buffer专题

Go 1.23中Timer无buffer的实现方式详解
《Go1.23中Timer无buffer的实现方式详解》在Go1.23中,Timer的实现通常是通过time包提供的time.Timer类型来实现的,本文主要介绍了Go1.23中Timer无buff... 目录Timer 的基本实现无缓冲区的实现自定义无缓冲 Timer 实现更复杂的 Timer 实现总结在

Go语言使用Buffer实现高性能处理字节和字符
《Go语言使用Buffer实现高性能处理字节和字符》在Go中,bytes.Buffer是一个非常高效的类型,用于处理字节数据的读写操作,本文将详细介绍一下如何使用Buffer实现高性能处理字节和... 目录1. bytes.Buffer 的基本用法1.1. 创建和初始化 Buffer1.2. 使用 Writ

Java 文件读写最好是用buffer对于大文件可以加快速度
参考例子: FileReader fileReader = new FileReader(filename);BufferedReader bufferedReader = new BufferedReader(fileReader);List<String> lines = new ArrayList<String>();String line = null;while ((line =
【Node】Buffer 与 Stream
node 为什么会出现 Buffer 这个模块 在最初的时候,JavaScript 只运行在浏览器端, 对于处理 Unicode 编码的字符串很容易,但是对于处理二进制以及非 Unicode 编码的数据便无能为力。 不过对于 Server 端操作来说 网络I/O 以及 文件I/O 的处理是必须的,所以 Node 中便提供了 Buffer 类处理二进制的数据。 二进制缓冲区 Buffer

【0324】Postgres内核 Shared Buffer Access Rules (共享缓冲区访问规则)说明
0. 章节内容 1. 共享磁盘缓冲区访问机制 (shared disk buffers) 共享磁盘缓冲区有两套独立的访问控制机制:引用计数(a/k/a pin 计数)和缓冲区内容锁。(实际上,还有第三级访问控制:在访问任何属于某个关系表的页面之前,必须持有该关系表的适当类型的锁。这里不讨论关系级锁。) Pins 在对缓冲区做任何操作之前,必须“对缓冲区pin”(即增加其引用计数, re
Netty源码解析1-Buffer
大数据成神之路系列: 请戳GitHub原文: https://github.com/wangzhiwubigdata/God-Of-BigData 上一篇文章我们概要介绍了Netty的原理及结构,下面几篇文章我们开始对Netty的各个模块进行比较详细的分析。Netty的结构最底层是buffer机制,这部分也相对独立,我们就先从buffer讲起。 What:buffer简介 buffer中文
【LINUX】“dmesg: read kernel buffer failed: Operation not permitted“ 错误
出现 “dmesg: read kernel buffer failed: Operation not permitted” 错误通常是因为当前用户没有权限读取内核日志缓冲区 这可以通过修改内核参数 kernel.dmesg_restrict 来解决。 你可以尝试以下命令来允许非特权用户读取内核日志: sudo sysctl -w kernel.dmesg_restrict=0 这个命令

Kafka【五】Buffer Cache (缓冲区缓存)、Page Cache (页缓存)和零拷贝技术
【1】Buffer Cache (缓冲区缓存) 在Linux操作系统中,Buffer Cache(缓冲区缓存)是内核用来优化对块设备(如磁盘)读写操作的一种机制(故而有一种说法叫做块缓存)。尽管在较新的Linux内核版本中,Buffer Cache和Page Cache已经被整合在一起,但在理解历史背景和功能时,了解Buffer Cache仍然很有帮助。 Buffer Cache 的历史和定义

浅谈Buffer I/O 和 Direct I/O
通常来说,文件I/O可以分为两种: Buffer I/ODirect I/O Buffer I/O 缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。 在 Linux 的缓存 I/O 机制中,这种访问文件的方式是通过两个系统调用实现的:read() 和 write()。调用read()时,如果 操作系统内核地址空间的页缓存( page cache )

OBCE 第三章实验 内存管理手动实践 深入了解Queuing(buffer)表
实验环境:oceanbase 企业版V3 1-1-1 架构。 1.查看当前资源情况 select unit_config_id,name,max_cpu,min_cpu,round(max_memory/1024/1024/1024) max_mem_gb, round(min_memory/1024/1024/1024) min_mem_gb, round(max_disk_siz

Linux内存、Swap、Cache、Buffer详细解析
点击上方“朱小厮的博客”,选择“设为星标” 后台回复"书",获取 后台回复“k8s”,可领取k8s资料 来源:r6d.cn/abK6G 1. 通过free命令看Linux内存 total:总内存大小。 used:已经使用的内存大小(这里面包含cached和buffers和shared部分)。 free:空闲的内存大小。 shared:进程间共享内存(一般不会用,可以忽略)。 buffers:

标准库标头 <memory_resource> (C++17)学习之monotonic_buffer_resource
类 std::pmr::monotonic_buffer_resource 是特定目的的内存资源类,它仅在销毁资源时释放分配的内存。它的意图是提供非常快速的内存分配,在内存用于分配少量对象,并于之后一次释放的情形。monotonic_buffer_resource 能以初始缓冲区构造,若无初始缓冲,或缓冲用尽,则从构造时提供的上游分配器分配缓冲区。缓冲区的大小以几何级数增长。monotonic_b
缓冲区与缓存(buffer与cache)
文章目录 缓冲区与缓存(buffer与cache)1.缓冲区buffer缓存区的作用Python中的缓冲缓存区的类型 2.缓存cache缓存的适用场景缓存的三种模式Python中的缓存 缓冲区与缓存(buffer与cache) 1.缓冲区buffer 缓冲区(buffer),它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数
快速上手 iOS Protocol Buffer
快速上手 iOS Protocol Buffer | 来自缤纷多彩的灰 本文主要介绍在 iOS 开发中如何快速上手使用 Protobuf。更多关于 Protobuf 的介绍和相关的功能 api,读者可自行查阅官网。 Protocol Buffer(简称 Protobuf)是一种由Google开发的语言中立、平台无关的序列化数据结构的方法。它允许你定义结构化的数据,并提供一种高效且灵活的方式进行

精通 Node.js 4.x 核心技术之 Buffer【讲师辅导】-曾亮-专题视频课程
精通 Node.js 4.x 核心技术之 Buffer【讲师辅导】—5225人已学习 课程介绍 【会员免费】链接 http://edu.csdn.net/lecturer/585 右侧办理会员卡。办会员卡可咨询 QQ 1405491181 。 会员可免费学习已发布的全部课程,和在会员有效期内讲师新发布的全部课程 ,承诺每个月至少增加价值500元+ 的新课程。这是一套
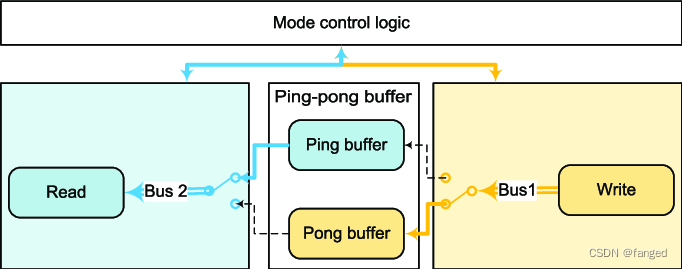
音视频的Buffer处理
最近在做安卓下UVC的一个案子。正好之前搞过ST方案的开机广告,这个也是我少数最后没搞成功的项目。当时也有点客观原因,当时ST要退出机顶盒市场,所以一切的支持都停了,当时啃他家播放器几十万行的代码,而且几乎没有文档,真的是非常痛苦。后面虽然功能是搞出来了,但是不稳定,持续几次后就会crash。 还记得当时最后到底层ST是用的滑动窗口缓存,双指针,一个写指针和一个读指针,当时我做了一个管道往缓存中

【C语言】解决C语言报错:Buffer Overflow
文章目录 简介什么是Buffer OverflowBuffer Overflow的常见原因如何检测和调试Buffer Overflow解决Buffer Overflow的最佳实践详细实例解析示例1:字符串操作不当示例2:数组访问越界示例3:未检查输入长度示例4:使用不安全的函数 进一步阅读和参考资料总结 简介 Buffer Overflow(缓冲区溢出)是C语言中常见
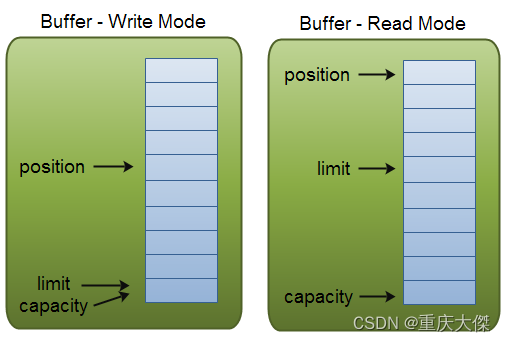
JAVA NIO(二) Buffer和Channel
一,基本使用 1, 一个Socket连接使用一个Channel来表示,以前直接操作Socket文件描述符来对读写缓冲区操作,比如读数据到用户空间的一个byte数组,NIO中Channel对这个过程作了封装,其中用户空间的byte数组就类比Buffer。 2,Buffer用于和Channel进行交互。 Channel中的数据总是要先写入到Buffer,或从Buffer读取;
python write出现 Non-character array cannot be interpreted as character buffer.
比如z是一个数字 out.wirte(z)报错 那么out.wirte(str(z))

《超实用的Node.js代码段》连载一:获取Buffer对象字节长度
我们知道Node.js框架下的Buffer对象能够对二进制数据提供很好的支持,那么获取一个Buffer对象真实的字节长度则是必须要用到的功能了。Node.js框架为开发人员提供了一个Buffer.byteLength()方法,下面我们借助一个官方文档提供的例程向读者演示一下该方法的使用过程。 本例ch04.buffer-byteLength.js主要代码如下: 01 /**02 * ch
内存中的buffer和cache
一、buffer和cache是内存的一部分即占用了内存的空间 提到查看linux主机内存,我们总会想到free命令也一般用该命令,如下面的输出: [root@localhost ~]# freetotal used free shared buff/cache availableMem: 3861292 283220

strcpy_s Buffer is too small 出错根本原因
从字面意思就知道,要拷贝的目的空间太小。 只是对于这个拷贝的来源要心里有数才知道要改哪里。 今天我的程序在下午3点多写数据库的时候出现了这个提示,我之前有碰到过所以知道怎么修改。恩,不知道的google ,百度等都是正确的解决办法。改完之后程序写了一条记录到数据库中。很完美了,不是吗? 但是,我的程序就启动不起来了。我第一感觉就是刚才改动的地方有点多,不知道改到什么地方了。查
boost库asio详解7——boost::asio::buffer用法
1. asio::buffer常用的构造方法 asio::buffer有多种的构造方法,而且buffer大小是自动管理的 1.1 字符数组 [cpp] view plain copy print ? char d1[128]; size_t bytes_transferred = socket.receive(boost::asio::buffer(d1));
阻塞I/O的缓冲区(Buffer)
如果将同步I/O方式下的数据传输比做数据传输的零星方式(这里的零星是指在数据传输的过程中是以零星的字节方式进行的),那么就可以将非阻塞I/O方式下的数据传输比做数据传输的集装箱方式(在字节和低层数据传输之间,多了一层缓冲区,因此,可以将缓冲区看做是装载字节的集装箱)。大家可以想象,如果我们要运送比较少的货物,用集装箱好象有点不太合算,而如果要运送上百吨的货物,用集装箱来运送的成本会更低。在数据传
环形buffer单生产单消费队列
环形缓冲区由一个固定大小的数组构成,生产者将数据写入缓冲区的尾部,而消费者则从缓冲区的头部读取数据,当缓冲区被填满时,生产者会等待,直到有空间可用;当缓冲区为空时,消费者会等待,直到有数据可用 使用两个循环指针用来实现环形队列,头指针和尾指针在队列为空的时候是相同的,起始为0,当头指针快追上尾指针的时候代表队列已满,也就是head=tail-1的时候,这意味着我们使用了一个元素的位置来表示队列是
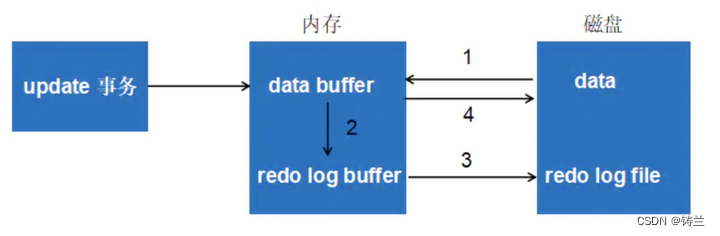
MYSQL部分术语及原理解释(缓冲池、LRU、redo log buffer、WAL、Checkpoint、LSN)
文章目录 一、缓冲池 Buffer Pool二、 LRU List、Free List、Flush List三、 重做日志缓存redo log buffer四、WAL与Checkpoint五、LSN 总结来自《MySQL技术内幕 InnoDB存储引擎》 第二版 一、缓冲池 Buffer Pool InnoDB存储引擎的MySQL是基于磁盘的数据库系统。缓冲池是一片内存区域,在