本文主要是介绍【fastllm】学习框架,本地运行,速度还可以,可以成功运行chatglm2模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1,关于 fastllm 项目
https://www.bilibili.com/video/BV1fx421k7Mz/?vd_source=4b290247452adda4e56d84b659b0c8a2
【fastllm】学习框架,本地运行,速度还可以,可以成功运行chatglm2模型
https://github.com/ztxz16/fastllm
🚀 纯c++实现,便于跨平台移植,可以在安卓上直接编译
🚀 ARM平台支持NEON指令集加速,X86平台支持AVX指令集加速,NVIDIA平台支持CUDA加速,各个平台速度都很快就是了
🚀 支持浮点模型(FP32), 半精度模型(FP16), 量化模型(INT8, INT4) 加速
🚀 支持多卡部署,支持GPU + CPU混合部署
🚀 支持Batch速度优化
🚀 支持并发计算时动态拼Batch
🚀 支持流式输出,很方便实现打字机效果
🚀 支持python调用
🚀 前后端分离设计,便于支持新的计算设备
🚀 目前支持ChatGLM系列模型,各种LLAMA模型(ALPACA, VICUNA等),BAICHUAN模型,QWEN模型,MOSS模型,MINICPM模型等
2,本地CPU编译也非常方便
git clone https://github.com/ztxz16/fastllm.gitcd fastllm
mkdir build
cd build
cmake .. -DUSE_CUDA=OFF
make -j
3,运行webui 可以进行交互问答
文件下载:
https://hf-mirror.com/huangyuyang/chatglm2-6b-int4.flm
./webui -p /data/home/test/hf_cache/chatglm2-6b-int4.flm
Load (200 / 200)
Warmup…
finish.
please open http://127.0.0.1:8081
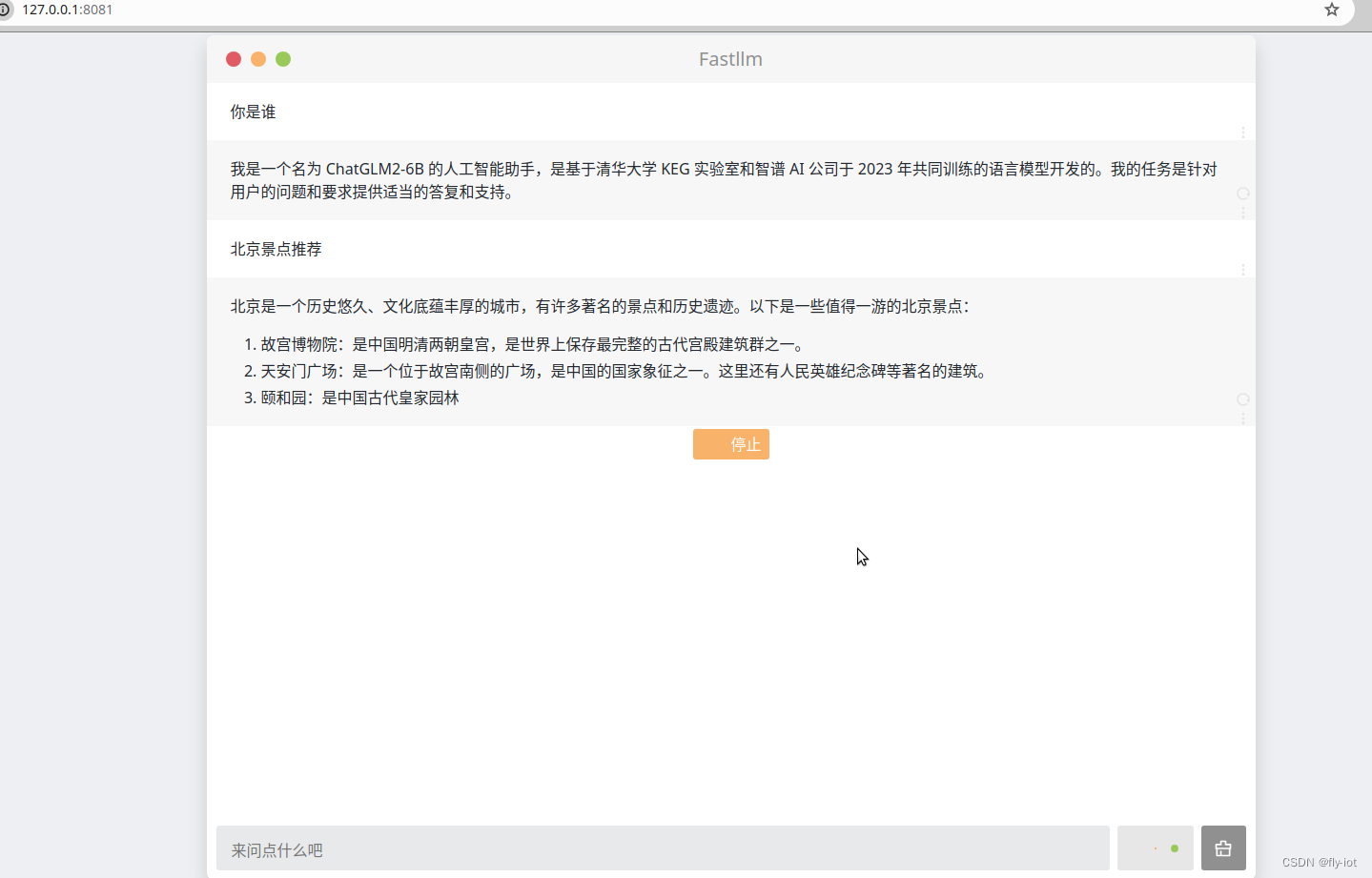
也有打字效果,不知道是咋实现的。好像不是stream 方式的。
3,速度还可以,同时也支持其他的模型
文档地址:
https://github.com/ztxz16/fastllm/blob/master/docs/llama_cookbook.md
LLaMA 类模型转换参考
这个文档提供了了转换LLaMA同结构模型的方法。
LLaMA类模型有着基本相同的结构,但权重和prompt构造有差异。在fastllm中,通过转转模型时修改部分配置,实现对这些变体模型的支持、
声明
以下配置方案根据模型的源代码整理,不保证模型推理结果与原版完全一致。
修改方式
目前,转换脚本和两行加速方式均可用于llama类模型。但无论采用哪一种方式,都需要预留足够的内存(可以用swap空间)。
在float16模式下,转换时约需要4×参数量+1GB的空闲内存。
转换脚本
这里以支持推理各类Llama结构的基座模型为例,介绍如何应用本文档。
- 方案一:修改转换脚本
以alpaca2flm.py为模板修改。在创建model之后添加:
model = LlamaForCausalLM.from_pretrained(model_name).float()# config.json中定义了自己的model_type的需要添加conf = model.config.__dict__conf["model_type"] = "llama"# 接下来的部分各个Chat模型有差别,Base模型有的需要添加pre_prompt。torch2flm.tofile(exportPath, model, tokenizer, pre_prompt = "", user_role = "", bot_role = "", history_sep = "", dtype = dtype)
其中,pre_prompt 、user_role 、bot_role 、history_sep分别为“开始的系统提示词(第一轮对话之前)”,“用户角色标志”,“用户话语结束标志及模型回复开始标志”,“两轮对话之间的分隔符”。
- 方案二:修改config.json
在下载的模型目录下,修改配置文件config.json中,修改"model_type"为llama,并增加下面的键-值对:
"pre_prompt": "","user_role": "","bot_role": "","history_sep": "",
如需添加Token ID而非字符串(类似baichuan-chat模型),可以使用“<FLM_FIX_TOKEN_{ID}>”的格式添加。
- 执行脚本
python3 tools/alpaca2flm.py [输出文件名] [精度] [原始模型名称或路径]
对齐tokenizer
如果想使fastllm模型和原版transformers模型基本一致,最主要的操作是对齐tokenizer。
如果模型使用了huggingface 加速版本的Tokenizers(即模型目录中包含tokenizer.json并优先使用),目前的转换脚本仅在从本地文件转换时,能够对齐tokenizer。
注意检查原始tokenizer的encode()方法返回的结果前面是否会加空格。如果原始tokenizer没有加空格,则需要设置:
conf["tokenizer_add_dummy_prefix"] = False
Base Model
一部分模型需要制定bos_token_id,假设bos_token_id为1则可以配置如下:
torch2flm.tofile(exportPath, model, tokenizer, pre_prompt = "<FLM_FIX_TOKEN_1>", user_role = "", bot_role = "", history_sep = "", dtype = dtype)
Chat Model
对Chat Model,同样是修改转换脚本,或修改模型的config.json,以下是目前常见的chat model的配置:
InternLM(书生)
- internlm/internlm-chat-7b
- internlm/internlm-chat-7b v1.1
- internlm/internlm-chat-20b
conf = model.config.__dict__conf["model_type"] = "llama"torch2flm.tofile(exportPath, model, tokenizer, pre_prompt = "<s><s>", user_role = "<|User|>:", bot_role = "<eoh>\n<|Bot|>:", history_sep = "<eoa>\n<s>", dtype = dtype)
可以直接使用llamalike2flm.py脚本转换:
cd build
python3 tools/llamalike2flm.py internlm-7b-fp16.flm float16 internlm/internlm-chat-20b #导出float16模型
python3 tools/llamalike2flm.py internlm-7b-int8.flm int8 internlm/internlm-chat-20b #导出int8模型
python3 tools/llamalike2flm.py internlm-7b-int4.flm int4 internlm/internlm-chat-20b #导出int4模型
python3 tools/llamalike2flm.py internlm-7b-int4.flm float16 internlm/internlm-chat-7b #导出internlm-chat-7b float16模型
XVERSE
- xverse/XVERSE-13B-Chat
- xverse/XVERSE-7B-Chat
conf = model.config.__dict__conf["model_type"] = "llama"conf["tokenizer_add_dummy_prefix"] = Falsetorch2flm.tofile(exportPath, model, tokenizer, pre_prompt = "", user_role = "Human: ", bot_role = "\n\nAssistant: ", history_sep = "<FLM_FIX_TOKEN_3>", dtype = dtype)
XVERSE-13B-Chat V1 版本需要对输入做NFKC规范化,fastllm暂不支持,因此需要使用原始tokenizer.
- xverse/XVERSE-13B-256K
该模型没有将RoPE外推参数放到config中,因此需要手工指定:
conf = model.config.__dict__conf["model_type"] = "llama"conf["rope_theta"] = 500000conf["rope_scaling.type"] = "dynamic"conf["rope_scaling.factor"] = 2.0conf["tokenizer_add_dummy_prefix"] = Falsetorch2flm.tofile(exportPath, model, tokenizer, pre_prompt = "", user_role = "Human: ", bot_role = "\n\nAssistant: ", history_sep = "<FLM_FIX_TOKEN_3>", dtype = dtype)
其他 llama1 系列
- Vicuna v1.1 v1.3
torch2flm.tofile(exportPath, model, tokenizer, pre_prompt="A chat between a curious user and an artificial intelligence assistant. ""The assistant gives helpful, detailed, and polite answers to the user's questions. "user_role="USER: ", bot_role=" ASSISTANT:", history_sep="<s>", dtype=dtype)
- BiLLa
torch2flm.tofile(exportPath, model, tokenizer, pre_prompt = "\n", user_role = "Human: ", bot_role = "\nAssistant: ", history_sep = "\n", dtype = dtype)
llama2-chat
- meta-llama/Llama-2-chat
| Model | Llama2-chat | Llama2-chat-hf |
|---|---|---|
| 7B | meta-llama/Llama-2-7b-chat | meta-llama/Llama-2-7b-chat-hf |
| 13B | meta-llama/Llama-2-13b-chat | meta-llama/Llama-2-13b-chat-hf |
| Model | CodeLlama-Instruct |
|---|---|
| 7B | codellama/CodeLlama-7b-Instruct-hf |
| 13B | codellama/CodeLlama-13b-Instruct-hf |
官方示例代码中,可以不用系统提示语:
torch2flm.tofile(exportPath, model, tokenizer, pre_prompt = "<FLM_FIX_TOKEN_1>", user_role = "[INST] ", bot_role = " [/INST]", history_sep = " <FLM_FIX_TOKEN_2><FLM_FIX_TOKEN_1>", dtype = dtype)
Llama-2系列支持系统提示语需要修改代码,单轮可以使用以下带有系统提示语的版本:
torch2flm.tofile(exportPath, model, tokenizer, pre_prompt = "<FLM_FIX_TOKEN_1>[INST] <<SYS>>\nYou are a helpful, respectful and honest assistant. Always answer as helpfully as possible, " \"while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. " \"Please ensure that your responses are socially unbiased and positive in nature.\n\nIf a question does not make any sense, " \"or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, " \"please don't share false information.\n<</SYS>>\n\n", user_role = " ", bot_role = " [/INST]", history_sep = " <FLM_FIX_TOKEN_2><FLM_FIX_TOKEN_1>", dtype = dtype)
- ymcui/Chinese-Alpaca-2
| Model | Chinese-Alpaca-2 | Chinese-Alpaca-2-16K |
|---|---|---|
| 7B | ziqingyang/chinese-alpaca-2-7b | ziqingyang/chinese-alpaca-2-7b-16k |
| 13B | ziqingyang/chinese-alpaca-2-13b | ziqingyang/chinese-alpaca-2-13b-16k |
torch2flm.tofile(exportPath, model, tokenizer, pre_prompt = "<FLM_FIX_TOKEN_1>[INST] <<SYS>>\nYou are a helpful assistant. 你是一个乐于助人的助手。\n<</SYS>>\n\n"user_role = " ", bot_role = " [/INST]", history_sep = " <FLM_FIX_TOKEN_2><FLM_FIX_TOKEN_1>", dtype = dtype)
RUC-GSAI/YuLan-Chat
- Full
- YuLan-Chat-2-13B
- Delta (需要原始LLaMA)
- YuLan-Chat-1-65B-v2
- YuLan-Chat-1-65B-v1
- YuLan-Chat-1-13B-v1
torch2flm.tofile(exportPath, model, tokenizer, pre_prompt="The following is a conversation between a human and an AI assistant namely YuLan, developed by GSAI, Renmin University of China. " \"The AI assistant gives helpful, detailed, and polite answers to the user's questions.\n",user_role="[|Human|]:", bot_role="\n[|AI|]:", history_sep="\n", dtype=dtype)
WizardCoder
- WizardCoder-Python-7B-V1.0
- WizardCoder-Python-13B-V1.0
torch2flm.tofile(exportPath, model, tokenizer, pre_prompt="Below is an instruction that describes a task. " \"Write a response that appropriately completes the request.\n\n",user_role="### Instruction:\n", bot_role="\n\n### Response:", history_sep="\n", dtype=dtype)
Deepseek Coder
- Deepseek-Coder-1.3B-Instruct
- Deepseek-Coder-6.7B-Instruct
- Deepseek-Coder-7B-Instruct v1.5
torch2flm.tofile(exportPath, model, tokenizer, pre_prompt="<FLM_FIX_TOKEN_32013> You are an AI programming assistant, utilizing the Deepseek Coder model, developed by Deepseek Company, " \"and you only answer questions related to computer science. For politically sensitive questions, security and privacy issues, " \"and other non-computer science questions, you will refuse to answer.\n",user_role="### Instruction:\n", bot_role="\n### Response:\n", history_sep="\n<|EOT|>\n", dtype=dtype)
这篇关于【fastllm】学习框架,本地运行,速度还可以,可以成功运行chatglm2模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






