本文主要是介绍ChatGLM2-6B微调过程说明文档,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考文档:
ChatGLM2-6B 微调(初体验) - 知乎
- 环境配置
下载anaconda,版本是Anaconda3-2023.03-0-Linux-x86_64.sh,其对应的python版本是3.10,试过3.7和3.11版本的在运行时都报错。
执行下面的命令安装anaconda
sh Anaconda3-2023.03-0-Linux-x86_64.sh
进入安装过程,根据提示输入即可,会自动配置好环境变量和pip等
下载代码
git clone GitHub - hiyouga/ChatGLM-Efficient-Tuning: Fine-tuning ChatGLM-6B with PEFT | 基于 PEFT 的高效 ChatGLM 微调
cd ChatGLM-Efficient-Tuning
如果服务器不能联网,可以在自己电脑上下载好,上传到服务器的对应目录
安装依赖
pip install -r requirements.txt
- 下载模型
从 Hugging Face Hub 下载模型实现和参数 到本地,后期使用 只需要 从本地下载即可。
git lfs install
git clone https://huggingface.co/THUDM/chatglm2-6b
- 知识产权数据集准备
通过ChatGPT生成问答预料文本
例如:
| prompt: 根据以下内容,生成10道简答题和答案,生成的答案需要详细,知识点完整: 在电影《天下无贼》中,演员刘德华和刘若英扮演的一对夫妇开着骗得的宝马轿车驶 入别墅区大门时,保安不但没有上前询问,反而立正敬礼。刘德华扮演的男主角将车倒回, 拍着宝马车问保安: “开好车你就不问,开好车就可以随便进入,开好车就一定是好人 吗?!”这个问题令人沉思。的确,观众们需要扪心自问:人们在追求以豪车、名表和名牌 服装等为象征的奢华生活和“面子”时,是否忽视了物质外壳之下的美丽灵魂?然而,电 影中的这一幕揭示了一个现实,如 “宝马”这样的驰名商标彰显了拥有者的身份与地位, 满足了消费者的心理需求,其作用有别于普通商标。与之相适应,商标法对驰名商标提供 了特别保护。 驰名商标是指经过长期使用或大量商业推广与宣传,在市场上享有很高知名度并为相 关公众所熟知的商标。与普通商标相比,驰名商标具有以下几个特点。 首先,驰名商标在相关公众中具有很高的知名度。 |
将返回的数据整理成md文档,如下图


每个章节生成的问题和回答数据达到5w字以上,全部生成完成之后,将文本内容处理成json格式,python代码如下:
| import json
|
结果文档如下:

- ChatGLM2-6B模型微调
命令行训练
| CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \ --stage sft \ --model_name_or_path /home/liq/zw/chatglm2/chatglm2-6b \ --do_train \ --dataset zscq \ --dataset_dir ./data \ --finetuning_type lora \ --output_dir /home/liq/zw/data/chatglm2-6b-lora-zscq \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 1 \ --lr_scheduler_type cosine \ --logging_steps 10 \ --save_steps 1000 \ --learning_rate 5e-5 \ --num_train_epochs 3.0 \ --fp16 |
开始训练
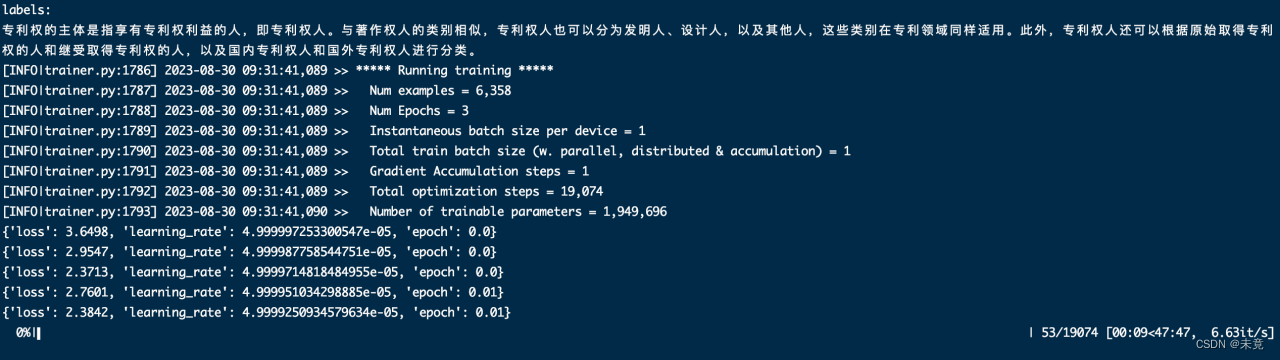
训练完成

命令行测试
| python src/cli_demo.py \ --model_name_or_path /home/liq/zw/chatglm2/chatglm2-6b \ --checkpoint_dir /home/liq/zw/data/chatglm2-6b-lora-zscq/checkpoint-19000 \ --quantization_bit 4 |
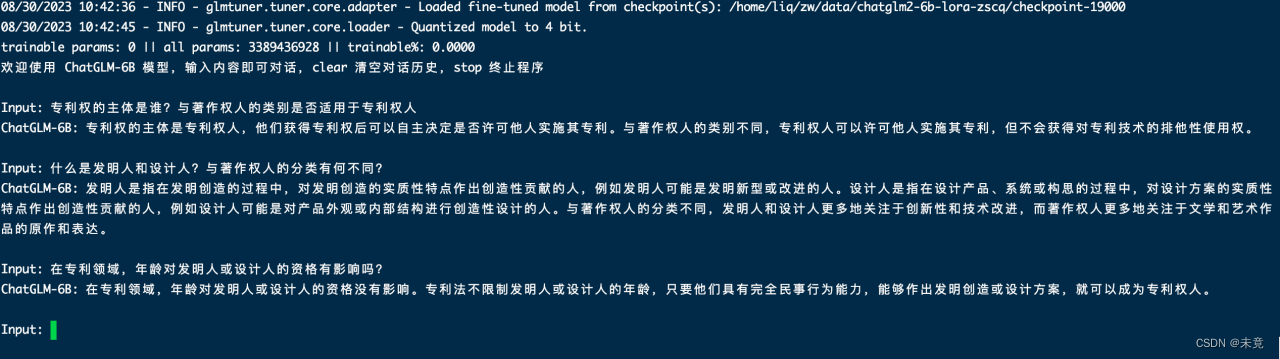
进入问答界面

输入问题,得到对应回答
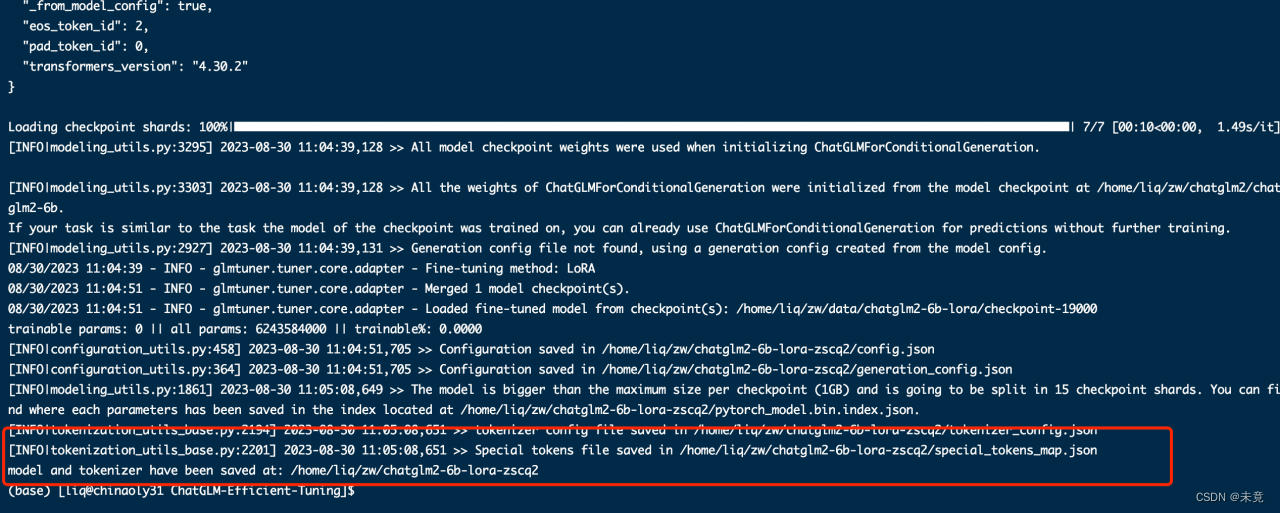
导出微调模型
| python src/export_model.py \ --model_name_or_path /home/liq/zw/chatglm2/chatglm2-6b \ --checkpoint_dir /home/liq/zw/data/chatglm2-6b-lora/checkpoint-19000 \ --output_dir /home/liq/zw/chatglm2-6b-lora-zscq2 |
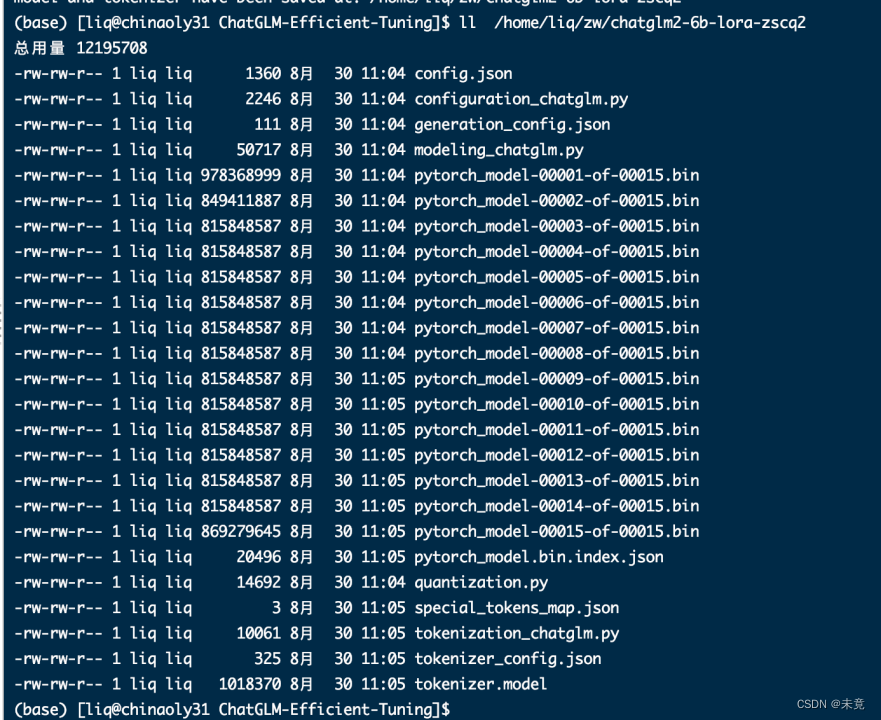
查看模型内容
这篇关于ChatGLM2-6B微调过程说明文档的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





