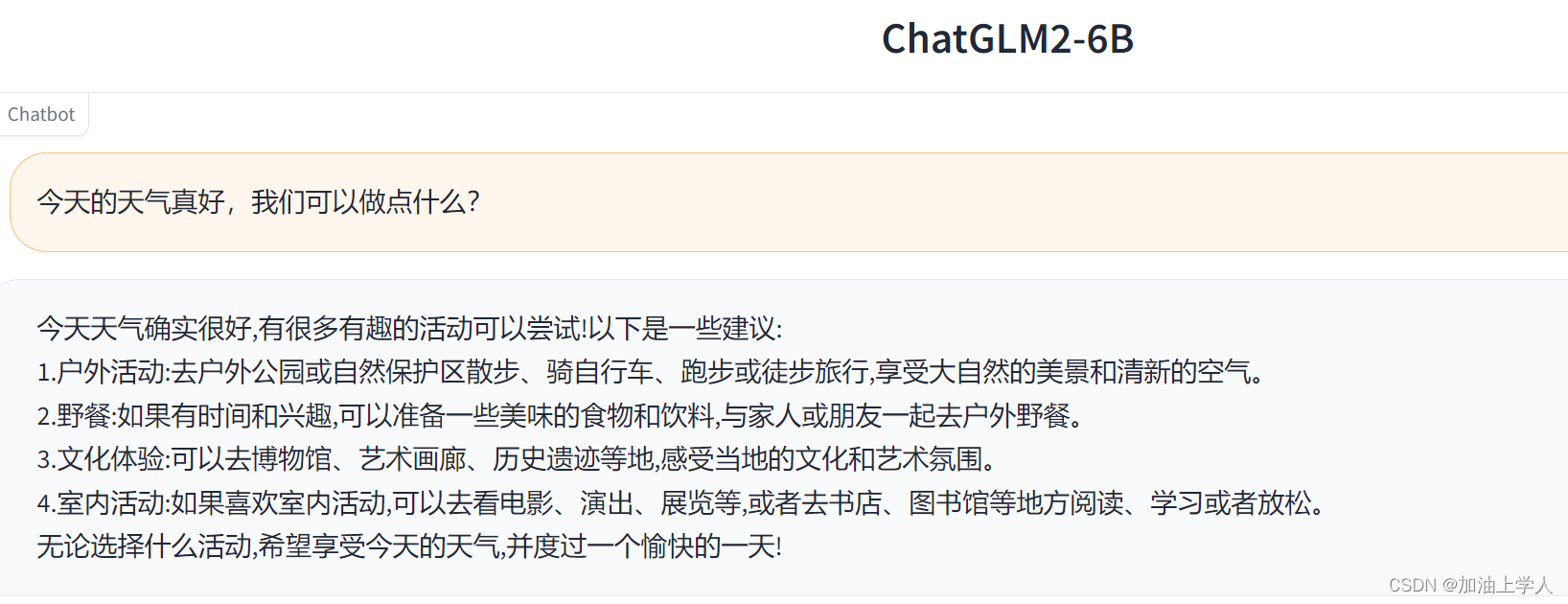
jupyter
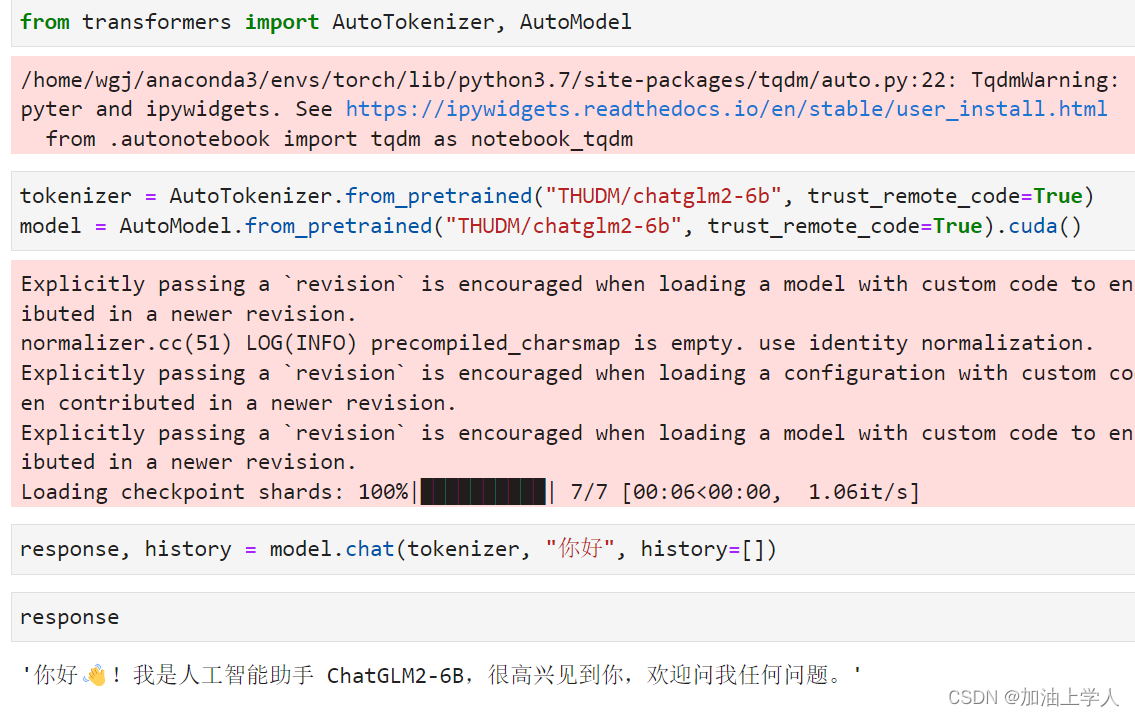
至此,本地部署完成。
后期将陆续更新:
如何将int4版本做修改让其跑起来;
如何基于peft做微调;
如何基于prompt做微调
这篇关于ChatGLM2-6b的本地部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









