本文主要是介绍论文研读 Automatic TCP Buffer Tuning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于“动态右尺寸”(DRS)的方法关于其自动调优方法的介绍并不清楚,改读了论文"Automatic TCP Buffer Tuning"。其中调节接收缓存大小的想法就是,“动态调整接收套接字缓冲区的一个想法是在缓冲区大部分为空时增加缓冲区大小,因为缺少排队等待应用程序传输的数据表明数据速率低,这可能是接收窗口限制连接的结果。在恢复期间达到峰值使用量(由丢失的数据包指示),因此,如果缓冲区大小远大于恢复期间所需的空间,则可以减少缓冲区大小。如果低数据速率不是由较小的接收窗口引起的,而是由缓慢的瓶颈链路引起的,则缓冲区大小在检测到数据包丢失时仍将自行校准。这个想法的灵感来自与Greg Minshall [Min97]的讨论,需要进一步研究。”
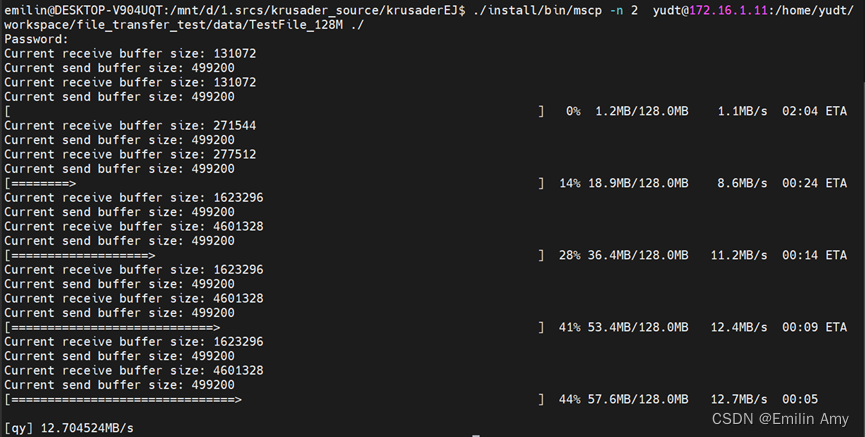
(1) 从论文[1]读到“如果应用程序手动使用 setsockopt() 设置接收缓冲区或发送缓冲区大小,该连接的自动调整将关闭”后,注释掉setsockopt()的部分后,可以明显看到系统的自动调优功能在起作用。
(2) 另外一篇论文[3]还提到“Linux 自动调优是指稳定版 Linux 内核 2.4 版中使用的内存管理技术。此技术不会尝试对连接的带宽延迟乘积进行任何估计。相反,它只是根据可用的系统内存和可用的插槽缓冲区空间来增加和减少缓冲区大小。通过在充满数据时增加缓冲区大小,TCP连接可以增加其窗口大小 - 性能改进是有意的副作用。
论文研读
[1] A Comparison of TCP Automatic Tuning Techniques for Distributed Computing
[2] Dynamic Right-Sizing: A Simulation Study
[3] Automatic TCP Buffer Tuning
这篇关于论文研读 Automatic TCP Buffer Tuning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






